11.6.4 GPT シリーズ
BERT が「テキストを読み解くのが得意なモデル」だとしたら、GPT 系列はもっとこういうイメージです:
すでにある文脈をもとに、続きを少しずつ書き足していく。
この流れは後に発展し、今私たちがよく知る大規模言語モデルの主流になりました。
学習目標
- GPT の核心となる学習目標がなぜ「次の token を予測すること」なのかを理解する
- GPT と BERT の構造・タスク上の重要な違いを理解する
- causal mask がなぜ欠かせないのかを理解する
- 最小限の bigram 言語モデルで自己回帰生成を体験する
- GPT シリーズが「続きを書くモデル」から「対話アシスタント」へ進化した考え方を理解する
歴史的背景:GPT という流れはどう育ってきたのか?
GPT は、1つのモデルだけを見るよりも「シリーズの節目」として理解するほうが分かりやすいです。
| 年 | 節目 | 代表論文 | 最も重要に解決したこと |
|---|---|---|---|
| 2018 | GPT-1 | Improving Language Understanding by Generative Pre-Training | decoder-only の事前学習ルートを本格的に主流へ押し上げた |
| 2019 | GPT-2 | Language Models are Unsupervised Multitask Learners | より大規模なモデルで、強い生成能力と zero-shot の可能性を示した |
| 2020 | GPT-3 | Language Models are Few-Shot Learners | in-context learning / few-shot 現象を主流へ押し上げた |
初心者がまず覚えるべき一番大事なポイントは次です:
GPT は、最初から「会話ができる」ようになったのではなく、「次の token を予測する」という主流の上で、規模と能力をどんどん拡大してきた。
その後にみんなが知っている対話アシスタント、指示追従、Agent の能力は、この生成の流れの上にさらに発展してきたものです。
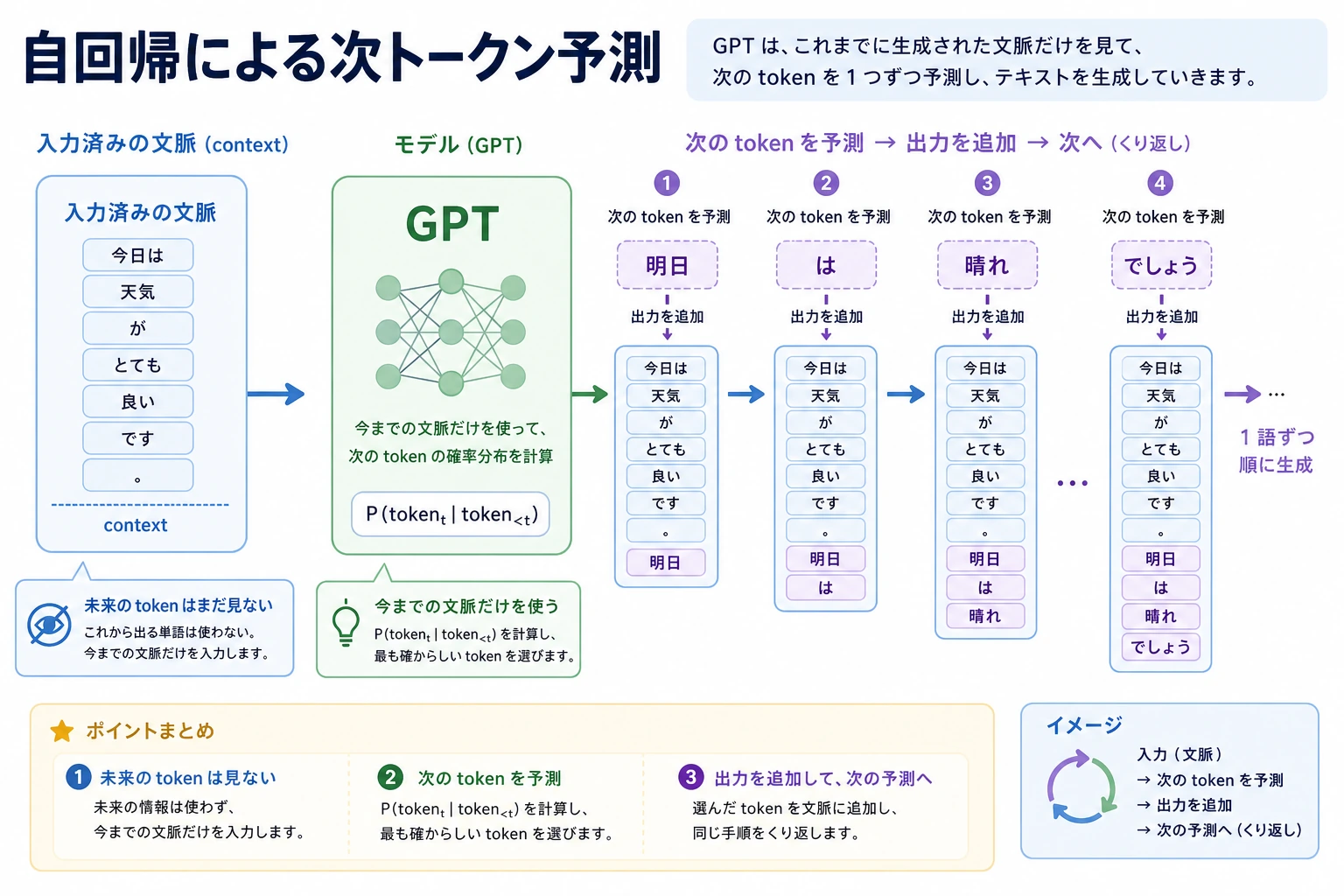
一、GPT は何をしているのか?
いちばん素朴な一言
GPT 系列の本質的な目的は次の通りです:
前の文脈を与えて、次の token を予測する。
たとえば、
入力:
「北京は中国の」
モデルは次を予測しやすくなります:
「首都」
とても単純に見えますが、これを何度も繰り返すと、
- 1 つ token を予測する
- それを文脈の後ろに付け足す
- また次の token を予測する
という流れで、文章を少しずつ生成できます。
なぜこのやり方が強いのか?
「次の token を予測する」という目標は、とても汎用的だからです。
- 言語の規則を学べる
- 知識のパターンを学べる
- コードの構造を学べる
- 推論の軌跡を学べる
だから GPT の強さは、最初から会話が得意だったからではなく、
大規模な言語生成の規則を先に学べた
ことにあります。
初学者向けのよりよい比喩
GPT は次のように考えると理解しやすいです。
- 前の文を読んで、その続きを自然に書ける人
ただし、最初から得意なのは次のようなことではありません。
- きわめて厳密な構造化理解問題
でも、次のようなことはとても得意です。
- 与えられた文脈をもとに、自然な続きを生成する
だから GPT 系列は自然に次の用途へ伸びていきました。
- 対話
- 文章作成
- コード補完
二、GPT と BERT の根本的な違い
まずは表で覚える
| モデル系統 | 基本の考え方 | 得意分野 |
|---|---|---|
| BERT | 文脈を双方向に見る | 理解、照合、抽出 |
| GPT | 左側の履歴だけを見る、自己回帰生成 | 続きの生成、対話、生成 |
なぜ GPT は右側を見てはいけないのか?
生成するときは、未来の内容はまだ存在しません。
そのため、学習時にも未来の token をこっそり見てはいけません。
これが causal / autoregressive の制約です。
三、因果マスク(causal mask)が GPT にとって重要な理由
直感的な理解
GPT では、モデルが t 番目の位置を予測しているとき、
1 ~ t-1は見てよいt+1以降は見てはいけない
これは穴埋め問題に似ています。
- すでに書かれた前の内容だけを見る
- 答え欄をこっそり見ない
最小の mask の例
import numpy as np
seq_len = 5
mask = np.tril(np.ones((seq_len, seq_len), dtype=int))
print(mask)
出力は下三角行列になります。
[[1 0 0 0 0]
[1 1 0 0 0]
[1 1 1 0 0]
[1 1 1 1 0]
[1 1 1 1 1]]
これは次を意味します。
- 1 番目の位置は自分だけ見られる
- 2 番目の位置は最初の 2 つが見られる
- 5 番目の位置は最初の 5 つが見られる
これが GPT の学習と生成の一致を支えています。
初学者がまず覚えやすい対比表
| 問題 | GPT の答え方 |
|---|---|
| 学習時に未来の token を見てもよい? | いいえ |
| 生成時に未来の token を見てもよい? | いいえ |
| なぜそうする? | 学習と生成を一致させるため |
この表は初心者にとても有効です。
「causal mask」という言葉を、ただの専門用語ではなく、
- 後ろの答えを見てはいけない
という素朴な制約として捉え直せるからです。
四、教育的に意味のある最小 GPT 例:bigram 言語モデル
なぜまず bigram を見るのか?
とても単純ですが、これだけで次のことを目で確認できます。
- 「前の語をもとに次の語を予測する」とは何か
- 「自己回帰生成」とは何か
実行可能な例
from collections import defaultdict, Counter
import random
random.seed(7)
corpus = [
"私 AI が 好き",
"私 Python が 好き",
"あなた AI が 好き",
"私たち は 学ぶ"
]
transitions = defaultdict(Counter)
for sentence in corpus:
tokens = sentence.split()
for a, b in zip(tokens[:-1], tokens[1:]):
transitions[a][b] += 1
def sample_next(token):
candidates = transitions[token]
if not candidates:
return None
words = list(candidates.keys())
weights = list(candidates.values())
return random.choices(words, weights=weights, k=1)[0]
def generate(start, max_steps=5):
tokens = [start]
current = start
for _ in range(max_steps):
nxt = sample_next(current)
if nxt is None:
break
tokens.append(nxt)
current = nxt
return " ".join(tokens)
for _ in range(5):
print(generate("私"))
想定出力:
私 AI が 好き
私 AI が 好き
私 AI が 好き
私 AI が 好き
私 AI が 好き
ここでは乱数シードを固定しているので、サンプリング結果を再現できます。大事なのは、どの語が選ばれたかそのものではなく、生成した語を文脈に戻し、更新された文脈から次の語をまたサンプリングするというループです。
このコードは何を教えているのか?
これは GPT の最小構造を教えています。
- 前の文脈から次の単語分布を決める
- その分布からサンプリングする
- その結果を文脈に戻して追加する
- さらに生成を続ける
これが「自己回帰生成」の最小原型です。
もちろん、本物の GPT はこれよりはるかに複雑ですが、主線は同じです。
GPT を最初に学ぶときの、いちばん安定した順番
次の順番が分かりやすいことが多いです。
- 「次の token を予測する」という一文を理解する
- causal mask がなぜ必要かを見る
- bigram のような最小モデルで自己回帰の感覚をつかむ
- 最後に GPT-1 / 2 / 3 の規模拡大を見る
この順番だと、最初からモデルのパラメータ数や公開年ばかり追うより、主線を理解しやすくなります。
五、GPT が decoder-only である理由
逐次生成が核心だから
GPT シリーズは通常、decoder-only Transformer をベースにしています。
- 各位置は左側だけを見る
- causal mask によって未来を見ない
- 毎ステップで次の token の分布を出す
これは encoder-only(たとえば BERT)との最大の違いです。
GPT の構造は、もともと「続きを書く」「生成する」ことに向いているのです。
オフラインでランダム初期化した小型 GPT の形を見てみる
「decoder-only LM」の出力をより直感的に感じたいなら、重みをダウンロードせずに、ローカルでランダム初期化した小さなモデルを使えます。
pip install torch transformers
import torch
from transformers import GPT2Config, GPT2LMHeadModel
config = GPT2Config(
vocab_size=100,
n_positions=16,
n_ctx=16,
n_embd=32,
n_layer=2,
n_head=4
)
model = GPT2LMHeadModel(config)
input_ids = torch.tensor([
[1, 7, 9, 12, 5],
[1, 3, 4, 8, 0]
])
outputs = model(input_ids=input_ids)
logits = outputs.logits
print("input_ids shape:", input_ids.shape)
print("logits shape :", logits.shape)
想定出力:
input_ids shape: torch.Size([2, 5])
logits shape : torch.Size([2, 5, 100])
最後の次元は vocab_size=100 です。各サンプル・各位置について、玩具語彙の各 token が「次に来る」候補として 100 個の生スコアを返している、という意味です。
ここでの logits.shape は次のようになります。
[batch, seq_len, vocab_size]
意味は次の通りです。
各位置ごとに、モデルは「次の token の分布」を予測している。
六、in-context learning とは何か?
GPT はなぜ「その場でルールを学ぶ」ように見えるのか?
モデルが大きくなるにつれて、GPT 系列は重要な能力を示すようになりました。
パラメータを変えなくても、文脈の中にいくつか例を与えるだけで、その場でやり方をまねできる。
たとえば、
入力: リンゴ は おいしい
出力: positive
入力: この授業 は ぐちゃぐちゃ だ
出力: negative
入力: 先生 の 説明 は とても わかりやすい
出力:
モデルは続けてこう出すかもしれません。
positive
これが in-context learning の感覚です。
これがなぜ重要なのか?
これは次のことを意味します。
- すべてのタスクでモデルを再学習する必要があるわけではない
- Prompt 自体が、一時的なタスク設定の方法になりうる
この考え方が、後の Prompt engineering、Agent、ツール呼び出しへとつながっていきます。
七、GPT シリーズはどう進化してきたのか?
大まかな流れ
まずはこの流れで覚えるとよいです。
- まず、より強い自己回帰言語モデルを作る
- モデルが大きくなるほど、汎用的な生成能力が強くなる
- さらに指示微調整、整列、好み最適化を行う
- 最後に、より「アシスタント」に近い形になる
「続きを書く」から「協力してくれる」へ
初期の GPT は、どちらかというと次のような存在でした。
- とても強力な文章の続きを書くモデル
その後、次のような調整を経て、
- 指示微調整
- 好み学習
- 安全性の整列
今のような、人とよりうまく協力できるチャットアシスタントに近づいていきました。
つまり、
GPT の会話能力は、事前学習だけでなく、その後の整列によっても生まれています。
八、GPT は何が得意で、何が得意ではないのか?
得意なこと
- テキスト生成
- 対話
- 要約
- 言い換え
- コード生成
- オープンエンドの続きを書くこと
自然には得意ではないこと
- 厳密な事実検索
- 長期的に安定した記憶
- 強い制約が必要な構造化された実行
そのため、実際のシステムでは GPT に次のものを組み合わせることがよくあります。
- RAG
- ツール呼び出し
- 記憶システム
- ガードレール
これをノートやプロジェクトにするとき、何を見せるべきか
一番見せる価値があるのは、単に
- 「GPT は強い」
と書くことではありません。
むしろ次の点です。
- next-token prediction から自己回帰生成へつながる流れ
- causal mask がなぜ学習と生成を一致させるのか
- GPT-1 / 2 / 3 が示した能力の進化
- なぜその後に Prompt、RAG、ツール、整列システムが必要になるのか
こうすると、他の人にも次のことが伝わりやすくなります。
- あなたは GPT の能力の骨格を理解している
- 単に流行っているから知っているわけではない
九、初学者がよくつまずくポイント
GPT は「会話できるモデル」だと思ってしまう
会話は表面の姿です。
根っこは自己回帰言語モデリングです。
学習時にも GPT は双方向に文脈を見られると思ってしまう
違います。
GPT の重要な制約は、未来を見てはいけないことです。
「モデルが大きい」ことだけ知っていて、出力テンソルが何を表すか分からない
本当に覚えるべきなのは次です。
- 各位置が次の token 分布を予測している
- 生成は一歩ずつ積み重ねて作られる
まとめ
この節で最も大事なのは、ある特定の GPT の名前を覚えることではなく、この主線をつかむことです。
GPT = decoder-only + causal mask + next-token prediction + 自己回帰生成。
この流れを理解しておくと、後で Prompt、Agent、ツール呼び出し、大規模モデルの応用を学ぶときに、それらが何の能力の上に成り立っているのかが見えてきます。
練習
- bigram のサンプルでコーパスを変えてみて、生成結果がどう変わるか観察してください。
- 自分の言葉で説明してみましょう。なぜ causal mask は GPT に必須なのでしょうか?
- ランダム初期化した GPT の例に出てきた
logitsの shape を理解してください。それがなぜ[batch, seq_len, vocab_size]になるのでしょうか? - なぜ GPT の「会話ができる」能力は、単純に「次の単語を予測できる」だけと同じではないのでしょうか?