11.2.4 言語モデルの基礎
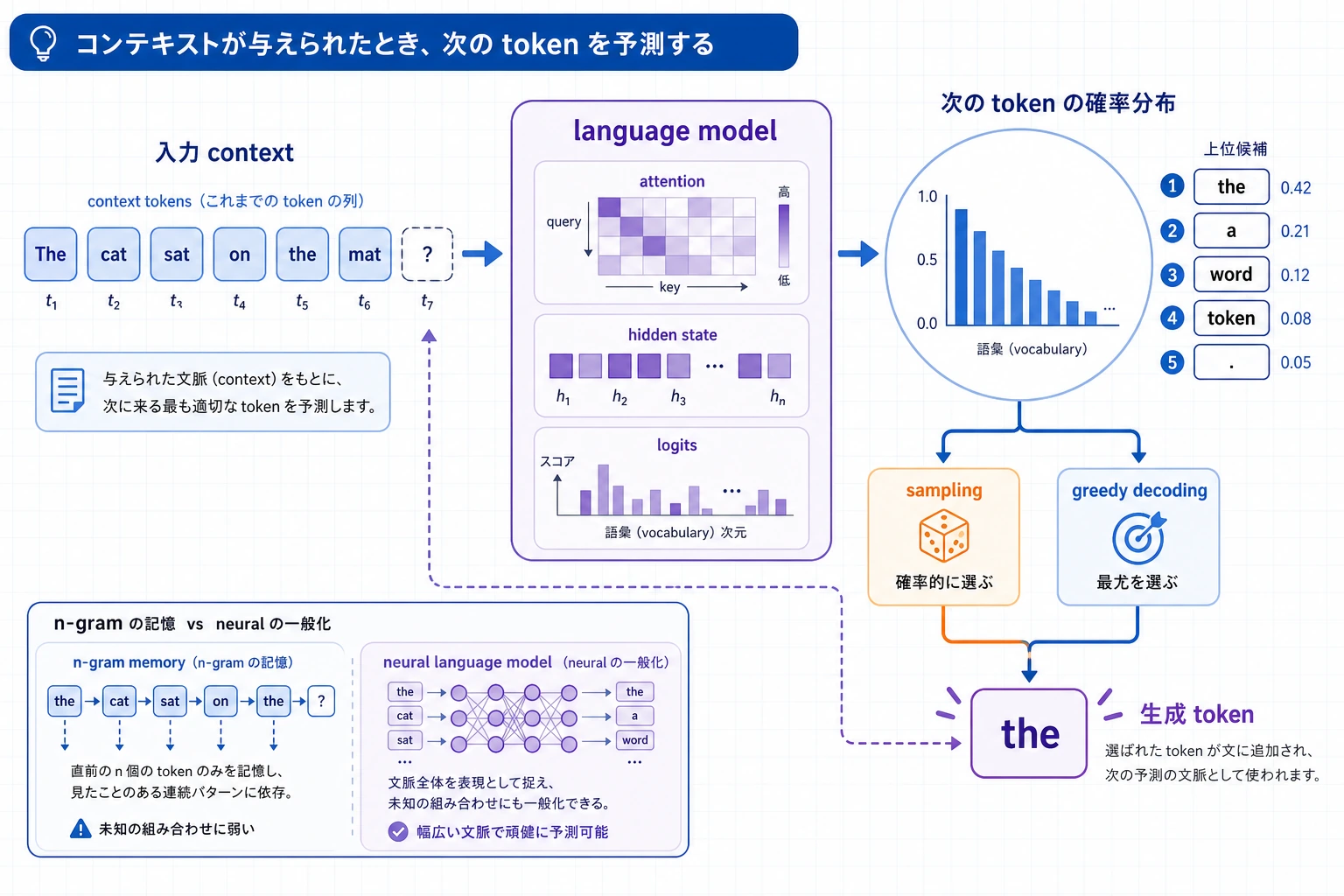
言語モデルを「しりとり」のようなものだとだけ考えないでください。図を見るときは、前後の文脈、候補 token の確率分布、そしてサンプリング/選択の関係に注目しましょう。大規模モデルの多くの生成能力は、この学習目標から発展しています。
「言語モデル」という言葉は、この先何度も出てきます。
ここで最も基本的な感覚をつかんでおかないと、後で大規模モデルを学ぶときに、流行語だけが残ってしまいがちです。
このレッスンの目標は、まず次の1点をはっきりさせることです。
言語モデルの本質は、前のテキストが与えられたときに、次に何が最も起こりやすいかを予測することです。
表面上はシンプルなタスクに見えますが、後の多くの能力はここから育っていきます。
学習目標
- 言語モデルの最も基本的なタスク目標を理解する
- n-gram 言語モデルと現代のニューラル言語モデルの連続性を理解する
- 実行可能な例を通して「次の token を予測する」感覚をつかむ
- なぜ言語モデルが後の大規模モデルの共通基盤になるのかを理解する
一、言語モデルは何を学んでいるのか?
最も基本的な形
一言でいうと、こうです。
- 前文が与えられたとき、次の token を予測する
たとえば:
- 「私は AI」-> 次の単語は
が、を、好きなどの可能性があります
このタスクはなぜ、シンプルそうなのに強いのか?
これをうまくやるには、モデルが少しずつ次のようなものを学ぶ必要があるからです。
- 語の組み合わせ
- 文法構造
- よくある意味の関係
- ある程度の世界知識
つまり、
「次の token を予測する」という目標はシンプルに見えて、
実はモデルにたくさんの言語の規則を学ばせます。
たとえ話
言語モデルは「しりとり」をしているようなものです。
ただし、適当に続けるのではなく、次のように自然に続ける必要があります。
- 人間の言語らしく
- 今の文脈に合っていて
- 妥当な続きになっている
二、まずは n-gram の感覚から始めよう
n-gram 言語モデルとは?
まずは次のように理解するとよいです。
- 直前のごく短い履歴だけを見る
- その出現頻度を使って、次に何が来るかを予測する
たとえば bigram なら:
- 直前の1語だけを見る
trigram なら:
- 直前の2語だけを見る
この方法の良い点は?
- 直感的
- 説明しやすい
- 入門しやすい
限界もはっきりしている
- 長い依存関係を見られない
- データがまばらになりやすい
- 汎化能力が弱い
それでも、新しく学ぶ人が言語モデルの最初の感覚をつかむのにはとても向いています。
三、まずは bigram の例を動かしてみよう
from collections import defaultdict, Counter
corpus = [
"私 は AI が 好き",
"私 は Python が 好き",
"あなた は NLP が 好き",
]
stats = defaultdict(Counter)
for sent in corpus:
toks = sent.split()
for a, b in zip(toks[:-1], toks[1:]):
stats[a][b] += 1
print(dict(stats))
実行結果の例:
{'私': Counter({'は': 2}), 'は': Counter({'AI': 1, 'Python': 1, 'NLP': 1}), 'AI': Counter({'が': 1}), 'が': Counter({'好き': 3}), 'Python': Counter({'が': 1}), 'あなた': Counter({'は': 1}), 'NLP': Counter({'が': 1})}
これは小さな next-token 表です。私 の後には は が2回出ており、は の後には AI、Python、NLP がそれぞれ1回ずつ出ています。語順をスペースで区切っているのは、最小例として token を見やすくするためです。
このコードで最も大事な点は?
言語モデルのいちばん下のロジックを見えるようにしていることです。
- ある単語を見たら
- 訓練コーパスの中で、その次にどの単語が何回出たかを見る
なぜこれだけでも「言語モデル」に見えるのか?
それはすでに次のことをしているからです。
- 条件付き確率の推定
たとえば 愛 を見たあとに、
AIPythonNLP
がそれぞれ異なる確率で続く、という考え方です。
四、統計モデルからニューラル言語モデルへどう進むのか?
核心のタスクは変わらない
後になってモデルの構造はどんどん複雑になりますが、
重要な事実の1つは次のとおりです。
- 目的関数はしばしば「次の token を予測する」ままです
変わるのは表現方法と汎化の仕方
ニューラル言語モデルは、もはや頻度表を引くだけではありません。
代わりに、次のようなことをします。
- token をベクトルで表す
- ニューラルネットワークで文脈をモデル化する
これにより、次のことが可能になります。
- より長い履歴を見る
- より抽象的なパターンを学ぶ
- 見たことのない組み合わせにも、よりうまく一般化する
「予測分布」の簡略例
import math
scores = {
"AI": 2.0,
"Python": 1.5,
"NLP": 0.8,
}
def softmax(score_dict):
exps = {k: math.exp(v) for k, v in score_dict.items()}
total = sum(exps.values())
return {k: round(v / total, 4) for k, v in exps.items()}
print(softmax(scores))
実行結果の例:
{'AI': 0.5242, 'Python': 0.3179, 'NLP': 0.1579}
モデルはすぐに1語だけを選ぶ必要はありません。まず候補 token 全体の確率分布を出し、その後のデコード規則が選択、サンプリング、順位付けを行います。
これは完全なニューラルネットワークではありませんが、
すでに大事なことを表しています。
- モデルは1つの単語だけを出すのではない
- 「次の単語の確率分布」を出している
五、なぜ言語モデルは大規模モデルの共通基盤になるのか?
この目標はとても汎用的だから
後であなたがやりたいことが次のどれでも、
- 対話
- 文章作成
- コード生成
- 要約
多くの能力は「言語を続ける力」から育ちます。
大規模な自己教師あり学習と相性が良いから
「次の単語が何か」を人手でラベル付けする必要はありません。
テキストそのものが、自然にそのラベルを持っています。
そのため、
- 大量のテキスト
- 自己教師あり学習
を自然に組み合わせられます。
だから後で GPT の方向へ進む
自己回帰的な言語モデリングは、
- シンプル
- 統一的
- 拡張しやすい
この路線は、後に大規模言語モデルの重要な主流の1つになりました。
六、つまずきやすいポイント
誤解1:言語モデルは「次の単語を当てるだけ」
表面的にはその通りですが、
このタスクがモデルに学ばせるものを低く見積もってはいけません。
誤解2:n-gram は役に立たないから、学ぶ必要はない
n-gram はとても役に立ちます。
なぜなら、言語モデルが何をしているのかを最初に本当に見せてくれるからです。
誤解3:生成できれば、言語を理解していることになる
生成が上手でも、完全に理解しているとは限りません。
そのため後で、推論、アラインメント、ツール呼び出しも学ぶ必要があります。
まとめ
この節で最も大事なのは、次の安定した見方を身につけることです。
言語モデルの最も基本的なタスクは、前文が与えられたときに次の token を予測することです。そして、この一見シンプルな目標こそが、後の大規模モデルの多くの能力の土台になります。
この主線さえはっきりしていれば、
後で GPT、事前学習、生成モデルを見ても、ずっと自然に理解できます。
練習
- 自分でコーパスを数文追加して、
statsがどう変わるか見てみましょう。 - bigram はシンプルなのに、なぜ言語モデルの核心を捉えていると言えるのでしょうか?
- 自分の言葉で説明してみましょう。言語モデルはなぜ大規模な自己教師あり学習に向いているのでしょうか?
- 考えてみましょう。「次の単語を続ける」ことが、どうして対話や文章作成の能力につながるのでしょうか?