6.3.2 畳み込みの基礎
畳み込みは、CNN が画像を見るための基本操作です。空間構造を早い段階で長いベクトルへつぶさず、小さな領域を順に見ていきます。このページでは、まず図を見て、次に手計算し、最後に nn.Conv2d で同じ考えを確認します。
学習目標
- 画像を早すぎる段階で flatten するとなぜ効率が悪いかを説明できる。
- 畳み込みの出力値を 1 つ手計算できる。
- kernel、stride、padding、channel、feature map を理解する。
- PyTorch で出力 shape を確認できる。
- 畳み込みを重ねると受容野が広がる理由を説明できる。
まずスライドする窓を見る
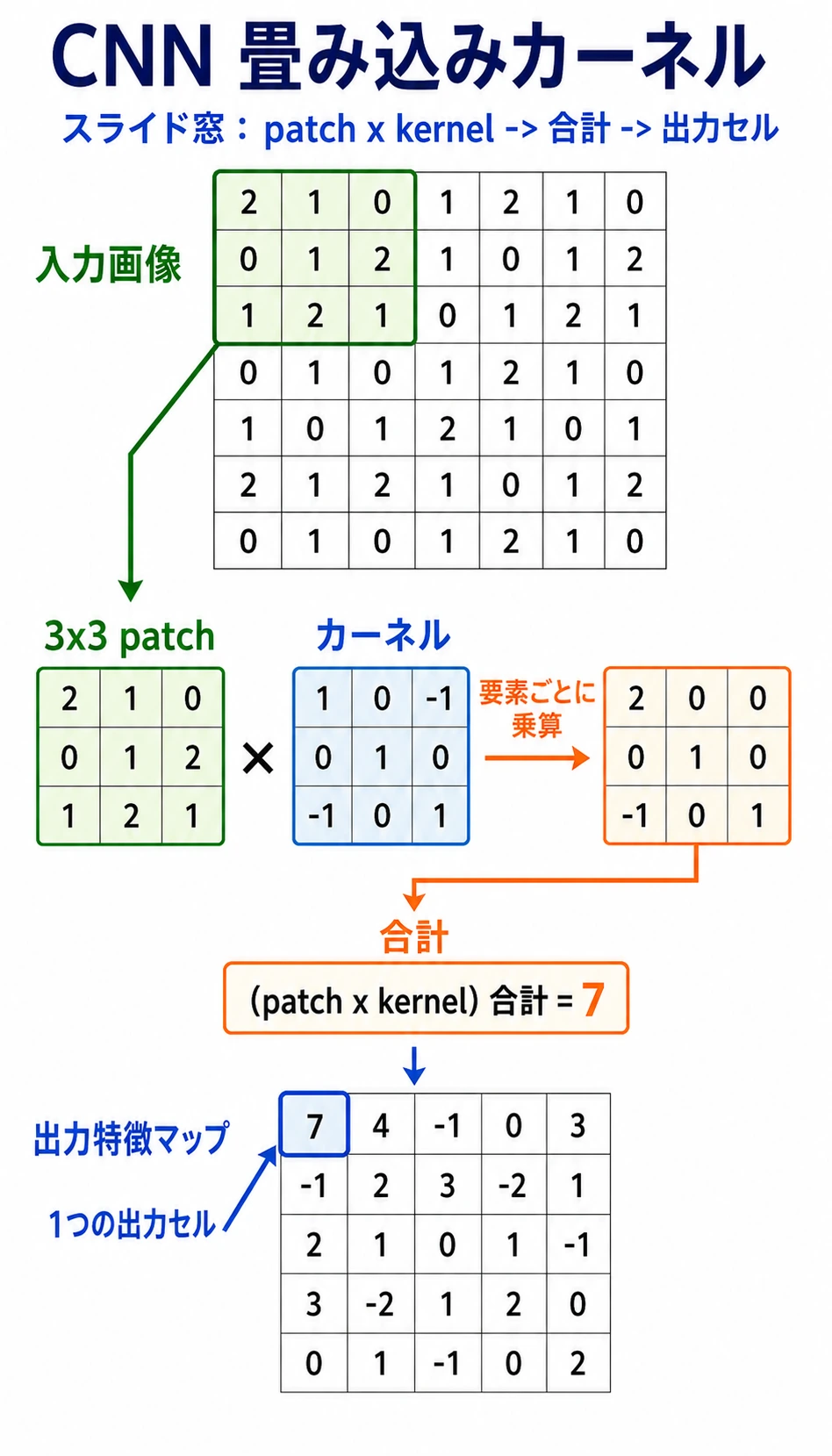
図は次の順番で読みます。
小さな窓 -> kernel と要素ごとに掛け算 -> 合計 -> 出力値 1 つ -> スライドして繰り返す
畳み込み kernel は、小さなパターン検出器です。画像全体を一度に見るのではなく、局所領域を順にスキャンし、その反応を feature map に書き込みます。
なぜ先に画像を flatten しないのか
32 x 32 のグレースケール画像には 1024 個のピクセルがあります。出力が 512 個の全結合層に入れると、必要な重みは次の数になります。
1024 * 512 = 524288 weights
224 x 224 x 3 のカラー画像では入力値が 150528 個になります。素朴な全結合層はパラメータが大きくなりすぎ、さらにピクセルの位置関係も失います。
畳み込みは 2 つの問題を解決します。
| 早すぎる flatten の問題 | 畳み込みの考え方 |
|---|---|
| 近いピクセル同士の空間関係が消える | 局所 window を見る |
| 位置ごとに別々の重みが必要になる | 同じ kernel を全体で使い回す |
| パラメータ数が急増する | 画像全体でパラメータを共有する |
中心になる用語は 2 つです。
- 局所結合:各出力は小さな範囲だけを見る。
- パラメータ共有:同じ kernel が多くの位置をスキャンする。
実験 1:畳み込みを手計算する
import numpy as np
image = np.array(
[
[1, 2, 0, 0],
[5, 3, 0, 4],
[2, 1, 3, 1],
[0, 2, 1, 2],
],
dtype=np.float32,
)
kernel = np.array(
[
[1, 0],
[0, -1],
],
dtype=np.float32,
)
out = np.zeros((3, 3), dtype=np.float32)
for i in range(3):
for j in range(3):
patch = image[i : i + 2, j : j + 2]
out[i, j] = np.sum(patch * kernel)
print("manual_conv_lab")
print(out)
期待される出力:
manual_conv_lab
[[-2. 2. -4.]
[ 4. 0. -1.]
[ 0. 0. 1.]]
左上の出力値はこう計算します。
patch = [[1, 2],
[5, 3]]
kernel = [[ 1, 0],
[ 0, -1]]
score = 1*1 + 2*0 + 5*0 + 3*(-1) = -2
これが畳み込みの中心的な計算です。
実験 2:kernel をエッジ検出器として使う
次の横方向 kernel は、隣り合うピクセルが左から右へどう変化するかを見ます。
import numpy as np
image = np.array(
[
[0, 0, 0, 0, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 0, 0],
],
dtype=np.float32,
)
kernel = np.array([[-1, 1]], dtype=np.float32)
out = np.zeros((5, 4), dtype=np.float32)
for i in range(5):
for j in range(4):
patch = image[i : i + 1, j : j + 2]
out[i, j] = np.sum(patch * kernel)
print("edge_lab")
print(out)
期待される出力:
edge_lab
[[0. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 1. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 0. 0.]]
1 は画像が 0 から 1 へ変わる境界に現れます。初期の CNN 層がエッジに似た filter を学びやすい理由もここにあります。
Stride、Padding、出力サイズ
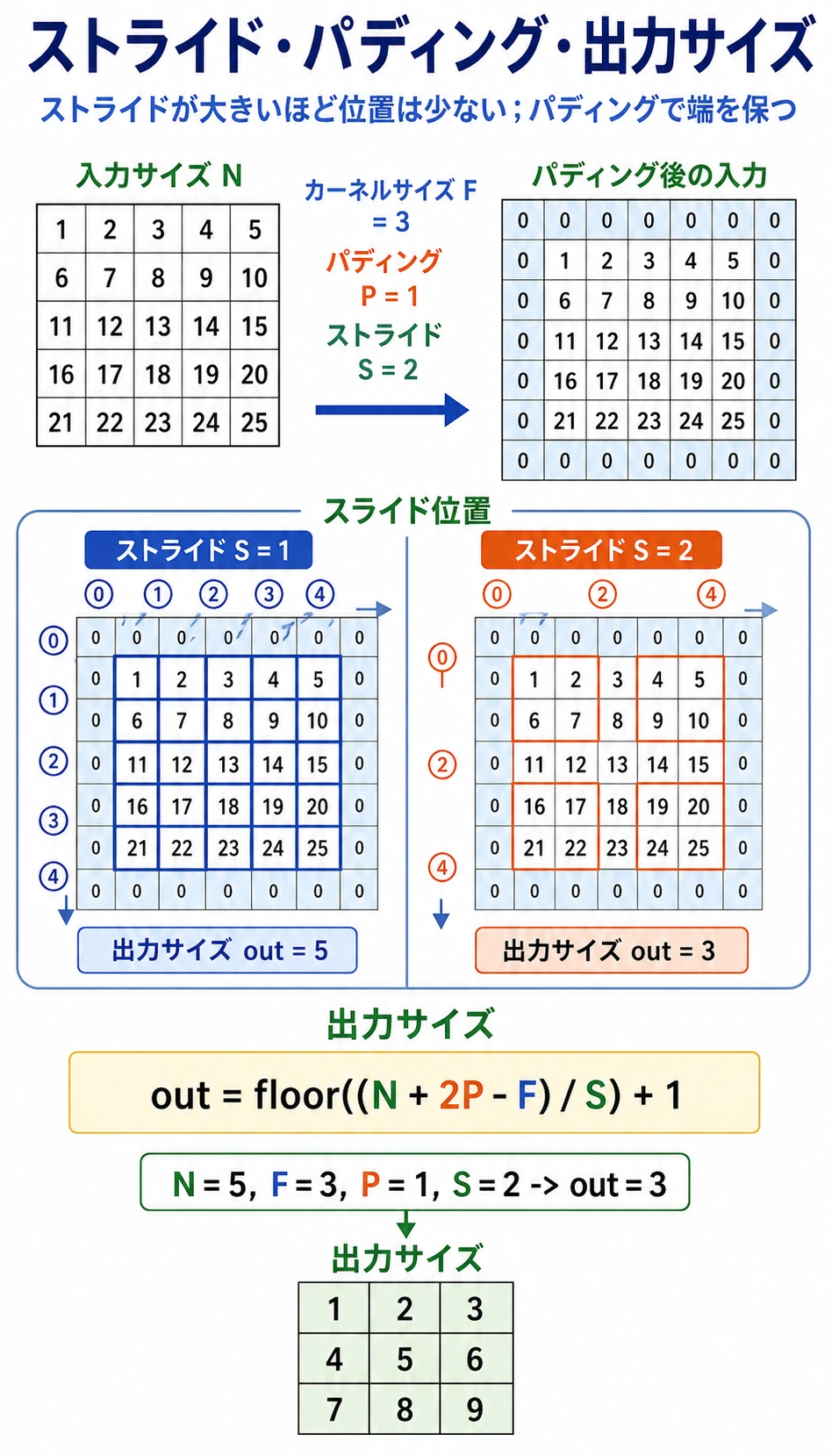
| 用語 | 意味 | 影響 |
|---|---|---|
kernel_size | window の大きさ | 大きいほど広い局所領域を見る |
stride | kernel が 1 回で進む距離 | 大きいほど出力は小さくなる |
padding | 入力の周囲に足す枠 | 端の情報を残し、サイズを調整する |
空間方向 1 次元の出力サイズは次の式で計算します。
output = floor((input + 2*padding - kernel_size) / stride) + 1
例:
input=6, kernel_size=3, padding=1, stride=2
output = floor((6 + 2*1 - 3) / 2) + 1 = 3
PyTorch で確認します。
import torch
from torch import nn
x = torch.randn(1, 1, 6, 6)
conv = nn.Conv2d(
in_channels=1,
out_channels=2,
kernel_size=3,
stride=2,
padding=1,
)
y = conv(x)
print("size_lab")
print("input:", tuple(x.shape))
print("output:", tuple(y.shape))
期待される出力:
size_lab
input: (1, 1, 6, 6)
output: (1, 2, 3, 3)
shape は [batch, channels, height, width] と読みます。
多チャネル畳み込み
カラー画像には、赤・緑・青の 3 つの入力 channel があります。PyTorch では、RGB 画像の batch は通常こう表します。
[batch, 3, height, width]
RGB 画像に対する 3 x 3 畳み込みの kernel shape は、実際には次の形です。
[out_channels, in_channels, kernel_height, kernel_width]
実行して確認します。
import torch
from torch import nn
x = torch.randn(2, 3, 32, 32)
conv = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, padding=1)
y = conv(x)
print("channel_lab")
print("input:", tuple(x.shape))
print("output:", tuple(y.shape))
print("weight:", tuple(conv.weight.shape))
print("bias:", tuple(conv.bias.shape))
期待される出力:
channel_lab
input: (2, 3, 32, 32)
output: (2, 8, 32, 32)
weight: (8, 3, 3, 3)
bias: (8,)
読み方:
2:batch 内の画像が 2 枚。3:RGB の入力 channel。8:学習される出力 feature map が 8 枚。(8, 3, 3, 3):8 個の kernel があり、それぞれ 3 つの入力 channel を見る。
受容野:CNN が深さによって広く見る仕組み
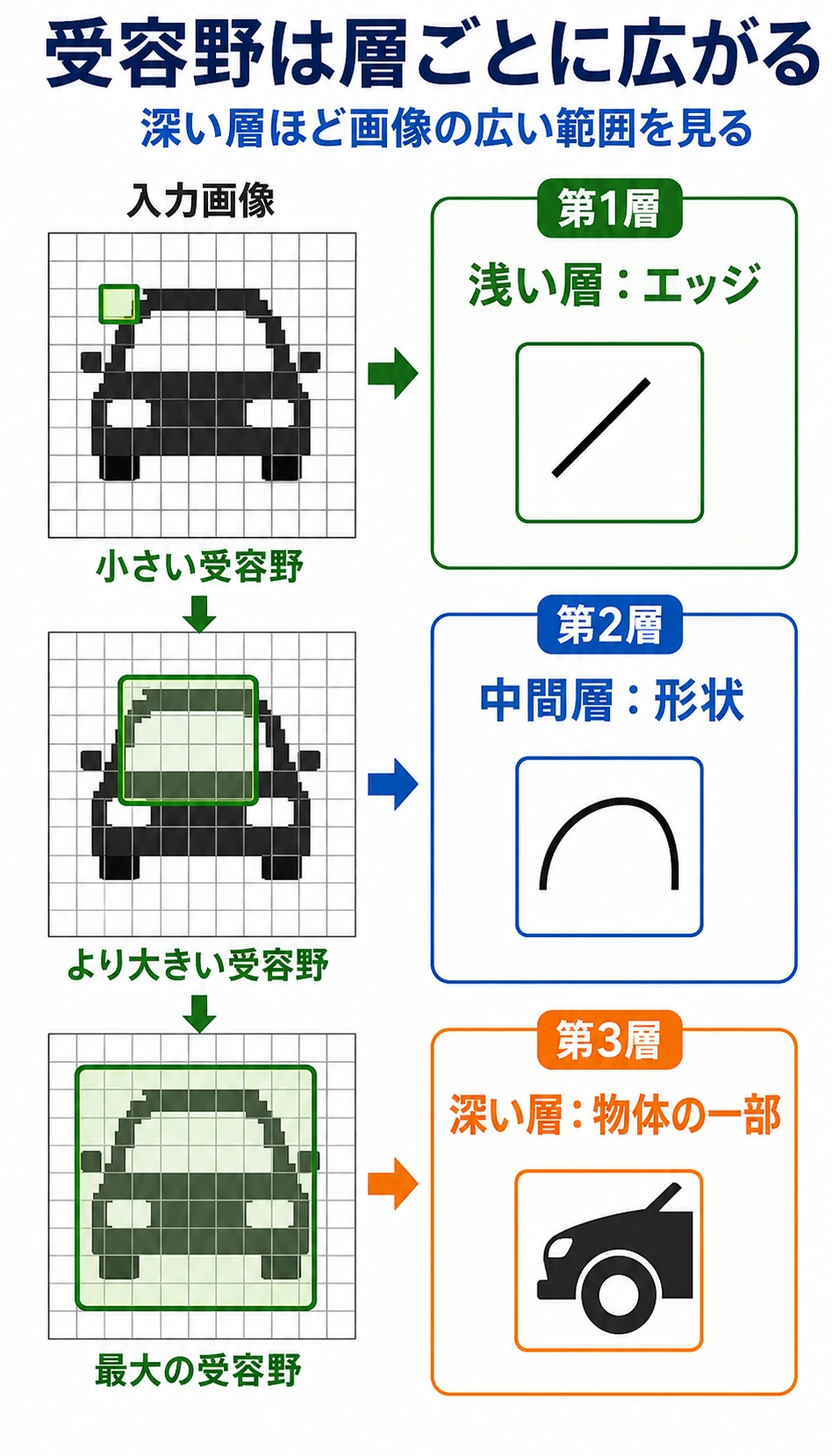
1 つの 3 x 3 畳み込みは、小さな局所領域しか見ません。層を重ねると、後ろの特徴は元画像のより広い範囲に間接的に依存します。
直感:
| 層の深さ | 学びやすいもの |
|---|---|
| 浅い層 | エッジ、色の変化、テクスチャ |
| 中間層 | 角、単純な形、部品 |
| 深い層 | より大きな物体の部品、意味的なパターン |
CNN が画像に強い理由は、この階層性にあります。小さな局所的な手がかりを、より大きな視覚的な意味へ組み合わせられるからです。
基本の Conv2d チェックリスト
import torch
from torch import nn
x = torch.randn(1, 1, 8, 8)
conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=3,
stride=1,
padding=1,
)
y = conv(x)
print("conv2d_lab")
print("input:", tuple(x.shape))
print("output:", tuple(y.shape))
print("weight:", tuple(conv.weight.shape))
print("bias:", tuple(conv.bias.shape))
期待される出力:
conv2d_lab
input: (1, 1, 8, 8)
output: (1, 4, 8, 8)
weight: (4, 1, 3, 3)
bias: (4,)
Conv2d を読むときは、まず次を確認します。
- 入力 shape
[N, C, H, W]は何か。 in_channelsは入力のCと一致しているか。out_channelsは何枚の feature map を作るか。kernel_size、stride、paddingはHとWをどう変えるか。
よくあるミス
| ミス | なぜ困るか | 修正 |
|---|---|---|
PyTorch で [H, W, C] のまま使う | PyTorch は [N, C, H, W] を期待する | 画像ライブラリから変換するときに permute を使う |
in_channels を間違える | Conv2d が入力と接続できない | 層の前で x.shape を表示する |
| padding を忘れる | feature map が予想外に小さくなる | 出力サイズを計算するか shape を表示する |
| 畳み込みを魔法扱いする | feature の調査が難しくなる | patch * kernel -> sum を思い出す |
| 早すぎる flatten | 空間構造が失われる | classifier head の前に conv block を使う |
練習
- 手書きの
2 x 2kernel を変えて、出力がどう変わるか観察する。 - 実験 1 の
out[1, 0]を手計算し、表示された結果と比べる。 - size lab の
strideを1に変える。出力 shape はどうなるか。 - channel lab の
out_channelsを16に変える。どの shape が変わるか。 permuteを使って、画像風 tensor を[N, H, W, C]から[N, C, H, W]に変換する。
まとめ
- 畳み込みは、早すぎる flatten よりも局所的な空間構造を保ちやすい。
- kernel は、位置をまたいで共有される小さなパターン検出器。
strideとpaddingは、kernel の動き方と出力サイズを制御する。- 多チャネル畳み込みは、複数の入力 channel の情報を組み合わせる。
- 畳み込み層を重ねると受容野が広がり、視覚的な階層が作られる。