6.3.6 CNN 实战:图像分类
本节定位
这是“把前面内容串起来”的一节。你会创建一个小型图像数据集,训练 CNN,做验证,检查预测结果,并判断下一步该尝试什么。
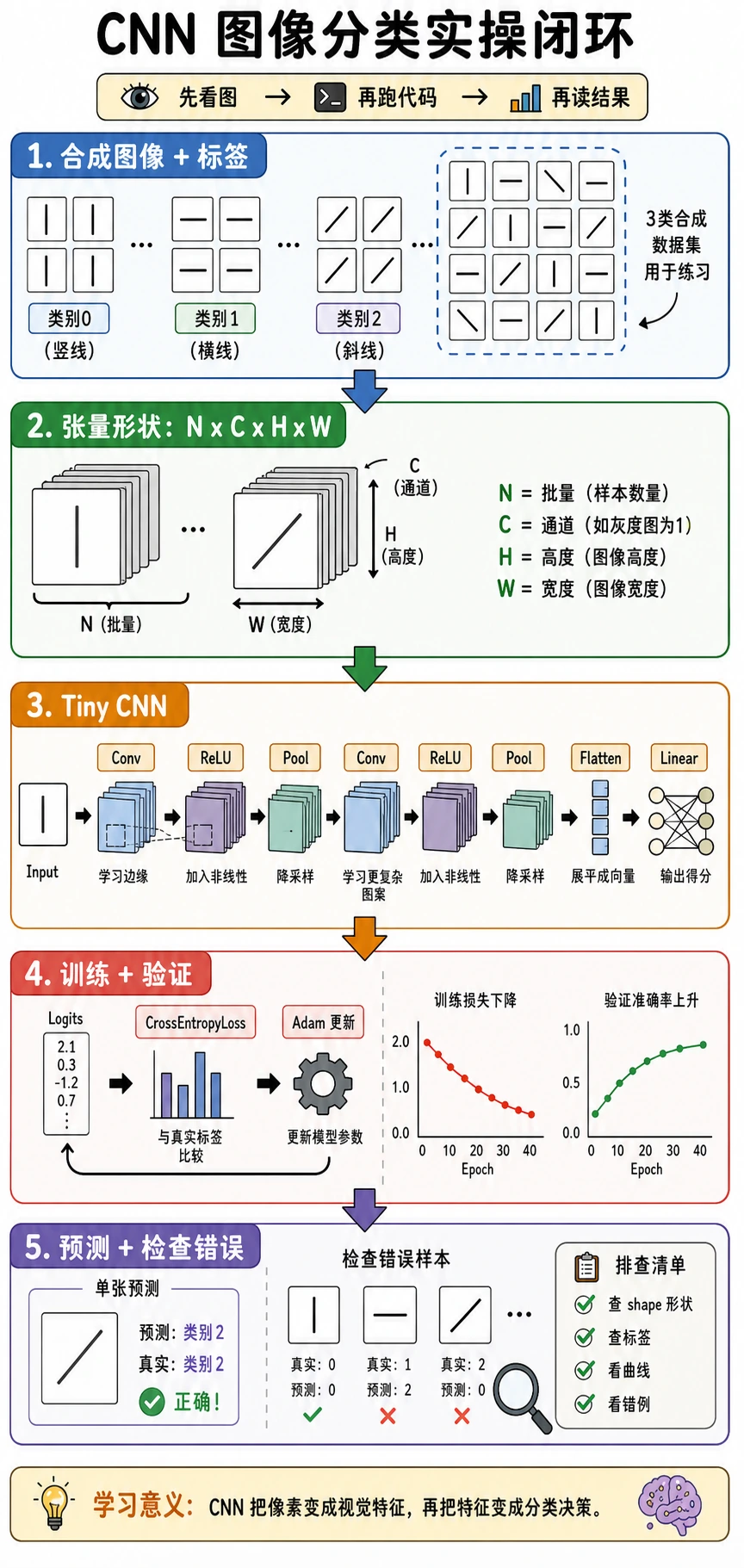
学习目标
- 搭建完整图像分类流程。
- 保持图像张量为
[N, C, H, W]格式。 - 用
CrossEntropyLoss训练并验证 CNN。 - 检查混淆矩阵和单样本概率。
- 理解从玩具任务迁移到真实图片时会增加什么工作。
最小闭环
一个图像分类项目需要:
图像 -> 标签 -> 训练/验证切分 -> CNN -> loss -> optimizer -> metrics -> 错例检查
不要跳过验证和错例检查。模型能“跑起来”,不等于它真的学到了正确规律。
完整实验:训练四分类 CNN
这个实验使用四个简单类别:
| Label | Pattern |
|---|---|
0 | 竖线 |
1 | 横线 |
2 | 主对角线 |
3 | 反对角线 |
运行完整脚本:
import numpy as np
import torch
from torch import nn
SEED = 42
np.random.seed(SEED)
torch.manual_seed(SEED)
CLASS_NAMES = ["vertical", "horizontal", "diag_down", "diag_up"]
def make_image(label, size=16, noise=0.08):
img = np.zeros((size, size), dtype=np.float32)
c = size // 2
if label == 0:
img[:, c] = 1.0
elif label == 1:
img[c, :] = 1.0
elif label == 2:
for i in range(size):
img[i, i] = 1.0
elif label == 3:
for i in range(size):
img[i, size - 1 - i] = 1.0
img += np.random.randn(size, size).astype(np.float32) * noise
return np.clip(img, 0.0, 1.0)
def make_dataset(per_class=120):
X, y = [], []
for label in range(len(CLASS_NAMES)):
for _ in range(per_class):
X.append(make_image(label))
y.append(label)
X = np.array(X, dtype=np.float32)
y = np.array(y, dtype=np.int64)
idx = np.random.permutation(len(X))
X = torch.tensor(X[idx]).unsqueeze(1)
y = torch.tensor(y[idx])
split = int(len(X) * 0.8)
return X[:split], y[:split], X[split:], y[split:]
class TinyCNNClassifier(nn.Module):
def __init__(self, num_classes=4):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(8, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
)
self.head = nn.Linear(32, num_classes)
def forward(self, x):
x = self.features(x)
x = x.flatten(1)
return self.head(x)
def accuracy(logits, y):
return (logits.argmax(dim=1) == y).float().mean().item()
def confusion_matrix(pred, y, num_classes):
matrix = torch.zeros(num_classes, num_classes, dtype=torch.int64)
for true_label, pred_label in zip(y, pred):
matrix[true_label, pred_label] += 1
return matrix
X_train, y_train, X_val, y_val = make_dataset()
print("data_lab")
print("train:", tuple(X_train.shape), tuple(y_train.shape))
print("val :", tuple(X_val.shape), tuple(y_val.shape))
model = TinyCNNClassifier(num_classes=len(CLASS_NAMES))
with torch.no_grad():
z = X_train[:4]
print("shape_lab")
print("input:", tuple(z.shape))
print("features:", tuple(model.features(z).shape))
print("logits:", tuple(model(z).shape))
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(1, 81):
model.train()
train_logits = model(X_train)
train_loss = loss_fn(train_logits, y_train)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch == 1 or epoch % 20 == 0:
model.eval()
with torch.no_grad():
val_logits = model(X_val)
val_loss = loss_fn(val_logits, y_val)
print(
f"epoch={epoch:02d} "
f"train_loss={train_loss.item():.4f} "
f"val_loss={val_loss.item():.4f} "
f"train_acc={accuracy(train_logits, y_train):.3f} "
f"val_acc={accuracy(val_logits, y_val):.3f}"
)
model.eval()
with torch.no_grad():
val_logits = model(X_val)
val_pred = val_logits.argmax(dim=1)
cm = confusion_matrix(val_pred, y_val, len(CLASS_NAMES))
probs = torch.softmax(val_logits[0], dim=0)
print("confusion_matrix rows=true cols=pred")
print(cm)
print("sample_prediction")
print("true:", CLASS_NAMES[y_val[0].item()])
print("pred:", CLASS_NAMES[val_pred[0].item()])
print("probs:", [round(v, 3) for v in probs.tolist()])
预期输出:
data_lab
train: (384, 1, 16, 16) (384,)
val : (96, 1, 16, 16) (96,)
shape_lab
input: (4, 1, 16, 16)
features: (4, 32, 1, 1)
logits: (4, 4)
epoch=01 train_loss=1.3883 val_loss=1.3776 train_acc=0.245 val_acc=0.188
epoch=20 train_loss=0.0193 val_loss=0.0080 train_acc=1.000 val_acc=1.000
epoch=40 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
epoch=60 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
epoch=80 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
confusion_matrix rows=true cols=pred
tensor([[30, 0, 0, 0],
[ 0, 22, 0, 0],
[ 0, 0, 18, 0],
[ 0, 0, 0, 26]])
sample_prediction
true: vertical
pred: vertical
probs: [1.0, 0.0, 0.0, 0.0]

读懂输出
| 输出 | 含义 |
|---|---|
train: (384, 1, 16, 16) | 384 张灰度训练图像 |
features: (4, 32, 1, 1) | CNN 把每张图压缩成 32 个特征值 |
logits: (4, 4) | 4 个样本,每个样本 4 个类别分数 |
val_acc=1.000 | 模型学会了这个简单验证集 |
| 混淆矩阵对角线 | 真实类别和预测类别一致 |
混淆矩阵按行读:行是真实标签,列是预测标签。非对角线数字就是错误。
为什么这里用 GAP?
模型使用 AdaptiveAvgPool2d((1, 1)),在这里可以理解为 Global Average Pooling。它把 [N, 32, H, W] 变成 [N, 32, 1, 1]。
这样分类头很小:
[N, 32, 1, 1] -> flatten -> [N, 32] -> Linear(32, 4)
对本节来说,GAP 还能避免脆弱的手写尺寸计算,比如 16 * 3 * 3。
如何诊断结果
| 现象 | 可能原因 | 下一步 |
|---|---|---|
| train 和 val 都差 | 模型太弱、标签错、LR 有问题 | 打印 shape,检查样本,调整 LR |
| train 好但 val 差 | 过拟合或切分不合理 | 加数据、增强、正则化 |
| loss 不动 | 标签错、没有梯度、LR 太小 | 检查 loss.backward()、标签、可训练参数 |
| 高置信度错判 | 数据偏差或模式泄漏 | 检查样本和类别分布 |
| 只预测一个类别 | 类别不平衡或优化问题 | 打印类别计数和 logits |
从玩具任务到真实图片
本节故意使用小型合成数据。真实项目还会增加:
Dataset和DataLoader;- 图像文件读取;
- 按来源切分 train/validation/test;
- 数据增强;
- 预训练 backbone 或迁移学习;
- 模型 checkpoint;
- precision、recall、每类准确率等更丰富指标。
流程是一样的,只是工具更严肃。
常见错误
| 错误 | 修复 |
|---|---|
| 只看训练 loss | 一定要计算验证指标 |
| 忘记 channel 维度 | 使用 [N, C, H, W] |
在 CrossEntropyLoss 前先 softmax | 把原始 logits 传给 CrossEntropyLoss |
| 忽略错例 | 检查混淆矩阵和样本 |
| 验证集太像训练集 | 真实图片要按来源切分 |
练习
- 把
noise从0.08增加到0.25,验证结果如何变化? - 把
per_class从120减到10,模型还能泛化吗? - 去掉
AdaptiveAvgPool2d,改用Flattenhead。Linear应该接收什么 shape? - 再增加一类,比如方框边界。
- 如果有错例,打印前 5 个验证集错例。
小结
- 完整图像分类闭环包括数据、标签、切分、模型、loss、指标和错例分析。
- PyTorch 中 CNN 输入使用
[N, C, H, W]。 CrossEntropyLoss期待 logits,不是概率。- GAP 能让分类头更紧凑,也更不容易写错 shape。
- 验证和错误分析是模型工作的一部分,不是附加项。