11.6.5 T5【選択】
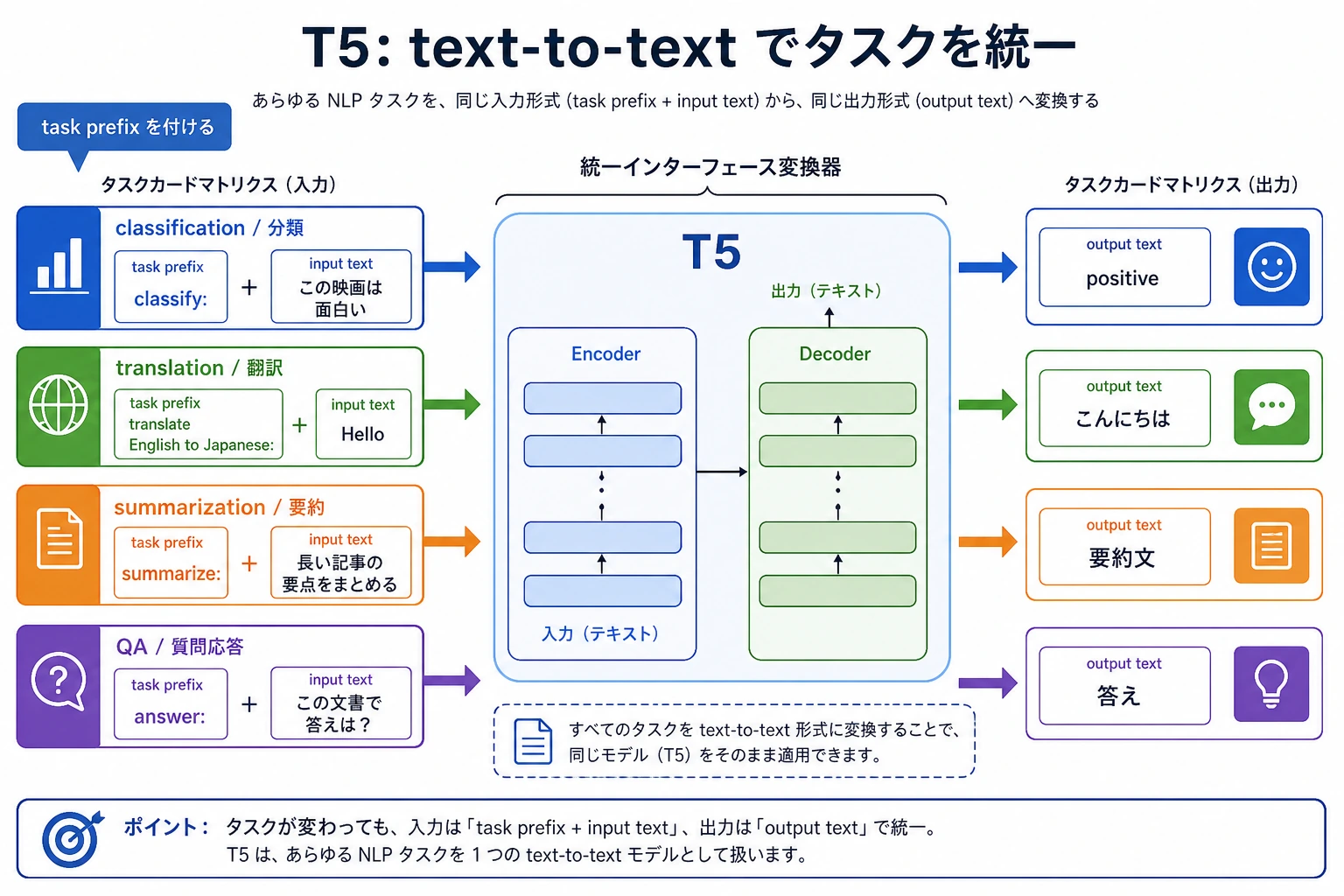
T5 の核心は、分類・翻訳・要約・質問応答をすべて text-to-text に書き換えることです。図を見るときは、タスクのプレフィックス、入力テキスト、出力テキストがどのように 1 つのインターフェースに統一されているかに注目してください。T5 を単なる seq2seq モデルとして見るだけでは足りません。
T5 が学ぶ価値が高いのは、単なる 1 つの具体的なモデルだからではありません。
むしろ、とても重要な考え方をかなり徹底して押し進めたからです。
多くの NLP タスクを「入力テキスト -> 出力テキスト」として統一して表現する。
一見すると単純ですが、タスクの組み立て方に大きな影響があります。
学習目標
- T5 の text-to-text の統一思想を理解する
- BERT / GPT とのタスク構成の違いを理解する
- 実行可能な例を通して「タスクをテキスト化する」感覚をつかむ
- T5 が多くの生成系 NLP タスクに自然に合う理由を理解する
まずは地図を作ろう
T5 を初学者が理解する順番として一番よいのは、「また新しいモデルだ」と見ることではなく、まず次をはっきりさせることです。
つまり、この節で本当に伝えたいのは、「また 1 つモデル名が増える」ということではなく、次の点です。
- なぜタスクの組み立て方を統一できるのか
- なぜそれがデータやインターフェースの設計に影響するのか
初学者向けの、よりわかりやすいたとえ
T5 は、たくさんの NLP タスクに共通の問題形式を与えるものだと考えるとよいです。
以前はたとえば:
- 分類問題は答え用紙が別
- 翻訳問題は作文用紙が別
- 質問応答はまた別の用紙
でも T5 では:
- 「問題文をテキストとして書き、答えもテキストとして書く」に統一します
こうすると、見た目が違っていた多くのタスクを、同じインターフェースで扱えるようになります。
一、T5 の最も重要な考え方は何か?
いろいろなタスクをすべてテキストとして書く
たとえば:
- 翻訳
translate English to Japanese: hello - 要約
summarize: ... - 質問応答
question: ... context: ... - 分類
classify sentiment: ...
なぜこれが面白いのか?
見た目には大きく異なるタスクを、共通のインターフェースにまとめられるからです。
- 入力は 1 つのテキスト
- 出力も 1 つのテキスト
たとえで理解する
従来のやり方が、タスクごとに専用のプラグを用意するようなものだとすると、
T5 はより多くの機器を 1 つの統一された差し込み口でつなぎたい、という発想に近いです。
二、T5 と BERT / GPT の違いはどこにあるのか?
BERT は表現学習の土台に近い
得意なのは:
- エンコード
- 理解
GPT は自己回帰型の生成器に近い
得意なのは:
- 連続生成
- 対話
- 文章生成
T5 はタスクの統一インターフェースをより強く意識する
特徴は:
- Encoder-Decoder 構造
- text-to-text のタスク表現
これにより、「1 つのテキストを入力して、別のテキストを出力する」タイプのタスクが、とても自然になります。
三、まずは最小の text-to-text 例を動かしてみよう
tasks = [
{"input": "translate English to Japanese: hello world", "target": "こんにちは 世界"},
{"input": "summarize: この講義では NLP の核心技術を体系的に解説します。", "target": "講義は NLP の核心技術を解説する"},
{"input": "classify sentiment: この授業がとても好きです", "target": "positive"},
]
for item in tasks:
print(item)
想定出力:
{'input': 'translate English to Japanese: hello world', 'target': 'こんにちは 世界'}
{'input': 'summarize: この講義では NLP の核心技術を体系的に解説します。', 'target': '講義は NLP の核心技術を解説する'}
{'input': 'classify sentiment: この授業がとても好きです', 'target': 'positive'}
どの行も同じ形です。入力テキストにはタスク指示が入り、target にはモデルに生成してほしい答えが入ります。これが、データ形式としての “text-to-text” の実感です。
このコードに価値がある理由
次のことが、とても直感的にわかるからです。
- タスクは違っても、目的はそれぞれ異なる
- しかし T5 風に見ると、すべて「テキスト入力 + テキスト出力」に統一できる
これは従来の分類インターフェースと何が違うのか?
従来の分類では、出力がたとえば:
- class id
になることがあります。
でも T5 のパラダイムでは、
出力として次のような文字列を返すこともできます。
positivenegative
つまり、テキストそのものです。
初めて T5 を学ぶとき、まず覚えるべきこと
まず押さえるべきなのは、次の 3 点です。
- T5 の特別さは、構造だけでなくタスク表現にもある
- 多くの NLP タスクを「テキストを入れて、テキストを出す」に統一できる
- これにより「分類も生成として考えられる」と理解しやすくなる
もう 1 つの最小例:「同じインターフェースで、違うタスク」
examples = [
("translate English to Japanese: good morning", "おはよう"),
("summarize: この講義は機械学習と深層学習を体系的に解説します。", "コースは機械学習と深層学習を体系的に解説している"),
("question: 返金期限はどのくらいですか? context: コース購入後7日以内に返金できます。", "7日以内"),
("classify topic: この記事は GPU の VRAM 最適化を主に議論している", "hardware"),
]
for src, tgt in examples:
print({"input": src, "target": tgt})
想定出力:
{'input': 'translate English to Japanese: good morning', 'target': 'おはよう'}
{'input': 'summarize: この講義は機械学習と深層学習を体系的に解説します。', 'target': 'コースは機械学習と深層学習を体系的に解説している'}
{'input': 'question: 返金期限はどのくらいですか? context: コース購入後7日以内に返金できます。', 'target': '7日以内'}
{'input': 'classify topic: この記事は GPU の VRAM 最適化を主に議論している', 'target': 'hardware'}
この小さなデータセットは、まだ訓練用ではありません。まずは形式の点検です。モデルを選ぶ前に、各タスクを明確な入力テキストと明確な出力テキストで表せるか確認します。
この例は初学者にとても向いています。なぜなら、もともと抽象的だった話が、次のように具体的になるからです。
- 分類、質問応答、翻訳、要約
- これらは本当に同じ種類の「テキスト入力 -> テキスト出力」として書き直せる
四、T5 が多くのタスクに自然に合うのはなぜか?
多くの NLP タスクは、もともとテキスト変換として見られるから
たとえば:
- 1 文 -> 別の言語の文
- 長文 -> 要約
- 質問 + 文脈 -> 答え
生成的な分類にも向いている
タスクによっては、必ずしも整数ラベルを出力する必要はありません。
ラベル語をそのまま出すほうが自然なこともあります。
工学的なメリット
タスクのインターフェースをより統一しやすくなります。
データ形式を考えるときも、同じ軸で整理しやすくなります。
タスクを text-to-text に書き換えるときの、無理のない順番
一般的には、次の順番が安定しています。
- まずタスクのプレフィックスをはっきりさせる
- 出力テキストの形を先に決める
- いくつかの例で、自然な書き方か確認する
- そのうえで、同じインターフェースに統一する価値があるか判断する
最初から全部のタスクを無理に text-to-text に押し込むより、この方がずっと安全です。
五、よくあるつまずきポイント
誤解 1:T5 はただの別の seq2seq モデル
それだけではありません。
より重要なのは次の点です。
- タスクの表し方
誤解 2:text-to-text のほうが常に他のパラダイムより優れている
そうではありません。
これは統一の考え方であって、すべてのタスクで絶対最適という意味ではありません。
誤解 3:インターフェースを統一すれば、それで簡単になる
統一インターフェースには多くの利点があります。
ただし、入力プロンプトや出力形式を丁寧に設計する必要は、やはりあります。
ノートやプロジェクトにするなら、何を見せるとよいか
見せる価値が高いのは、たいてい次のようなものです。
- 「T5 でも分類できる」という事実そのもの
よりも、むしろ:
- 同じインターフェースで複数のタスク例を示す
- 入力プレフィックスがどのようにタスクを変えるか示す
- このやり方が、なぜ実装や整理に役立つのか説明する
- BERT / GPT とのタスクの見方の違いを示す
こうすると、相手には次のことが伝わりやすくなります。
- あなたが理解しているのは、モデル名ではなくタスク構成の考え方だ
- ただ 1 つのモデル名を覚えたわけではない
まとめ
この節で一番大事なのは、タスクの組み立て方に関する直感を持つことです。
T5 の本当の価値は、モデルそのものだけではなく、多くの NLP タスクを text-to-text 形式で統一して表現できることを示した点にあります。
この理解ができていれば、後で多くの生成系タスクを見るときに、より自然に理解できます。
この節で持ち帰るべきこと
- T5 の価値はモデルだけでなく、text-to-text パラダイムにもある
- タスクのインターフェースを統一すると、データやタスクの組み立て方が変わる
- これは後の多くの生成系 NLP ワークフローの重要な前身になっている
練習
- 自分で 3 つタスクを書き、それぞれを text-to-text 形式に書き換えてみましょう。
- なぜ T5 の重要性はモデルだけでなく、タスクの統一方法にもあるのでしょうか?
- どのタスクが text-to-text に特に向いていて、どのタスクは必ずしもそうした構成が必要ではないのか、考えてみましょう。
- 自分の言葉で、T5 と BERT / GPT のタスク視点の違いを説明してみましょう。