GPT 系列
如果说 BERT 更像“读懂文本的高手”,那 GPT 路线更像:
根据已有上下文,把后面的内容一段段续出来。
这条路线后来一路长成了今天我们熟悉的大语言模型主线。
学习目标
- 理解 GPT 的核心训练目标为什么是“预测下一个 token”
- 理解 GPT 和 BERT 在结构与任务上的关键区别
- 理解 causal mask 为什么不可少
- 通过一个最小 bigram 语言模型体验自回归生成
- 理解 GPT 系列从“续写模型”走向“对话助手”的演化逻辑
历史背景:GPT 这条线是怎样长出来的?
GPT 更适合按“系列节点”来理解,而不是只盯一个模型:
| 年份 | 节点 | 代表论文 | 它最重要地解决了什么 |
|---|---|---|---|
| 2018 | GPT-1 | Improving Language Understanding by Generative Pre-Training | 把 decoder-only 预训练路线真正推到主流视野 |
| 2019 | GPT-2 | Language Models are Unsupervised Multitask Learners | 用更大规模模型展示出强生成能力和零样本潜力 |
| 2020 | GPT-3 | Language Models are Few-Shot Learners | 把 in-context learning / few-shot 现象推到主流 |
对新人来说,最值得先记的是:
GPT 不是一下子就“会聊天”,而是先在“预测下一个 token”这条主线上不断扩规模、扩能力。
后面大家熟悉的对话助手、指令跟随和 Agent 能力,都是建立在这条生成主线继续演化出来的。
一、GPT 到底在做什么?
1.1 最朴素的一句话
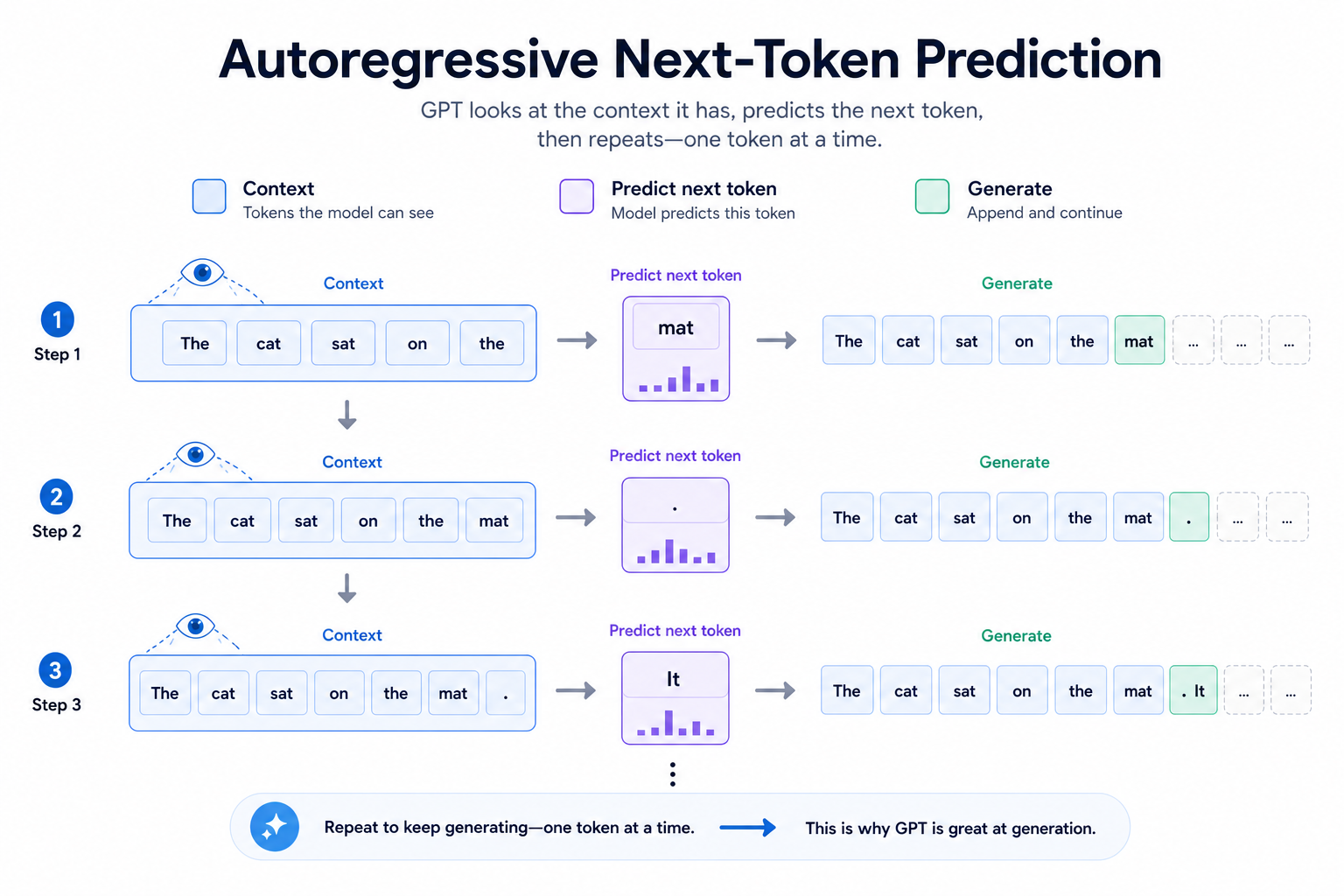
GPT 路线最本质的目标是:
给定前文,预测下一个 token。
例如:
输入:
“北京是中国的”
模型会倾向于预测:
“首都”
这看起来很简单,但如果你把这个动作反复做很多次:
- 预测一个 token
- 把它接到上下文后面
- 再预测下一个 token
就能一步步生成完整文本。
1.2 为什么这条路线这么强?
因为“预测下一个 token”这个目标非常通用:
- 可以学语言规律
- 可以学知识模式
- 可以学代码结构
- 可以学推理轨迹
所以 GPT 的强大,不是因为它一开始就会聊天,而是因为:
它先学会了大规模的语言生成规律。
1.3 一个更适合新人的总类比
你可以把 GPT 理解成:
- 一个非常会“顺着前文接着写”的选手
它不一定先擅长:
- 做最严谨的结构化理解题
但它非常擅长:
- 根据已经给出的上下文,继续往下生成合理内容
这就是为什么 GPT 路线天然更容易长成:
- 对话
- 写作
- 代码补全
二、GPT 和 BERT 的根本区别
2.1 一张表先记住
| 模型路线 | 核心方式 | 更擅长 |
|---|---|---|
| BERT | 双向看上下文 | 理解、匹配、抽取 |
| GPT | 只看左侧历史,自回归生成 | 续写、对话、生成 |
2.2 为什么 GPT 不能偷看右边?
因为它训练时必须保持和生成时一致。
生成时,未来内容还没出现,所以训练时也不能偷偷看未来 token。
这就是所谓的 causal / autoregressive 约束。
三、因果掩码(causal mask)为什么是 GPT 的关键?
3.1 一个直觉理解
在 GPT 里,当模型正在预测第 t 个位置时:
- 可以看
1 ~ t-1 - 不能看
t+1之后
这就像你做完形填空:
- 只能看前面已经写好的内容
- 不能偷看答案栏
3.2 一个最小 mask 示例
import numpy as np
seq_len = 5
mask = np.tril(np.ones((seq_len, seq_len), dtype=int))
print(mask)
输出会是一个下三角矩阵:
[[1 0 0 0 0]
[1 1 0 0 0]
[1 1 1 0 0]
[1 1 1 1 0]
[1 1 1 1 1]]
它表示:
- 第 1 个位置只能看自己
- 第 2 个位置看前两个
- 第 5 个位置看前五个
这就是 GPT 训练和生成的一致性来源。
3.3 一个很适合初学者先记的对比表
| 问题 | GPT 的回答方式 |
|---|---|
| 训练时能不能看未来 token? | 不能 |
| 生成时能不能看未来 token? | 也不能 |
| 为什么这样设计? | 保证训练和生成一致 |
这个表很适合新人,因为它会把“causal mask”从一个术语,重新变成一个非常朴素的约束:
- 不能偷看后面的答案
四、一个真正��有教学意义的最小 GPT 示例:bigram 语言模型
4.1 为什么先看 bigram?
因为它虽然非常简单,但已经能让你亲眼看到:
- 什么叫“根据前文预测下一个词”
- 什么叫“自回归生成”
4.2 可运行示例
from collections import defaultdict, Counter
import random
corpus = [
"我 爱 AI",
"我 爱 Python",
"你 爱 AI",
"我们 爱 学习"
]
transitions = defaultdict(Counter)
for sentence in corpus:
tokens = sentence.split()
for a, b in zip(tokens[:-1], tokens[1:]):
transitions[a][b] += 1
def sample_next(token):
candidates = transitions[token]
if not candidates:
return None
words = list(candidates.keys())
weights = list(candidates.values())
return random.choices(words, weights=weights, k=1)[0]
def generate(start, max_steps=5):
tokens = [start]
current = start
for _ in range(max_steps):
nxt = sample_next(current)
if nxt is None:
break
tokens.append(nxt)
current = nxt
return " ".join(tokens)
for _ in range(5):
print(generate("我"))
4.3 这段代码到底在教什么?
它在教你 GPT 的最小骨架:
- 根据前文决定下一个词分布
- 从分布里采样
- 把采样结果接回去
- 再继续生成
这已经是“自回归生成”的最小原型。
当然,真实 GPT 比这个复杂无数倍,但主线是一样的。
4.4 第一次学 GPT 时,最稳的默认顺序
更稳的顺序通常是:
- 先理解“预测下一个 token”这句话
- 先看 causal mask 为什么必要
- 先用 bigram 这种最小模型建立自回归直觉
- 最后再去看 GPT-1 / 2 / 3 的规模演化
这样会比一上来就盯模型参数和发布时间更容易看懂主线。
五、GPT 为什么是 decoder-only?
5.1 因为它最核心的任务就是逐步生成
GPT 系列通常基于 decoder-only Transformer:
- 每个位置只看左边
- 通过 causal mask 保证不偷看未来
- 每步输出下一个 token 的分布
这和 encoder-only(比如 BERT)最大的区别在于:
GPT 的结构天然服务于“续写和生成”。
5.2 一个离线随机初始化的小型 GPT 形状示例
如果你想更直观地感受“decoder-only LM”的输出,可以用本地随机初始化的小模型,不依赖下载权重:
pip install torch transformers
import torch
from transformers import GPT2Config, GPT2LMHeadModel
config = GPT2Config(
vocab_size=100,
n_positions=16,
n_ctx=16,
n_embd=32,
n_layer=2,
n_head=4
)
model = GPT2LMHeadModel(config)
input_ids = torch.tensor([
[1, 7, 9, 12, 5],
[1, 3, 4, 8, 0]
])
outputs = model(input_ids=input_ids)
logits = outputs.logits
print("input_ids shape:", input_ids.shape)
print("logits shape :", logits.shape)
这里的 logits.shape 会是:
[batch, seq_len, vocab_size]
意思是:
对每个位置,模型都在预测“下一个 token 的分布”。
六、什么是 in-context learning?
6.1 GPT 为什么后来越来越像“会临场学规则”?
随着模型变大,GPT 路线逐渐展现出一个很重要的能力:
不改参数,只在上下文里给几个示例,它也能临时学着做。
例如:
输入: 苹果 很 好吃
输出: positive
输入: 这门课 太 乱 了
输出: negative
输入: 老师 讲得 很 清楚
输出:
模型就可能继续补出:
positive
这就是 in-context learning 的味道。
6.2 为什么这很重要?
因为它意味着:
- 不一定每个任务都要重新训练模型
- Prompt 本身就能成为一种临时任务配置方式
这为后面的 Prompt 工程、Agent 和工具调用铺了很大一条路。
七、GPT 系列是怎么一步步演化的?
7.1 粗略脉络
可以先用这条线记住:
- 先做更强的自回归语言模型
- 模型越大,通用生成能力越强
- 再通过指令微调、对齐、偏好优化
- 最后变成更像“助手”的形态
7.2 从“会续写”到“会配合”
早期 GPT 更像:
- 强大的�文本续写模型
后来经过:
- 指令微调
- 偏好学习
- 安全对齐
它才逐渐变成了今天这种更会跟人协作的聊天助手。
也就是说:
GPT 的聊天能力,不只是来自预训练,还来自后续对齐。
八、GPT 最擅长什么?又不擅长什么?
8.1 擅长
- 文本生成
- 对话
- 摘要
- 改写
- 代码生成
- 开放式续写
8.2 不天然擅长
- 严格事实检索
- 长期稳定记忆
- 需要强约束的结构化执行
所以在真实系统里,经常要给 GPT 搭配:
- RAG
- 工具调用
- 记忆系统
- 护栏
如果把它做成笔记或项目,最值得展示什么
最值得展示的通常不是:
- “GPT 很强”
而是:
- next-token prediction 到自回归生成的主线
- causal mask 为什么让训练和生成保持一致
- GPT-1 / 2 / 3 代表的能力演化
- 为什么它后面还需要 Prompt、RAG、工具和对齐系统
这样别人会更容易看出:
- 你理解的是 GPT 的能力骨架
- 不只是知道它很热门
九、初学者最常踩的坑
9.1 以为 GPT 就是“会聊天的模型”
聊天只是表层。
根部是自回归语言建模。
9.2 以为 GPT 训练时也能双向看上下文
不是。
GPT 的关键约束就是不能偷看未来。
9.3 只知道“模型很大”,不知道它的输出张量在表达什么
真正要记住的是:
- 每个位置都在预测下一个 token 分布
- 生成是一步步滚动出来的
小结
这一节最重要的不是记住某一代 GPT 的名字,而是抓住这条主线:
GPT = decoder-only + causal mask + next-token prediction + 自回归生成。
理解了这条主线,你后面再学 Prompt、Agent、工具调用和大模型应用时,就会知道它们到底是建立在什么能力之上。
练习
- 改一下 bigram 示例的语料,观察生成结果如何变化。
- 用自己的话解释:为什么 causal mask 对 GPT 是必须的?
- 看懂随机初始化 GPT 示例里的
logitsshape,它为什么会是[batch, seq_len, vocab_size]? - 想一想:为什么说 GPT 的“会聊天”能力,不能简单等同于“只是会预测下一个词”?