词嵌入
做 NLP 时,模型并不直接理解“退款”“证书”“密码”这些词本身。
它首先看到的是:
- 一串编号
- 再变成一串向量
词嵌入的价值就在这里:
让词不只是有编号,还能在向量空间里表现出语义关系。
如果这层没真正理解清楚,后面学上下文表示、BERT 和检索向量时都会发虚。
学习目标
- 理解 one-hot 表示为什么不够
- 理解词嵌入为什么能表达相似性
- 掌握余弦相似度这类最常见的相似度直觉
- 通过可运行示例建立“词向量空间”第一层感觉
历史背景:Word2Vec 为什么会变成 NLP 的关键节点?
这一节最值得知道的历史节点是:
| 年份 | 论文 / 方法 | 关键作者 | 它最重要地解决了什么 |
|---|---|---|---|
| 2013 | Word2Vec | Mikolov 等 | 让词开始有分布式语义表示,推动 NLP 从“词是否出现”走向“词之间的关系也可计算” |
对新人来说,最值得先记的是:
Word2Vec 的意义,不只是“词向量更酷”,而是它让“语义相近”第一次在向量空间里变成可计算的关系。
先建立一张地图
如果你刚学完 one-hot、BoW、TF-IDF,这一节最自然的续接就是:
- 前面的方法已经能把文本变成数字
- 这一节开始解决“这些数字怎么开始带上语义关系”
所以这节真正重要的不是“又一种表示法”,而是:
- 表示开始从“能算”升级成“更像有语义结构”
词嵌入这节最适合新人的理解顺序不是“直接记住几个向量方法”,而是先看清:
所以这节真正想解决的是:
- 为什么 one-hot 不够
- 为什么“词和词的关系”要变成可计算的距离
一个更适合新人的总类比
你可以把这些表示方法理解成:
- one-hot 像给每个词发一个工号
- 词嵌入像把每个词放进一张“语义地图”
工号当然能区分谁是谁,
但你看不出:
- 哪些词彼此更像
- 哪些词经常在同一类场景里出现
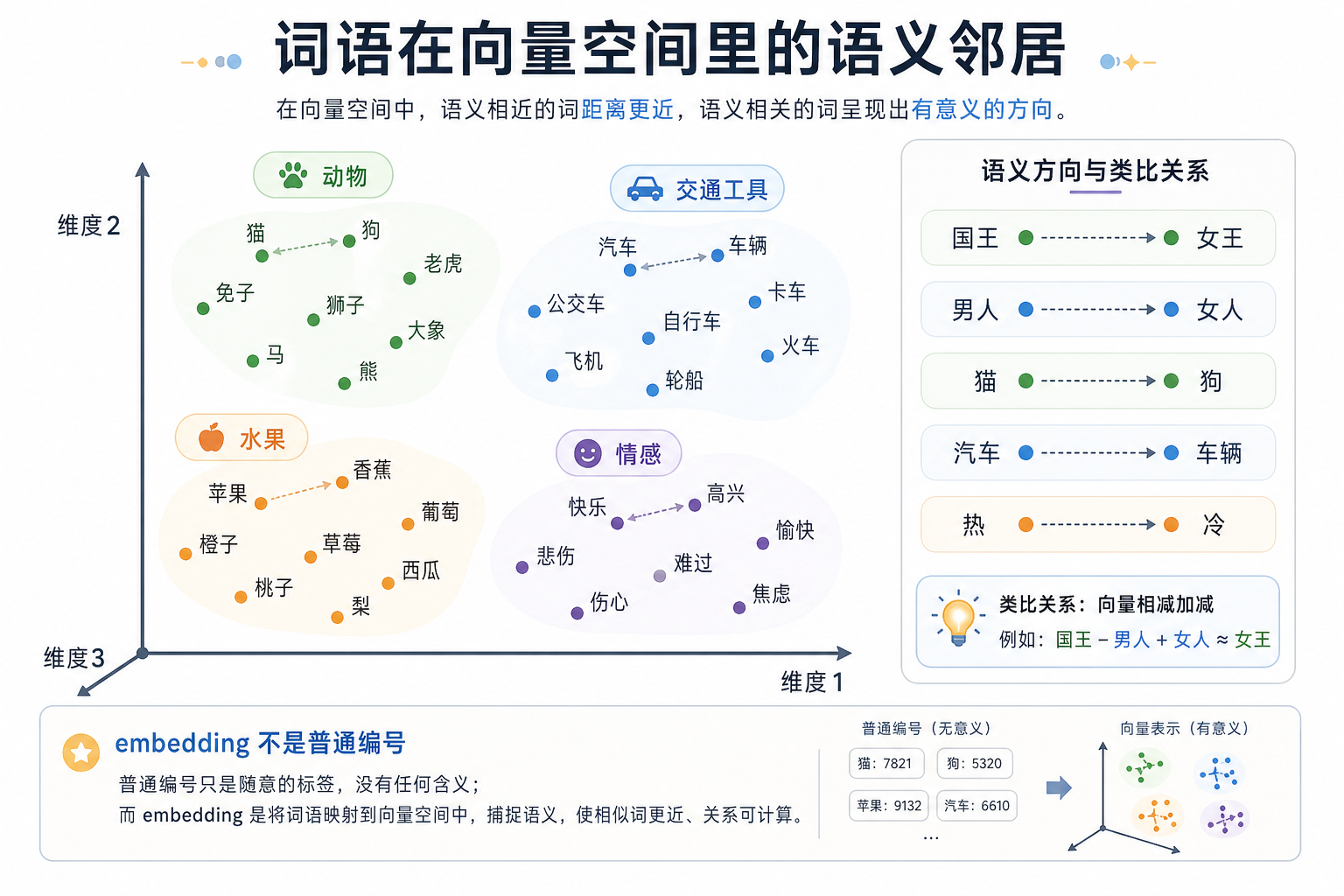
而一旦变成地图坐标,“近”这件事就第一次能被算出来。
一、为什么我们需要词嵌入?
1.1 one-hot 只能区分身份,不能表达关系
假设词表里有:
退款退货密码
如果用 one-hot:
退款可能是[1, 0, 0]退货可能是[0, 1, 0]密码可能是[0, 0, 1]
问题在于:
退款和退货语义明明更近- 但在 one-hot 里,它们彼此同样“远”
1.2 词嵌入在做什么?
词嵌入要做的是:
- 把词映射成低维向量
- 让语义相近的词在向量空间里更靠近
也就是说,它不只是“编码”,更是在做:
- 语义表示
1.3 一个类比
你可以把词嵌入理解成地图坐标。
- one-hot 更像身份证号
- 词嵌入更像地图位置
身份证号能区分人,但看不出谁和谁住得近;
地图坐标则能让“近”这件事变得可计算。
1.4 第一次学词嵌入,最该先抓住什么?
最该先抓住的不是训练方法,而是这句:
词嵌入最重要的价值,是把“词和词之间的关系”也带进表示里。
这句话一旦稳住,后面:
- 余弦相似度
- 邻近词
- 上下文化表示
都会更容易理解。
二、词嵌入是怎么学出语义的?
2.1 核心假设:上下文相似,词义常常也相近
如果两个词经常出现在相似上下文里,
模型就会倾向把它们学成相近向量。
例如:
退款退货
可能都常出现在:
- 售后
- 订单
- 申请
这就会推动它们在空间里更靠近。
2.2 向量“靠近”不等于完全同义
它更常表示:
- 用法接近
- 上下文分布接近
所以词嵌入里的“近”,很多时候是分布意义上的近,不一定是严格词典意义上的同义。
2.3 为什么这已经很有价值?
因为一旦有了这种空间关系,
很多任务就能利用它:
- 相似词查找
- 文本分类
- 检索
- 聚类
2.4 为什么说“分布相似”这件事会改变 NLP 主线?
因为从这里开始,模型不再只会问:
- 这个词是不是出现了
它开始更容易问:
- 这个词通常和哪些上下文一起出现
- 它在语义空间里更像哪一类词
这正是后面表示学习一路往深处走的开端。
三、先跑一个词向量相似度示例
下面这个例子会做三件事:
- 给几个词定义一个小型嵌入
- 计算它们的余弦相似度
- 比较哪些词更接近
from math import sqrt
embeddings = {
"refund": [0.90, 0.80, 0.10],
"return": [0.88, 0.78, 0.12],
"invoice": [0.15, 0.85, 0.20],
"password": [0.10, 0.15, 0.95],
}
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = sqrt(sum(x * x for x in a))
norm_b = sqrt(sum(x * x for x in b))
return dot / (norm_a * norm_b)
print("refund vs return :", round(cosine(embeddings["refund"], embeddings["return"]), 4))
print("refund vs invoice :", round(cosine(embeddings["refund"], embeddings["invoice"]), 4))
print("refund vs password:", round(cosine(embeddings["refund"], embeddings["password"]), 4))
3.1 这个例子最重要的直觉是什么?
你会看到:
refund和return更近- 和
password更远
这正是词嵌入最关键的直觉:
“语义近��”可以转化为“向量近”。
3.2 为什么这里用余弦相似度?
因为我们常常更关心:
- 方向是否接近
而不是绝对长度。
余弦相似度正好适合这种比较。
3.3 新人第一次学词嵌入,最该先记什么?
最值得先记住的是:
- one-hot 更像编号,不像语义表示
- 词嵌入的价值是把“语义近”转成“向量近”
- 后面很多 NLP 模型第一步,本质上还是在用 embedding
3.4 再看一个最小“找邻近词”示例
from math import sqrt
embeddings = {
"refund": [0.90, 0.80, 0.10],
"return": [0.88, 0.78, 0.12],
"invoice": [0.15, 0.85, 0.20],
"password": [0.10, 0.15, 0.95],
}
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = sqrt(sum(x * x for x in a))
norm_b = sqrt(sum(x * x for x in b))
return dot / (norm_a * norm_b)
target = "refund"
neighbors = []
for word, vector in embeddings.items():
if word == target:
continue
neighbors.append((word, round(cosine(embeddings[target], vector), 4)))
neighbors.sort(key=lambda x: x[1], reverse=True)
print(neighbors)
这个示例很适合初学者,因为它能马上把一个抽象概念变得具体:
- 如果向量真的带了语义关系
- 那你就应该能从空间里把“更像的词”找出来
四、词嵌入为什么对后续任务有帮助?
4.1 文本分类
如果“退款”和“退货”向量接近,
模型更容易把它们一起学进“售后类”。
4.2 相似文本检索
如果一段文本由很多相似词组成,
它在向量空间里通常也更接近同主题内容。
4.3 下游深度模型输入
很多模型第一层本质上还是:
- token id -> embedding vector
所以词嵌入不是旧知识,而是后面更复杂模型的入口。
4.4 这一节为什么会直接连到后面的预训练主线?
因为你后面看到的大多数 NLP 模型,第一步仍然会做类似的事:
- 先把 token 变成向量表示
区别只是:
- 固定 embedding 更静态
- 上下文化表示更动态
- 预训练模型会把这套表示能力规模化地学得更强
4.5 如果你第一次把 embedding 放进项目里,最稳的默认用法
更稳的用法通常是:
- 先把词变成向量
- 先看相似词和相似句子是否合理
- 再把 embedding 接到分类、检索或聚类里
这样会比一开始就直接上复杂模型更容易建立手感。
五、词嵌入最容易踩的坑
5.1 误区一:词嵌入等于词典释义
不是。
它更像统计语义空间,不是词典定义表。
5.2 误区二:词向量一旦学好就什么都能解决
词嵌入只能表达基础语义关系��。
遇到多义词和复杂上下文时,很快就不够了。
5.3 误区三:只看单个词,不看任务
词嵌入的价值最终还是要放回具体任务里判断。
小结
这节最重要的,是把词嵌入理解成:
一种把离散词汇映射到连续语义空间的方式,让“相近词”在向量上也更接近。
一旦这个直觉建立起来,
你后面再看上下文表示、句向量和语言模型时就会顺很多。
这节最该带走什么
- 词嵌入不是给词换个编号,而是在给词建立语义空间位置
- 余弦相似度是理解这层语义空间最重要的第一把钥匙
- 后面上下文化表示和预训练模型,其实都是在这条路上继续往前走
如果再压成一句话,那就是:
词嵌入的意义,不在于把词变短,而在于让词和词之间终于开始有了可计算的语义距离。
练习
- 给示例再加一个词
delivery,自己决定它的向量,并观察它和其他词的相似度。 - 为什么说 one-hot 能区分词,但不能表达词和词之间的关系?
- 用自己的话解释:余弦相似度为什么适合比较词向量?
- 想一想:如果一个词经常出现在多个不同语境里,仅靠固定词向量会遇到什么问题?