BERT 系列
BERT 是现代 NLP 进入“预训练大一统时代”的关键节点之一。
很多今天你看到的大模型概念,虽然形态已经演化,但不少理解基础都能从 BERT 身上找到。
学习目标
- 理解 BERT 为什么会成为 NLP 的里程碑
- 说清楚 BERT 和 GPT 这类自回归模型的核�心区别
- 掌握
[CLS]、[SEP]、[MASK]、双向上下文这些关键概念 - 看懂一个最小 BERT 输入示例
- 理解 BERT 常见的微调方式
历史背景:BERT 来自哪篇论文?
这一节最关键的历史节点是:
| 年份 | 论文 | 关键作者 | 它最重要地解决了什么 |
|---|---|---|---|
| 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Devlin 等 | 把双向 Transformer 预训练 + 微调做成现代 NLP 理解任务的主线 |
对新人来说,最值得先记的是:
- BERT 不是“又一个模型名”
- 它代表的是一种非常重要的范式变化:
先在海量文本上做通用预训练,再把同一个底座微调到不同任务上。
这也是为什么你今天学大模型时,很多“先预训练、再适配”的感觉,会在 BERT 这里看到非常清楚的雏形。
一、BERT 到底解决了什么问题?
1.1 先看老问题:词义依赖上下文
单词不是总有固定意思。
例如英文里的 bank:
- “river bank” 是河岸
- “bank account” 是银行
中文里也一样:
- “苹果很好吃” 里的苹果是水果
- “苹果发布了新设备” 里的苹果是公司
如果模型只能给每个词一个固定向量,就会很吃力。
1.2 BERT 的关键突破
BERT 的核心贡献之一是:
让一个词的表示真正依赖上下文。
也就是说,同一个词在不同句子里,可以得到不同的表示。
这就是“上下文化表示(contextual representation)”。
1.3 一个更适合新人的总类比
你可以把 BERT 理解成:
- 一个读句子时会前后都看的“精读型选手”
它不像早期静态词向量那样只给词发一个固定名片,
而更像:
- 同一个词放在不同句子里,会重新理解它现在扮演的角色
这就是为什么 BERT 特别适合理解类任务。
二、为什么 BERT 会被称为“双向”模型?
2.1 双向是什么意思?
看一句话:
“我昨天在银行旁边散步”
理解“银行”时,人并不会只看前面的“我昨天在”,也会看后面的“旁边散步”。
BERT 的重要特点就是:
当前 token 的表示,同时利用左边和右边的上下文。
2.2 和 GPT 的核心区别
粗略地说:
- BERT:更偏理解,双向看上下文
- GPT:更偏生成,只看左边历史
所以:
- 做分类、抽取、匹配时,BERT 很强
- 做续写、对话、生成时,GPT 路线更自然
三、BERT 的输入到底长什么样?
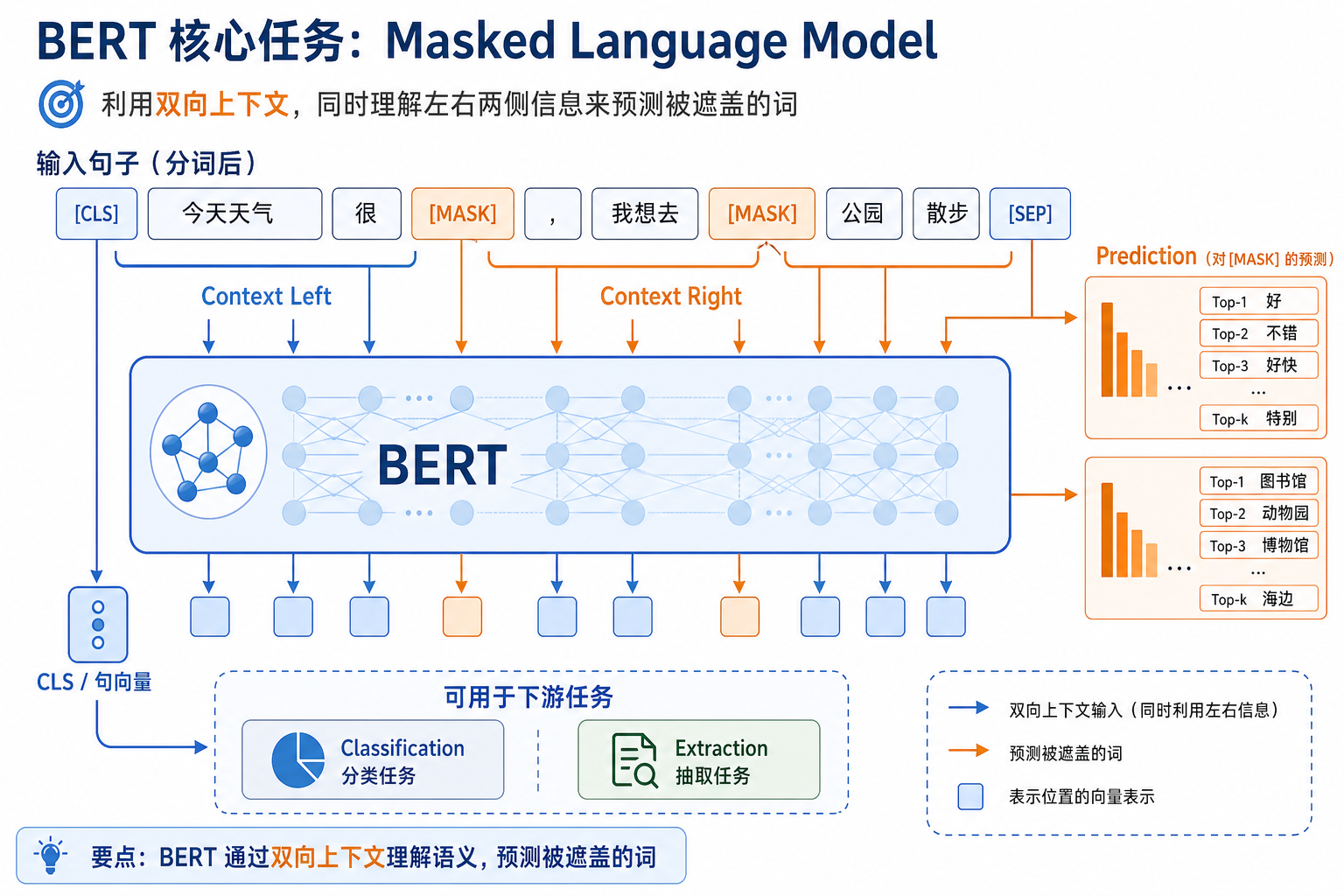
3.1 三个特别常见的特殊 token
| token | 作用 |
|---|---|
[CLS] | 句子级任务的聚合位置 |
[SEP] | 句子分隔符 |
[MASK] | 预训练时被遮住的位置 |
3.2 一个最小输入例子
tokens = ["[CLS]", "我", "爱", "自", "然", "语", "言", "处", "理", "[SEP]"]
print(tokens)
print("序列长度:", len(tokens))
如果是句对任务,比如问句匹配:
tokens = [
"[CLS]", "今", "天", "天", "气", "怎", "么", "样", "[SEP]",
"北", "京", "今", "天", "会", "下", "雨", "吗", "[SEP]"
]
print(tokens)
3.3 一个很适合初学者先记的输入结构表
| 组件 | 最值得先记住的作用 |
|---|---|
[CLS] | 句子级任务的聚合位置 |
[SEP] | 句子边界分隔 |
[MASK] | 预训练时要恢复的位置 |
这个表特别适合新人,因为它会把 BERT 输入从“神秘 token 串”重新变成几个能解释的部件。
四、BERT 预训练时在做什么?
4.1 最经典任务:Masked Language Modeling
BERT 最经典的训练目标是 MLM,也就是:
把句子中的一部分 token 遮住,让模型根据上下文猜回来。
例如:
“我爱 [MASK] 语言处理”
模型要根据前后文猜 [MASK] 是什么。
4.2 一个最小可运行示例
tokens = ["[CLS]", "我", "爱", "[MASK]", "语", "言", "处", "理", "[SEP]"]
mask_index = tokens.index("[MASK]")
candidates = ["自", "学", "看"]
print("tokens =", tokens)
print("mask index =", mask_index)
print("候选填空 =", candidates)
这个例子虽然不是在真正训练模型,但已经在教你:
[MASK]的位置是明确的- 模型的任务是恢复被遮住的信息
- 当前词的预测依赖双向上下文
4.3 为什么这件事很重要?
因为它迫使模型真正去理解:
- 左边说了什么
- 右边说了什么
- 当前被遮住的位置该是什么
这让 BERT 非常擅长“理解型任务”。
4.4 第一次学 BERT 时,最稳的默认顺序
更稳的顺序通常是:
- 先理解双向上下文到底在补什么
- 先看
[CLS] / [SEP] / [MASK]这几个最常见 token - 再看 MLM 在训练时要求模型学什么
- 最后再看微调是怎么接分类头的
这样会比一上来就盯论文细节和大模型参数更容易稳住主线。
五、BERT 的输入不只有 token
5.1 Token Embedding
每个 token 会先变成向量。
5.2 Position Embedding
模型还要知道顺序,所以要加位置编码。
5.3 Segment Embedding
在句对任务里,模型还要知道“哪些 token 属于句子 A,哪些属于句子 B”。
你可以把 BERT 的输入想成三部分相加:
最终输入表示 = token embedding + position embedding + segment embedding
这一步很重要,因为 Transformer 本身不自带序列顺序感。
六、一个真正可运行的离线 BERT 示例
下面这个示例不需要下载预训练权重,只需要安装 transformers 和 torch,就可以本地随机初始化一个小型 BERT,主要用来帮助你理解输入输出形状。
pip install torch transformers
import torch
from transformers import BertConfig, BertModel
config = BertConfig(
vocab_size=100,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=64
)
model = BertModel(config)
input_ids = torch.tensor([
[1, 5, 8, 9, 2, 0, 0], # 一条较短样本,后面补 0
[1, 7, 6, 3, 4, 2, 0]
])
attention_mask = torch.tensor([
[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0]
])
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
print("last_hidden_state shape:", outputs.last_hidden_state.shape)
print("pooler_output shape :", outputs.pooler_output.shape)
6.2 输出怎么理解?
-
last_hidden_state- shape:
[batch, seq_len, hidden_size] - 每个 token 都有一个上下文化表示
- shape:
-
pooler_output- shape:
[batch, hidden_size] - 通常可理解为整句摘要表示之一
- shape:
这也解释了为什么 BERT 适合:
- token 级任务:看
last_hidden_state - 句子级任务:看
[CLS]或句级表示
七、BERT 怎么拿来做分类?
7.1 典型套路
最常见的做法是:
- 输入句子
- 经过 BERT
- 拿
[CLS]或句子表示 - 接一个线性分类头
这就是经典的 fine-tuning 方式。
7.2 一个概念级的小例子
import torch
from torch import nn
# 假设这是 BERT 输出的 [CLS] 表示
cls_embedding = torch.randn(4, 32) # batch=4, hidden=32
# 接一个分类头
classifier = nn.Linear(32, 2)
logits = classifier(cls_embedding)
print("logits shape:", logits.shape)
这段代码很简单,但它教你一个很重要的事实:
BERT 往往不是任务的终点,而是“强表示层”。
7.3 如果把 BERT 放进项目里,最值得先展示什么
最值得展示的通常不是:
- “我用了 BERT”
而是:
- 输入文本长什么样
[CLS]表示怎么接分类头- 它比传统表示或轻模型好在什么地方
- 哪些错例它仍然会错
这样别人会更容易看出:
- 你理解的是 BERT 在任务链里的角色
- 不只是换了个模型名
八、BERT �适合哪些任务?
8.1 特别适合
- 文本分类
- 句对匹配
- 命名实体识别
- 抽取式问答
8.2 不那么自然的地方
BERT 本身不是为了长文本自由生成设计的。
如果任务重点是:
- 长对话生成
- 续写
- 大段文本创作
那 GPT 路线通常更自然。
九、BERT 为什么后来不再是唯一主角?
9.1 原因不是它没用,而是生态继续往前走了
后面 NLP 和 LLM 发��展出了:
- 更大规模的预训练
- 更强的生成模型
- 更统一的任务接口
所以今天很多应用更常讨论 GPT、T5、Llama 这类路线。
9.2 但 BERT 仍然非常值得学
因为它能帮你真正理解:
- 上下文化表示
- encoder-only 模型
- 预训练 + 微调范式
- token 级和句子级任务的区别
这些都是后面继续学大模型的重要地基。
十、初学者最常踩的坑
10.1 把 BERT 和 GPT 混成一个东西
它们都很重要,但训练目标和擅长任务并不一样。
10.2 以为 [CLS] 是“天然最佳句向量”
在很多任务里它好用,但并不是放之四海��皆准。
10.3 只知道“用 BERT 做分类”,不知道它到底学了什么
真正要掌握的是:
- 为什么它是双向的
- 为什么 MLM 有效
- 为什么它更适合理解任务
小结
这一节最重要的不是记住 BERT 的全称,而是抓住三件事:
- BERT 是双向上下文建模的代表
- 它通过 MLM 学会“基于上下文理解 token”
- 它非常适合理解型任务和微调范式
理解了这三点,你后面再学 GPT、T5、LLM 时,很多差异就会自然清楚。
练习
- 自己构造一个带
[MASK]的中文句子,写出你认为最合理的候选词。 - 把离线 BERT 示例里的
hidden_size改成 64,再看输出 shape 怎样变化。 - 想一想:为什么“我爱 [MASK] 语言处理”这种训练目标,能让模型学会双向理解?
- 用自己的话解释:BERT 和 GPT 在“看上下文”的方式上有什么核心差别?