11.6.3 BERT シリーズ
BERT は、現代 NLP が「事前学習が主流の時代」へ入るうえでの重要な節目の一つです。
今あなたが目にする多くの大規模モデルの概念も、形は進化していても、その理解の土台のかなり多くを BERT から見つけることができます。
学習目標
- BERT がなぜ NLP のマイルストーンになったのかを理解する
- BERT と GPT のような自己回帰モデルの核心的な違いを説明できる
[CLS]、[SEP]、[MASK]、双方向コンテキストといった重要概念を理解する- 最小限の BERT 入力例を読めるようになる
- BERT のよくある fine-tuning の方法を理解する
歴史的背景:BERT はどの論文から来たのか?
この節で最も重要な歴史的ポイントは次のとおりです:
| 年 | 論文 | 主要著者 | 最も重要に解決したこと |
|---|---|---|---|
| 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Devlin ほか | 双方向 Transformer の事前学習 + fine-tuning を、現代 NLP の理解タスクの主流にした |
初心者がまず覚えるべきことは次の点です:
- BERT は「また別のモデル名」ではない
- これは非常に重要なパラダイムの変化を表している
まず大量のテキストで汎用的に事前学習し、その同じ土台をさまざまなタスクに fine-tuning する。
そのため、今日あなたが大規模モデルを学ぶときに感じる「まず事前学習して、それから適応する」という感覚の原型は、BERT にとてもはっきり見られます。
一、BERT はいったい何を解決したのか?
まず昔からある問題を見る:語義は文脈に依存する
単語の意味は、いつも固定ではありません。
たとえば英語の bank は:
- “river bank” では川岸
- “bank account” では銀行
中国語でも同じです:
- “りんご很好吃” の「りんご」は果物
- “りんご发布了新设备” の「りんご」は会社
もしモデルが各単語に固定のベクトルしか与えないなら、とても苦しくなります。
BERT の重要な突破
BERT の核心的な貢献の一つは:
ある単語の表現を、実際に文脈に依存させたこと。
つまり、同じ単語でも、違う文の中では違う表現を持てます。
これが「文脈化表現(contextual representation)」です。
初学者向けのたとえ
BERT は次のように考えるとわかりやすいです:
- 文を読むときに前後を両方見る「精読タイプ」
昔の静的な単語ベクトルのように、単語へ固定の名刺を一枚渡すのではなく、
むしろ:
- 同じ単語でも、異なる文に入ると、その文の中で今どんな役割をしているかを考え直す
このため、BERT は特に理解系タスクに向いています。
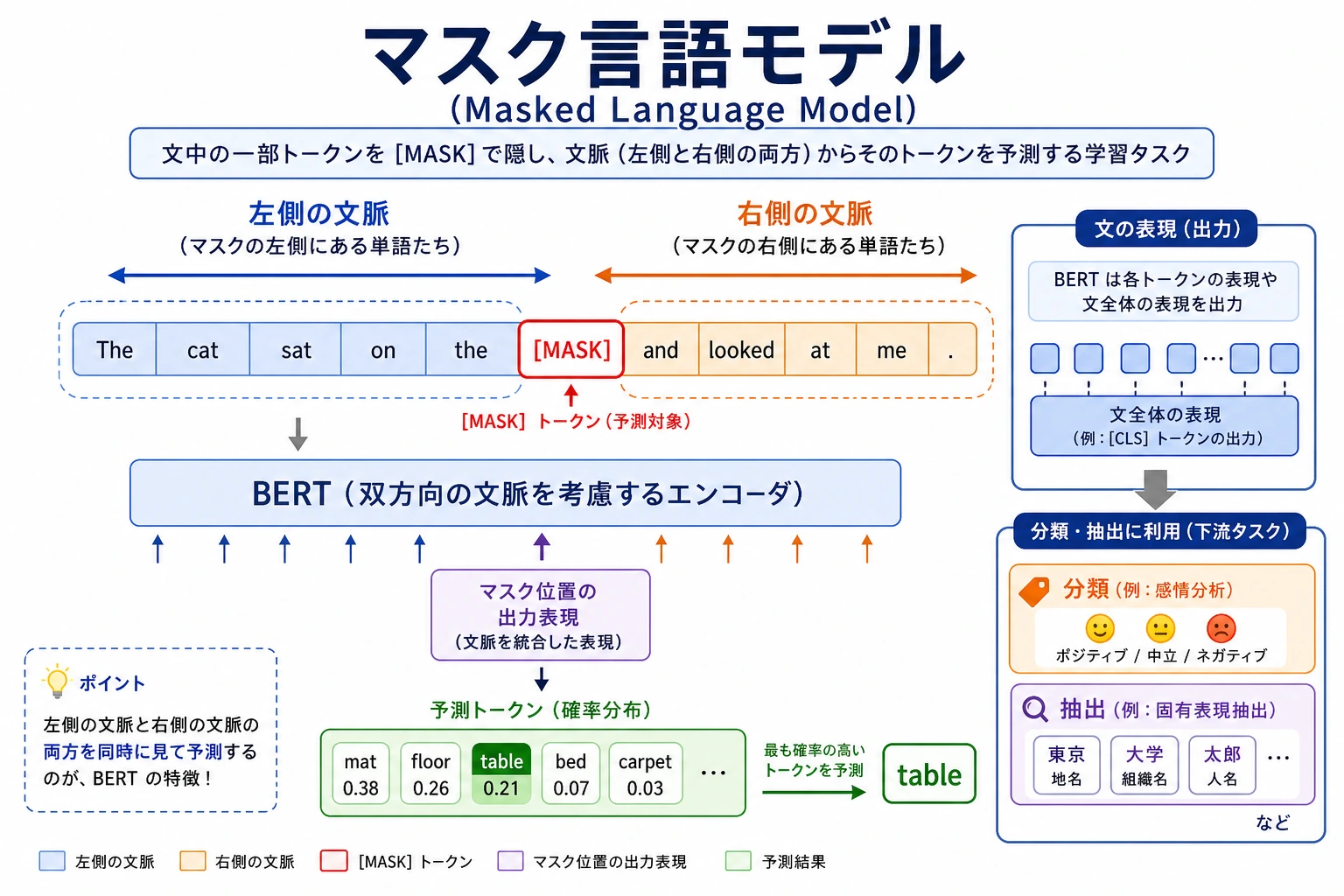
二、なぜ BERT は「双方向」モデルと呼ばれるのか?
双方向とはどういう意味か?
次の文を見てみましょう:
“我昨天在银行旁边散步”
「银行」を理解するとき、人は前の “我昨天在” だけを見るのではなく、後ろの “旁边散步” も見ます。
BERT の重要な特徴は:
現在の token の表現が、左側と右側の文脈の両方を同時に利用すること。
GPT との核心的な違い
大まかに言うと:
- BERT:理解寄り。文脈を双方向で見る
- GPT:生成寄り。左側の履歴だけを見る
そのため:
- 分類、抽出、マッチングには BERT が強い
- 続きの生成、対話、文章生成には GPT 系のほうが自然
三、BERT の入力は実際どうなっているのか?
とてもよく出る3つの特殊 token
| token | 役割 |
|---|---|
[CLS] | 文レベルタスクの集約位置 |
[SEP] | 文の区切り |
[MASK] | 事前学習で隠す位置 |
最小の入力例
tokens = ["[CLS]", "私", "は", "自", "然", "言", "語", "処", "理", "が", "好", "き", "です", "[SEP]"]
print(tokens)
print("シーケンス長:", len(tokens))
想定出力:
['[CLS]', '私', 'は', '自', '然', '言', '語', '処', '理', 'が', '好', 'き', 'です', '[SEP]']
シーケンス長: 14
境界 token も実際のシーケンス長に含まれます。モデルの計算量や attention mask は、目に見える単語だけでなく、特殊 token を含む完全な token 列に対して決まります。
句対タスク、たとえば質問文マッチングなら:
tokens = [
"[CLS]", "今", "日", "の", "天", "気", "は", "ど", "う", "です", "か", "[SEP]",
"東", "京", "は", "今", "日", "雨", "が", "降", "り", "ま", "す", "か", "[SEP]"
]
print(tokens)
想定出力:
['[CLS]', '今', '日', 'の', '天', '気', 'は', 'ど', 'う', 'です', 'か', '[SEP]', '東', '京', 'は', '今', '日', '雨', 'が', '降', 'り', 'ま', 'す', 'か', '[SEP]']
文ペアでは [SEP] が 2 回出ます。1 つ目は文 A の終わり、2 つ目は文 B の終わりです。実際の BERT 入力では、segment id が 2 つの文を区別する助けになります。
初学者がまず覚えやすい入力構造表
| コンポーネント | まず覚えるべき役割 |
|---|---|
[CLS] | 文レベルタスクの集約位置 |
[SEP] | 文の境界を区切る |
[MASK] | 事前学習で復元すべき位置 |
この表は初心者にとても役立ちます。BERT の入力を、ただの「謎の token 列」ではなく、説明できる部品の集まりとして見直せるからです。
四、BERT は事前学習で何をしているのか?
もっとも有名なタスク:Masked Language Modeling
BERT の最も代表的な学習目標は MLM、つまり:
文の一部の token を隠し、文脈から元の token を当てさせること。
たとえば:
“私は [MASK] 言語処理が好きです”
モデルは前後の文脈から [MASK] が何かを予測します。
最小の実行例
tokens = ["[CLS]", "私", "は", "[MASK]", "言", "語", "処", "理", "[SEP]"]
mask_index = tokens.index("[MASK]")
candidates = ["自", "然", "機"]
print("tokens =", tokens)
print("mask index =", mask_index)
print("候補の穴埋め =", candidates)
想定出力:
tokens = ['[CLS]', '私', 'は', '[MASK]', '言', '語', '処', '理', '[SEP]']
mask index = 3
候補の穴埋め = ['自', '然', '機']
mask index は、モデルがどの位置を予測すべきかを示します。本物の MLM では、この手書きの候補だけでなく、語彙全体に対してスコアを出します。
この例は本当のモデル学習ではありませんが、次のことを教えてくれます:
[MASK]の位置は明確である- モデルの仕事は隠された情報を復元すること
- ある token の予測は双方向文脈に依存する
なぜこれが重要なのか?
なぜなら、モデルに本当に次のことを考えさせるからです:
- 左側に何が書かれているか
- 右側に何が書かれているか
- 今隠されている位置には何が入るべきか
その結果、BERT は「理解系タスク」にとても強くなります。
BERT を最初に学ぶときの、いちばん安定した順番
一般的には、次の順番が安定です:
- まず双方向コンテキストが何を補っているのかを理解する
[CLS] / [SEP] / [MASK]の3つのよく出る token を見る- MLM が学習時にモデルへ何を求めるのかを見る
- 最後に fine-tuning で分類ヘッドをどうつなぐかを見る
この順番のほうが、いきなり論文の細部や大規模モデルのパラメータを追うより、主線をつかみやすいです。
五、BERT の入力は token だけではない
Token Embedding
各 token はまずベクトルになります。
Position Embedding
モデルは順序も知る必要があるので、位置情報も加えます。
Segment Embedding
句対タスクでは、モデルはさらに「どの token が文 A に属し、どの token が文 B に属するか」も知る必要があります。
BERT の入力は、次の3つを足し合わせたものと考えられます:
最終入力表現 = token embedding + position embedding + segment embedding
Transformer 自体には、系列の順序感覚がもともと備わっていないので、このステップはとても重要です。
六、実際に動かせるオフライン BERT の例
以下の例は事前学習済み重みをダウンロードしなくてもよく、transformers と torch をインストールすれば、ローカルでランダム初期化された小さな BERT を作れます。主な目的は、入力と出力の shape を理解することです。
pip install torch transformers
import torch
from transformers import BertConfig, BertModel
config = BertConfig(
vocab_size=100,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=64
)
model = BertModel(config)
input_ids = torch.tensor([
[1, 5, 8, 9, 2, 0, 0], # 短いサンプル。後ろを 0 で埋める
[1, 7, 6, 3, 4, 2, 0]
])
attention_mask = torch.tensor([
[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0]
])
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
print("last_hidden_state shape:", outputs.last_hidden_state.shape)
print("pooler_output shape :", outputs.pooler_output.shape)
想定出力:
last_hidden_state shape: torch.Size([2, 7, 32])
pooler_output shape : torch.Size([2, 32])
このモデルはランダム初期化なので、数値そのものは意味のある予測ではありません。ここで見るべきなのは shape です。2 件のサンプル、各 7 位置、各 token が 32 次元の隠れ表現を持っています。
出力はどう理解する?
-
last_hidden_state- shape:
[batch, seq_len, hidden_size] - 各 token が文脈化された表現を持つ
- shape:
-
pooler_output- shape:
[batch, hidden_size] - 一文全体の要約表現の一つとして理解できる
- shape:
これで、BERT が次のように使い分けられる理由もわかります:
- token レベルのタスク:
last_hidden_stateを見る - 文レベルのタスク:
[CLS]や文レベル表現を見る
七、BERT はどうやって分類に使うのか?
典型的な流れ
もっとも一般的な方法は次の通りです:
- 文を入力する
- BERT を通す
[CLS]または文表現を取り出す- 線形分類ヘッドをつなぐ
これが classic な fine-tuning のやり方です。
概念レベルの小さな例
import torch
from torch import nn
# これは BERT の [CLS] 表現だと仮定する
cls_embedding = torch.randn(4, 32) # batch=4, hidden=32
# 分類ヘッドをつなぐ
classifier = nn.Linear(32, 2)
logits = classifier(cls_embedding)
print("logits shape:", logits.shape)
想定出力:
logits shape: torch.Size([4, 2])
batch に 4 件のサンプルがあり、分類ヘッドが各サンプルに 2 つの生スコアを返している、という意味です。実際の分類では、この logits に softmax や cross-entropy を組み合わせることが多いです。
このコードはとてもシンプルですが、次の重要な事実を教えてくれます:
BERT はタスクの終点ではなく、しばしば「強力な表現層」である。
BERT をプロジェクトに入れるとき、何を最初に見せるべきか
最初に見せるべきなのは、たいてい次のような点です:
- 「BERT を使いました」だけではない
- 入力テキストがどういう形か
[CLS]表現をどう分類ヘッドにつないだか- 既存の表現や軽量モデルより何が良いのか
- どのような誤りはまだ起こるのか
こうすると、相手にも次のことが伝わりやすくなります:
- あなたは BERT がタスクの流れの中で果たす役割を理解している
- 単にモデル名を置き換えただけではない
八、BERT はどんなタスクに向いているのか?
特に向いているもの
- テキスト分類
- 句対マッチング
- 固有表現抽出
- 抽出型質問応答
あまり自然ではないもの
BERT は、もともと長文の自由生成のために設計されたモデルではありません。
もしタスクの中心が次のようなものなら:
- 長い対話生成
- 続きの文章生成
- 長文コンテンツの創作
その場合は、GPT 系のほうが自然です。
九、BERT はなぜ後に唯一の主役ではなくなったのか?
理由は「役に立たなかった」からではなく、発展が続いたから
その後の NLP と LLM の発展によって、次のような流れが生まれました:
- より大規模な事前学習
- より強い生成モデル
- より統一されたタスクインターフェース
そのため、今日の多くのアプリケーションでは、GPT、T5、Llama などの系統がよりよく話題になります。
それでも BERT を学ぶ価値は非常に高い
なぜなら、次のことを本当に理解する助けになるからです:
- 文脈化表現
- encoder-only モデル
- 事前学習 + fine-tuning のパラダイム
- token レベルと文レベルタスクの違い
これらは、後で大規模モデルを学ぶうえでのとても大事な土台です。
十、初心者がよくハマる落とし穴
BERT と GPT を同じものだと思ってしまう
どちらも重要ですが、学習目標も得意なタスクも違います。
[CLS] を「自動的に最良の文ベクトル」だと思ってしまう
多くのタスクでは便利ですが、どこでも万能というわけではありません。
「BERT で分類した」だけで、何を学んでいるのかを理解していない
本当に押さえるべきなのは次の点です:
- なぜ双方向なのか
- なぜ MLM が有効なのか
- なぜ理解タスクに向いているのか
まとめ
この節で最も大事なのは、BERT の正式名称を暗記することではなく、次の3点をつかむことです:
- BERT は双方向コンテキストモデリングの代表である
- MLM によって「文脈に基づいて token を理解する」ことを学ぶ
- 理解系タスクと fine-tuning パラダイムに非常に向いている
この3つがわかれば、その後に GPT、T5、LLM を学ぶときも、多くの違いが自然に見えてきます。
練習
[MASK]を含む日本語の文を自分で作り、最も妥当だと思う候補語を書いてみましょう。- オフライン BERT の例で
hidden_sizeを 64 に変更し、出力 shape がどう変わるか見てみましょう。 - 「私は [MASK] 言語処理が好きだ」のような学習目標が、なぜモデルに双方向理解を学ばせるのか考えてみましょう。
- 自分の言葉で、BERT と GPT の「文脈の見方」の核心的な違いを説明してみましょう。