6.3.6 CNN 実践:画像分類
この節の位置づけ
ここは、これまでの内容をまとめて動かす節です。小さな画像データセットを作り、CNN を学習し、検証し、予測を確認し、次に何を試すべきかを判断します。
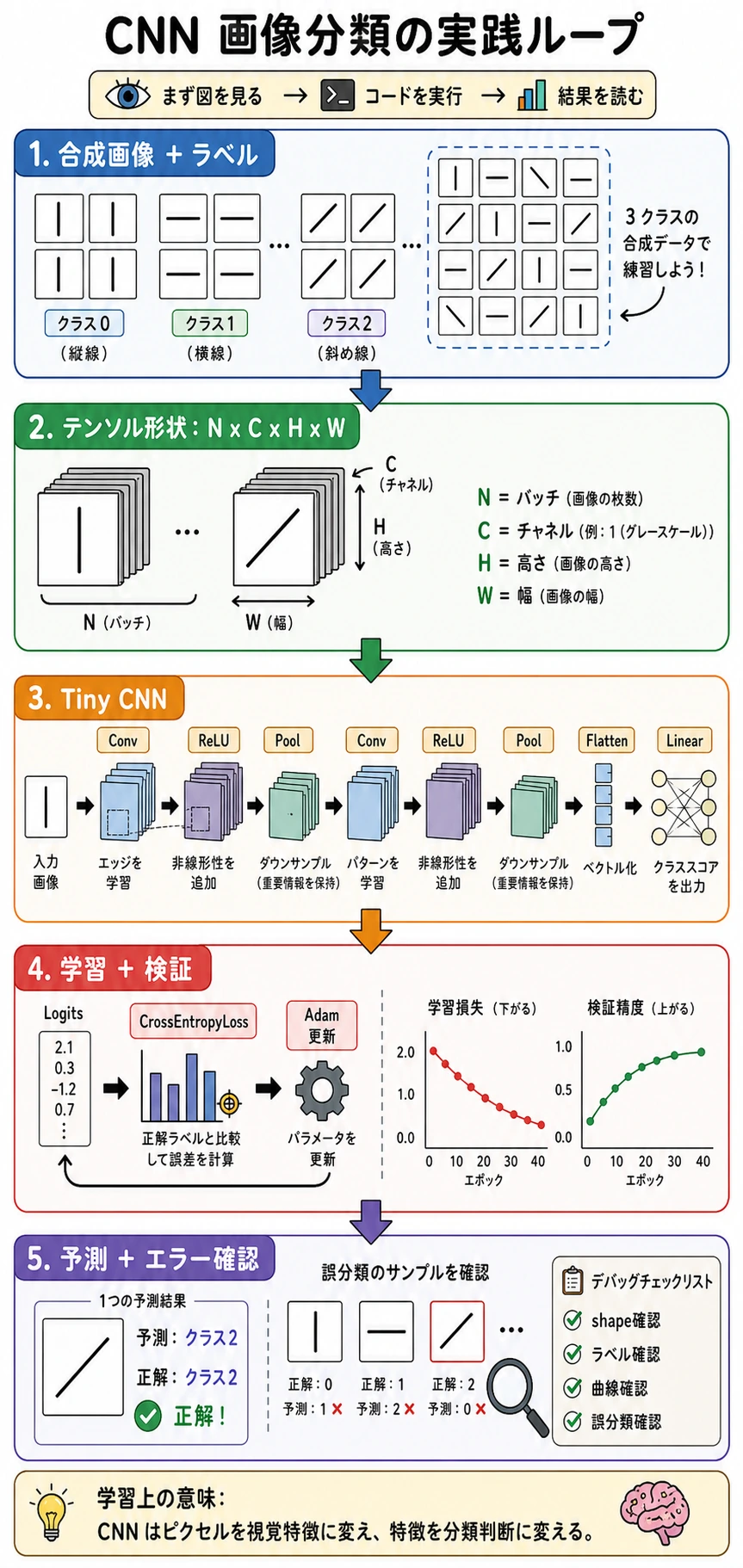
学習目標
- 画像分類の完整なワークフローを作る。
- 画像 tensor を
[N, C, H, W]形式で扱う。 CrossEntropyLossで CNN を学習・検証する。- 混同行列と単一サンプルの確率を確認する。
- この toy task から実画像へ進むと何が増えるかを理解する。
最小の閉じた流れ
画像分類プロジェクトには、次の流れが必要です。
画像 -> ラベル -> train/validation split -> CNN -> loss -> optimizer -> metrics -> 誤分類確認
検証と誤分類確認を飛ばしてはいけません。モデルが「動く」ことと、正しい手がかりを学んだことは別です。
完整な実験:4 クラス CNN を学習する
この実験では、4 つの単純なクラスを使います。
| Label | Pattern |
|---|---|
0 | 縦線 |
1 | 横線 |
2 | 右下がり対角線 |
3 | 右上がり対角線 |
完整なスクリプトを実行します。
import numpy as np
import torch
from torch import nn
SEED = 42
np.random.seed(SEED)
torch.manual_seed(SEED)
CLASS_NAMES = ["vertical", "horizontal", "diag_down", "diag_up"]
def make_image(label, size=16, noise=0.08):
img = np.zeros((size, size), dtype=np.float32)
c = size // 2
if label == 0:
img[:, c] = 1.0
elif label == 1:
img[c, :] = 1.0
elif label == 2:
for i in range(size):
img[i, i] = 1.0
elif label == 3:
for i in range(size):
img[i, size - 1 - i] = 1.0
img += np.random.randn(size, size).astype(np.float32) * noise
return np.clip(img, 0.0, 1.0)
def make_dataset(per_class=120):
X, y = [], []
for label in range(len(CLASS_NAMES)):
for _ in range(per_class):
X.append(make_image(label))
y.append(label)
X = np.array(X, dtype=np.float32)
y = np.array(y, dtype=np.int64)
idx = np.random.permutation(len(X))
X = torch.tensor(X[idx]).unsqueeze(1)
y = torch.tensor(y[idx])
split = int(len(X) * 0.8)
return X[:split], y[:split], X[split:], y[split:]
class TinyCNNClassifier(nn.Module):
def __init__(self, num_classes=4):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(8, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
)
self.head = nn.Linear(32, num_classes)
def forward(self, x):
x = self.features(x)
x = x.flatten(1)
return self.head(x)
def accuracy(logits, y):
return (logits.argmax(dim=1) == y).float().mean().item()
def confusion_matrix(pred, y, num_classes):
matrix = torch.zeros(num_classes, num_classes, dtype=torch.int64)
for true_label, pred_label in zip(y, pred):
matrix[true_label, pred_label] += 1
return matrix
X_train, y_train, X_val, y_val = make_dataset()
print("data_lab")
print("train:", tuple(X_train.shape), tuple(y_train.shape))
print("val :", tuple(X_val.shape), tuple(y_val.shape))
model = TinyCNNClassifier(num_classes=len(CLASS_NAMES))
with torch.no_grad():
z = X_train[:4]
print("shape_lab")
print("input:", tuple(z.shape))
print("features:", tuple(model.features(z).shape))
print("logits:", tuple(model(z).shape))
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(1, 81):
model.train()
train_logits = model(X_train)
train_loss = loss_fn(train_logits, y_train)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch == 1 or epoch % 20 == 0:
model.eval()
with torch.no_grad():
val_logits = model(X_val)
val_loss = loss_fn(val_logits, y_val)
print(
f"epoch={epoch:02d} "
f"train_loss={train_loss.item():.4f} "
f"val_loss={val_loss.item():.4f} "
f"train_acc={accuracy(train_logits, y_train):.3f} "
f"val_acc={accuracy(val_logits, y_val):.3f}"
)
model.eval()
with torch.no_grad():
val_logits = model(X_val)
val_pred = val_logits.argmax(dim=1)
cm = confusion_matrix(val_pred, y_val, len(CLASS_NAMES))
probs = torch.softmax(val_logits[0], dim=0)
print("confusion_matrix rows=true cols=pred")
print(cm)
print("sample_prediction")
print("true:", CLASS_NAMES[y_val[0].item()])
print("pred:", CLASS_NAMES[val_pred[0].item()])
print("probs:", [round(v, 3) for v in probs.tolist()])
期待される出力:
data_lab
train: (384, 1, 16, 16) (384,)
val : (96, 1, 16, 16) (96,)
shape_lab
input: (4, 1, 16, 16)
features: (4, 32, 1, 1)
logits: (4, 4)
epoch=01 train_loss=1.3883 val_loss=1.3776 train_acc=0.245 val_acc=0.188
epoch=20 train_loss=0.0193 val_loss=0.0080 train_acc=1.000 val_acc=1.000
epoch=40 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
epoch=60 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
epoch=80 train_loss=0.0000 val_loss=0.0000 train_acc=1.000 val_acc=1.000
confusion_matrix rows=true cols=pred
tensor([[30, 0, 0, 0],
[ 0, 22, 0, 0],
[ 0, 0, 18, 0],
[ 0, 0, 0, 26]])
sample_prediction
true: vertical
pred: vertical
probs: [1.0, 0.0, 0.0, 0.0]
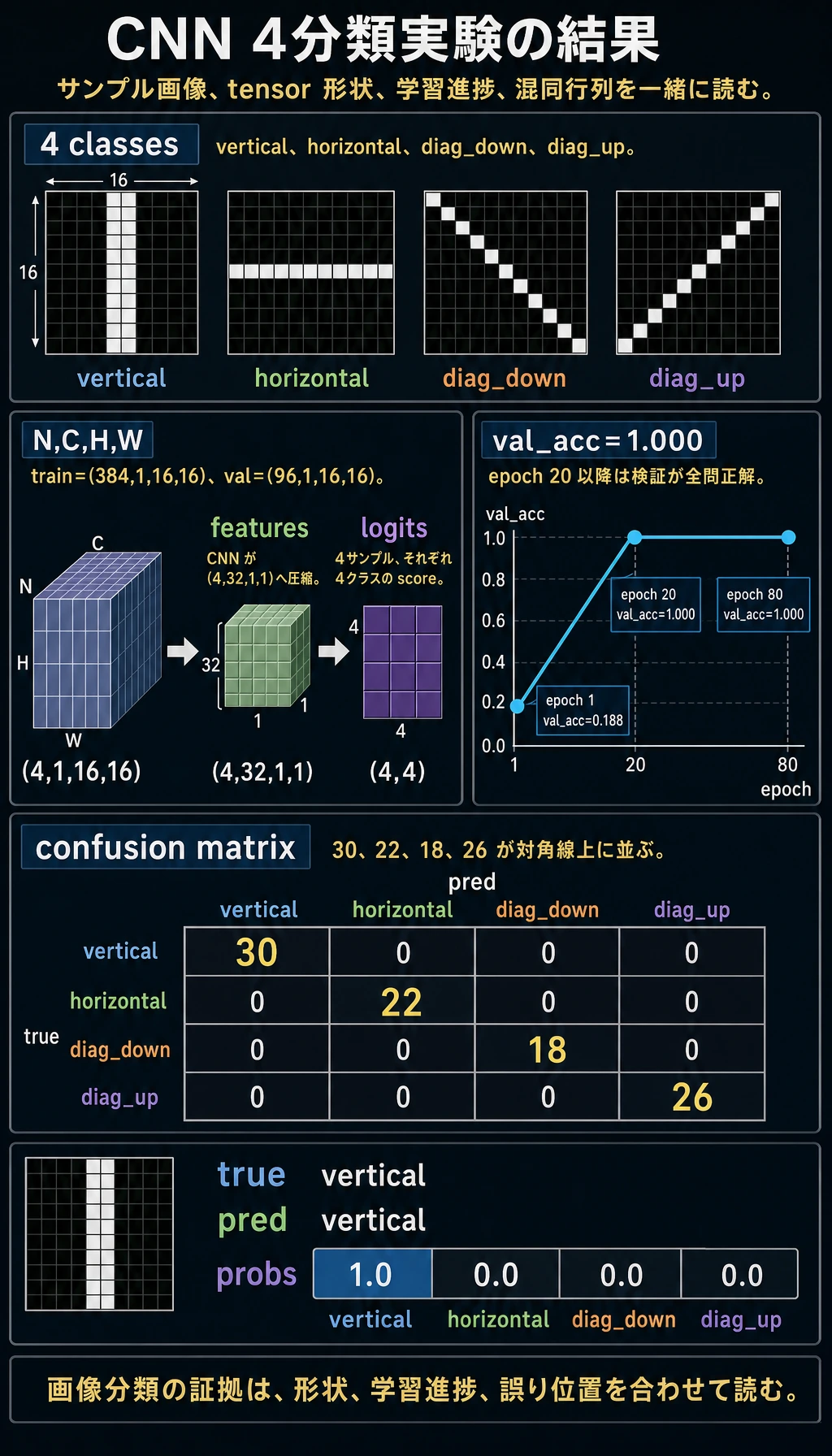
出力を読む
| 出力 | 意味 |
|---|---|
train: (384, 1, 16, 16) | 384 枚のグレースケール訓練画像 |
features: (4, 32, 1, 1) | CNN が各画像を 32 個の特徴値へ圧縮した |
logits: (4, 4) | 4 サンプル、それぞれ 4 クラススコア |
val_acc=1.000 | この単純な検証セットを学習できた |
| 混同行列の対角線 | 真のクラスと予測クラスが一致している |
混同行列は行ごとに読みます。行が真のラベル、列が予測ラベルです。対角線以外の数が誤分類です。
なぜここで GAP を使うのか
モデルは AdaptiveAvgPool2d((1, 1)) を使っています。この文脈では Global Average Pooling と考えてよいです。[N, 32, H, W] を [N, 32, 1, 1] に変えます。
分類ヘッドは小さくなります。
[N, 32, 1, 1] -> flatten -> [N, 32] -> Linear(32, 4)
この節では、GAP によって 16 * 3 * 3 のような壊れやすい手計算も避けられます。
結果を診断する
| 症状 | ありそうな原因 | 次の行動 |
|---|---|---|
| train も val も悪い | モデルが弱い、ラベルが悪い、LR 問題 | shape を表示し、サンプルを見て、LR を調整 |
| train は良いが val が悪い | 過学習または split の問題 | データ追加、augmentation、regularization |
| loss が動かない | ラベル間違い、勾配なし、LR が小さい | loss.backward()、ラベル、学習可能パラメータを確認 |
| 高い確信度で間違える | データ偏りやパターン漏洩 | サンプルとクラス分布を確認 |
| 1 クラスだけ予測する | クラス不均衡または最適化問題 | クラス数と logits を表示 |
Toy Task から実画像へ
この節では意図的に小さな合成データを使いました。実プロジェクトでは次が増えます。
DatasetとDataLoader。- 画像ファイルの読み込み。
- source ごとの train/validation/test split。
- data augmentation。
- pretrained backbone または転移学習。
- model checkpoint。
- precision、recall、クラス別 accuracy などの指標。
流れは同じです。道具が本格的になるだけです。
よくあるミス
| ミス | 修正 |
|---|---|
| training loss だけを見る | 必ず validation metrics を計算する |
| channel 次元を忘れる | [N, C, H, W] を使う |
CrossEntropyLoss の前に softmax する | 生の logits を CrossEntropyLoss に渡す |
| 間違った例を見ない | 混同行列とサンプルを確認する |
| validation が training に似すぎる | 実画像では source ごとに分割する |
練習
noiseを0.08から0.25に増やす。検証結果はどう変わるか。per_classを120から10に減らす。モデルはまだ汎化できるか。AdaptiveAvgPool2dを外し、Flattenhead を使う。Linearはどの shape を受け取るべきか。- 四角い枠など、もう 1 クラス追加する。
- 誤分類があれば、検証セットの最初の 5 件を表示する。
まとめ
- 完整な画像分類ループには、データ、ラベル、分割、モデル、loss、指標、誤分類分析が含まれる。
- PyTorch の CNN 入力は
[N, C, H, W]。 CrossEntropyLossは確率ではなく logits を受け取る。- GAP は分類ヘッドをコンパクトにし、shape のミスを減らす。
- 検証とエラー分析は後付けではなく、モデル作業の一部です。