6.3.3 CNN の基本構造
前のページでは、1 つの kernel が 1 つの局所 window をどう走査するかを学びました。このページでは、それらの部品を完全な CNN として組み立て、各段階の shape を追跡します。図だけの存在だったモデルを、実際に読める構造にしていきます。
学習目標
image -> conv block -> feature map -> classifier head -> logitsの流れを説明できる。- channel 数が増え、高さと幅が小さくなる理由を説明できる。
- 小さな畳み込みブロックを実行し、出力 shape を読める。
- PyTorch で完全な
TinyCNNを作れる。 Flattenと Global Average Pooling(GAP)を、実装上の観点から比較できる。
まず全体のパイプラインを見る
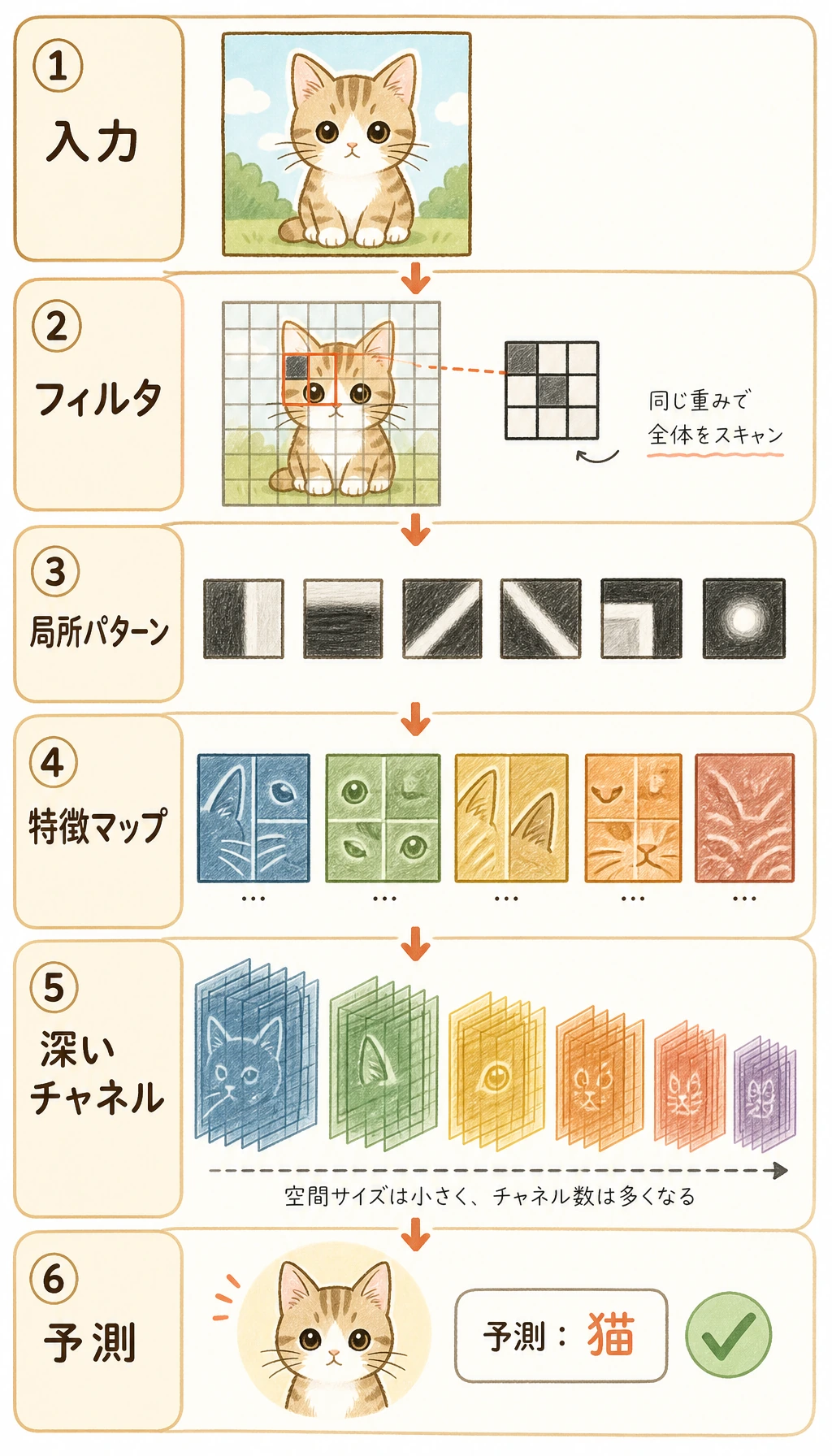
図は左から右へ読みます。
画像 -> 低レベル特徴 -> 圧縮された feature map -> 分類ヘッド -> クラススコア
CNN は通常、2 つの部分に分けて考えます。
| 部分 | 役割 | よく使う層 |
|---|---|---|
| feature extractor | ピクセルを有用な feature map に変える | Conv2d、ReLU、BatchNorm2d、MaxPool2d |
| classifier head | 最後の feature map をクラススコアに変える | Flatten または GAP、Linear |
最後の層の出力は、よく logits と呼ばれます。これは softmax に入れる前の生のクラススコアです。
Channel は増え、空間サイズは小さくなる
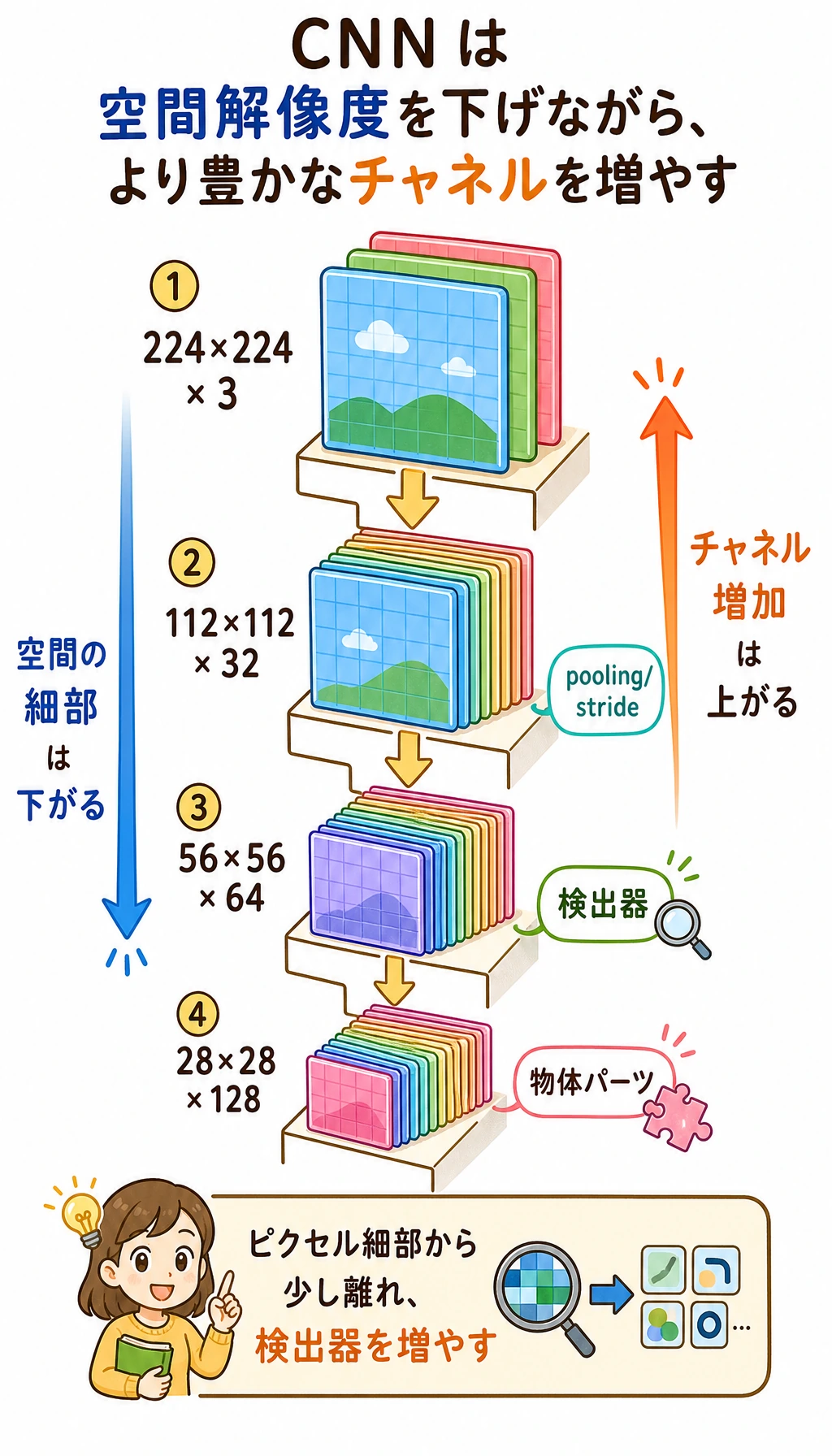
浅い層は空間的な細部を多く残します。深い層はピクセル位置を減らす代わりに、より多くの特徴種類を保持します。
| 段階 | shape の直感 | 意味 |
|---|---|---|
| input | [N, 3, 32, 32] | RGB 画像 |
| early feature | [N, 16, 32, 32] | 多くのエッジ・テクスチャ検出器 |
| after pooling | [N, 16, 16, 16] | 小さな map に、局所的に強い信号を残す |
| deeper feature | [N, 64, 8, 8] | より抽象的なパターン |
このトレードオフが CNN 設計の中心です。
- 空間位置を減らすと計算量が下がる。
- channel を増やすと、より豊かな視覚的証拠を保存できる。
- classifier head は生の全ピクセルではなく、十分な意味を持つ特徴を見るべき。
実験 1:MaxPool を手計算する
MaxPool2d(2) は、各 2 x 2 window の最大値を残します。
import numpy as np
feature_map = np.array(
[
[1, 3, 2, 0],
[4, 6, 1, 2],
[0, 1, 5, 3],
[2, 4, 1, 7],
],
dtype=np.float32,
)
pooled = np.array(
[
[feature_map[0:2, 0:2].max(), feature_map[0:2, 2:4].max()],
[feature_map[2:4, 0:2].max(), feature_map[2:4, 2:4].max()],
]
)
print("maxpool_lab")
print(pooled)
期待される出力:
maxpool_lab
[[6. 2.]
[4. 7.]]
Pooling は一部の細かい情報を捨てますが、局所領域で最も強い反応を残します。分類では、「特徴が正確にどのピクセルにあったか」よりも、「その特徴が現れたか」が重要なことが多いためです。
実験 2:1 つの畳み込みブロックを実行する
基本的な CNN block は次の形です。
Conv2d -> activation -> optional pooling
実行します。
import torch
from torch import nn
block = nn.Sequential(
nn.Conv2d(3, 8, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
x = torch.randn(2, 3, 32, 32)
y = block(x)
print("block_lab")
print("input:", tuple(x.shape))
print("output:", tuple(y.shape))
期待される出力:
block_lab
input: (2, 3, 32, 32)
output: (2, 8, 16, 16)
変化を読むと:
- batch は
2のまま。 - channel は
3から8になる。 - 高さと幅は
MaxPool2d(2)により32から16になる。
実務の CNN では、次の形もよく見ます。
Conv2d -> BatchNorm2d -> ReLU
BatchNorm2d は学習中の feature scale を安定させます。便利ですが、最初のモデルでは、まず shape の流れを明確にするほうが大事です。
実験 3:完全な Tiny CNN を作る
このモデルはグレースケールの 28 x 28 画像を受け取り、10 個のクラススコアを返します。
import torch
from torch import nn
class TinyCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(2)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(16 * 7 * 7, 64),
nn.ReLU(),
nn.Linear(64, num_classes),
)
def forward(self, x):
print("shape_trace")
print(f"{'input':<8} {tuple(x.shape)}")
x = torch.relu(self.conv1(x))
print(f"{'conv1':<8} {tuple(x.shape)}")
x = self.pool1(x)
print(f"{'pool1':<8} {tuple(x.shape)}")
x = torch.relu(self.conv2(x))
print(f"{'conv2':<8} {tuple(x.shape)}")
x = self.pool2(x)
print(f"{'pool2':<8} {tuple(x.shape)}")
x = self.classifier(x)
print(f"{'logits':<8} {tuple(x.shape)}")
return x
model = TinyCNN(num_classes=10)
x = torch.randn(4, 1, 28, 28)
_ = model(x)
期待される出力:
shape_trace
input (4, 1, 28, 28)
conv1 (4, 8, 28, 28)
pool1 (4, 8, 14, 14)
conv2 (4, 16, 14, 14)
pool2 (4, 16, 7, 7)
logits (4, 10)
最後の shape が [4, 10] なのは、4 枚の画像それぞれに 10 個のスコアを出しているからです。
エンジニアのように構造を読む
CNN を読むときは、層の名前だけでなく、各境界の tensor contract を追跡します。
| 行 | 確認する contract |
|---|---|
Conv2d(1, 8, ...) | 入力は 1 channel でなければならない |
MaxPool2d(2) | 高さと幅が 2 で割られる |
Conv2d(8, 16, ...) | 直前の出力 channel は 8 でなければならない |
Linear(16 * 7 * 7, 64) | flatten 後の特徴数が実際の feature map と一致する必要がある |
最後の Linear(..., 10) | 出力次元はクラス数と一致する必要がある |
CNN の多くのエラーは contract の不一致です。ある層に届いた tensor shape が、その層の期待と違っているのです。
Flatten と Global Average Pooling
Flatten は、すべての空間位置を長いベクトルにします。
[N, 16, 7, 7] -> [N, 784]
GAP は、各 channel につき平均値を 1 つだけ残します。
[N, 16, 7, 7] -> [N, 16]
パラメータ数を比べます。
from torch import nn
def count_params(module):
return sum(p.numel() for p in module.parameters() if p.requires_grad)
flatten_head = nn.Linear(16 * 7 * 7, 10)
gap_head = nn.Linear(16, 10)
print("head_param_lab")
print("flatten head:", count_params(flatten_head))
print("gap head :", count_params(gap_head))
期待される出力:
head_param_lab
flatten head: 7850
gap head : 170
トレードオフは次の通りです。
| Head | 強み | コスト |
|---|---|---|
| Flatten + Linear | 単純で、位置に依存する細部も使える | パラメータが多く、入力サイズが固定されやすい |
| GAP + Linear | コンパクトで、空間サイズの変化に比較的強い | 細かい位置情報を捨てることがある |
現代的な CNN 分類器では、GAP がよく使われます。過学習リスクを下げ、head を小さくできるからです。
よくあるミス
| ミス | 症状 | 修正 |
|---|---|---|
| channel 順序が違う | expected input ... to have C channels | PyTorch では [N, C, H, W] を使う |
Linear の入力サイズが違う | 行列積の shape エラー | Flatten の前で shape を表示する |
| pooling が早すぎる・多すぎる | feature map が小さくなりすぎる | 各 block 後の H と W を追跡する |
| logits を確率だと思う | loss や評価の解釈が混乱する | CrossEntropyLoss は logits を受け取り、表示時だけ softmax する |
| BatchNorm の mode を意識しない | train/eval で挙動が変わる | 学習時は model.train()、評価時は model.eval() |
練習
conv2の出力 channel を16から32に変える。どの行も一緒に変える必要があるか。- 分類ヘッドを
AdaptiveAvgPool2d((1, 1))、Flatten、Linear(16, 10)に置き換える。 - pooling 層を 1 つ削除し、新しい flatten サイズを実行前に予測する。
conv1の後にBatchNorm2d(8)を追加し、shape が変わらないことを確認する。- RGB の
64 x 64入力について、各層の後の shape を手で書く。
まとめ
- CNN は feature extractor と classifier head で構成される。
- 畳み込みブロックは feature channel を増やし、pooling や stride は空間サイズを小さくする。
- shape tracing は CNN 構造をデバッグする最速の方法。
Flattenは単純だがパラメータが多い。GAP はコンパクトで、現代 CNN でよく使われる。- 良い CNN 設計は、層を闇雲に積むことではなく、情報の流れを制御すること。