序列标注任务
本节定位
文本分类的输出通常是:
- 整句一个标签
而序列标注的输出更细:
- 每个 token 一个标签
这一步非常关键,因为它把 NLP 从“整句判断”推进到了:
在句子内部定位具体信息。
也正是从这里开始,我们才更自然地走向命名实体识别、信息抽取、槽位填充这类任务。
学习目标
- 理解序列标注和整句分类的根本区别
- 理解 BIO / BIOES 这类标签体系为什么常用
- 通过可运行示例理解 token 级标注过程
- 建立序列标注和信息抽取任务之间的联系
一、序列标注到底在解决什么问题?
1.1 它不只是判断“这句话是什么”,而是判断“这句话里哪一段是什么”
例如句子:
- “张三在北京大学工作”
如果做文本分类,也许只会输出:
- 这是一个关于人物与地点的句子
但序列标注更关心:
张三是人名北京大学是机构名
1.2 为什么这很重要?
因为很多真实业务并不满足于整句理解。
它们更关心:
- 人名
- 地址
- 机构名
- 金额
- 时间
这些具体片段的位置和边界。
1.3 一个类比
文本分类像给整篇文章贴标签。
序列标注像拿荧光笔在句子里圈重点。
二、为什么输出通常要按 token 来标?
2.1 因为实体是连续片段
很多要抽的信息不是单个词,而是一段连续 span。
例如:
上海交通大学2025年6月1日
2.2 用 token 级标签可以表达边界
这就是为什么常见标签体系不是简单地写:
- PERSON
- LOCATION
而是会写:
B-PERI-PERO
2.3 BIO 的直觉
B-:实体开始I-:实体内部O:不属于任何实体
这样系统就能更明确地区分:
- 一个实体从哪里开始
- 到哪里结束
三、先跑一个最小 BIO 标注示例
tokens = ["张三", "在", "北京", "大学", "工作"]
tags = ["B-PER", "O", "B-ORG", "I-ORG", "O"]
for tok, tag in zip(tokens, tags):
print(tok, tag)
3.1 这个例子最核心的地方是什么?
它让你看到:
- 序列输入
- 对应的序列输出
这就是序列标注最本质的形式:
输入一串 token,输出同样长度的一串标签。
3.2 为什么 北京 大学 会被标成 B-ORG / I-ORG?
因为这里想表达的是:
- 这是同一个连续实体
而不是两个分开的实体。
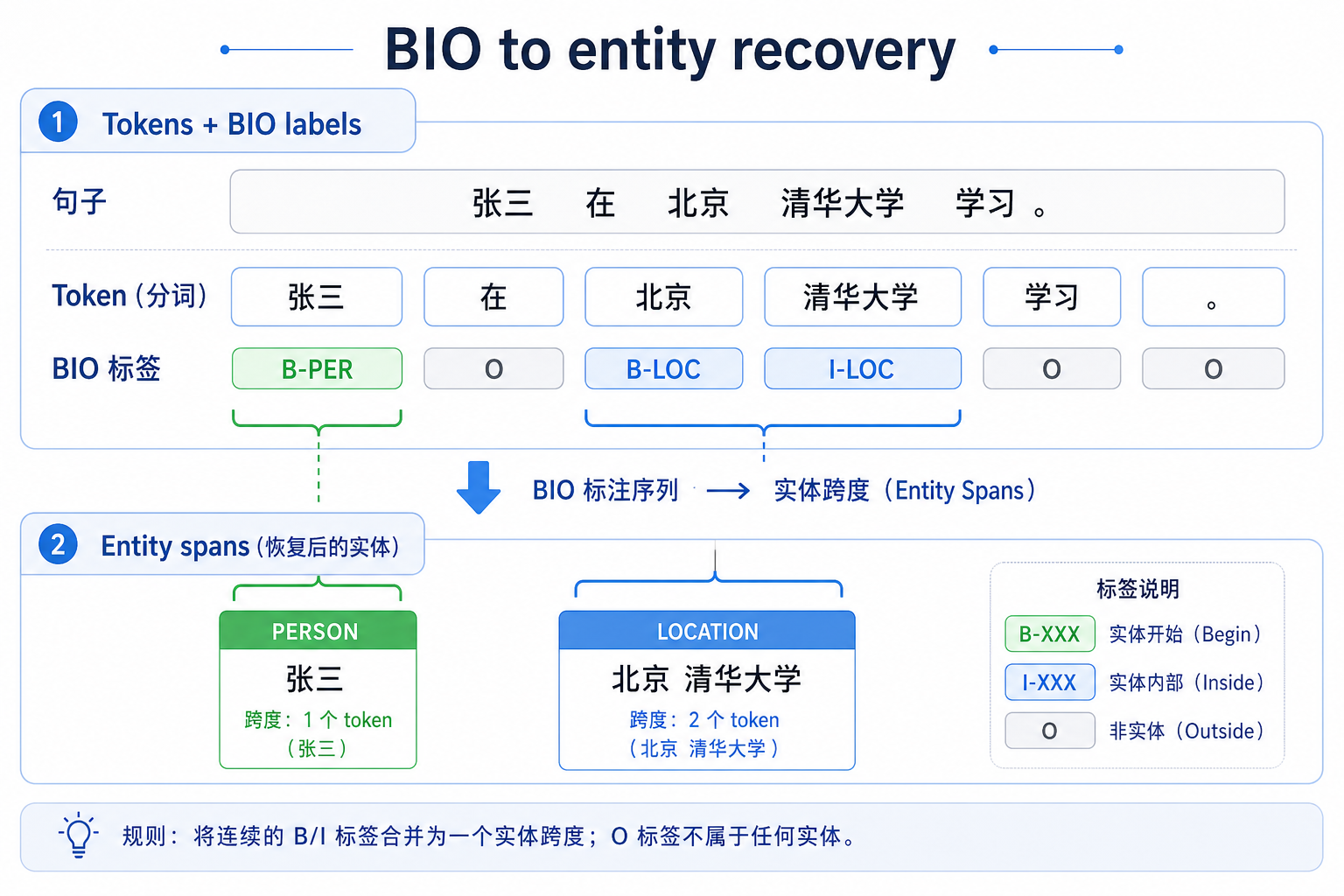
四、从标签序列还原实体
下面这个例子会把 token + BIO 标签恢复成实体片段。
tokens = ["张三", "在", "北京", "大学", "工作"]
tags = ["B-PER", "O", "B-ORG", "I-ORG", "O"]
def decode_entities(tokens, tags):
entities = []
current_tokens = []
current_type = None
for token, tag in zip(tokens, tags):
if tag == "O":
if current_tokens:
entities.append(("".join(current_tokens), current_type))
current_tokens = []
current_type = None
continue
prefix, entity_type = tag.split("-", 1)
if prefix == "B":
if current_tokens:
entities.append(("".join(current_tokens), current_type))
current_tokens = [token]
current_type = entity_type
elif prefix == "I" and current_type == entity_type:
current_tokens.append(token)
else:
# 标签不合法时,简单切断并重开
if current_tokens:
entities.append(("".join(current_tokens), current_type))
current_tokens = [token]
current_type = entity_type
if current_tokens:
entities.append(("".join(current_tokens), current_type))
return entities
print(decode_entities(tokens, tags))
4.1 这段代码为什么很重要?
因为它把“标注任务”和“抽取结果”连起来了。
真实系统里我们真正关心的通常不是标签本身,而是:
- 实体 span
- 实体类型
五、序列标注和信息抽取是什么关系?
5.1 NER 是典型序列标注任务
最经典的就是:
- 命名实体识别
5.2 但它不只用于 NER
还可以做:
- 槽位填充
- 关键词抽取
- 事件触发词定位
5.3 所以它是“信息抽取的底层技能”
很多抽取系统后面会更复杂,
但最基础的一步常常仍然是:
- 先把关键 span 标出来
六、最容易踩的坑
6.1 误区一:把序列标注当成普通分类
它和整句分类最大的差别就在于:
- 输出是对齐序列
6.2 误区二:只看标签,不看边界恢复
真实系统更关心最终抽出的实体片段,
不是标签表本身。
6.3 误区三:标签体系随便定
如果标签设计混乱,模型和评估都会一起乱。
小结
这节最重要的是建立一个判断:
序列标注的核心,是对输入序列中的每个 token 做标签判断,从而恢复出句子内部的关键片段与边界。
只要这个直觉稳住了,后面学 NER、BiLSTM+CRF 和信息抽取项目时就会顺很多。
练习
- 把示例再加一个时间实体,例如
2025年,自己写一组 BIO 标签。 - 为什么说 BIO 标签体系的关键作用是表达实体边界?
- 用自己的话解释:序列标注和文本分类最大的区别是什么?
- 想一想:如果标签序列里出现不合法的
I-XXX,系统该怎么处理更稳?