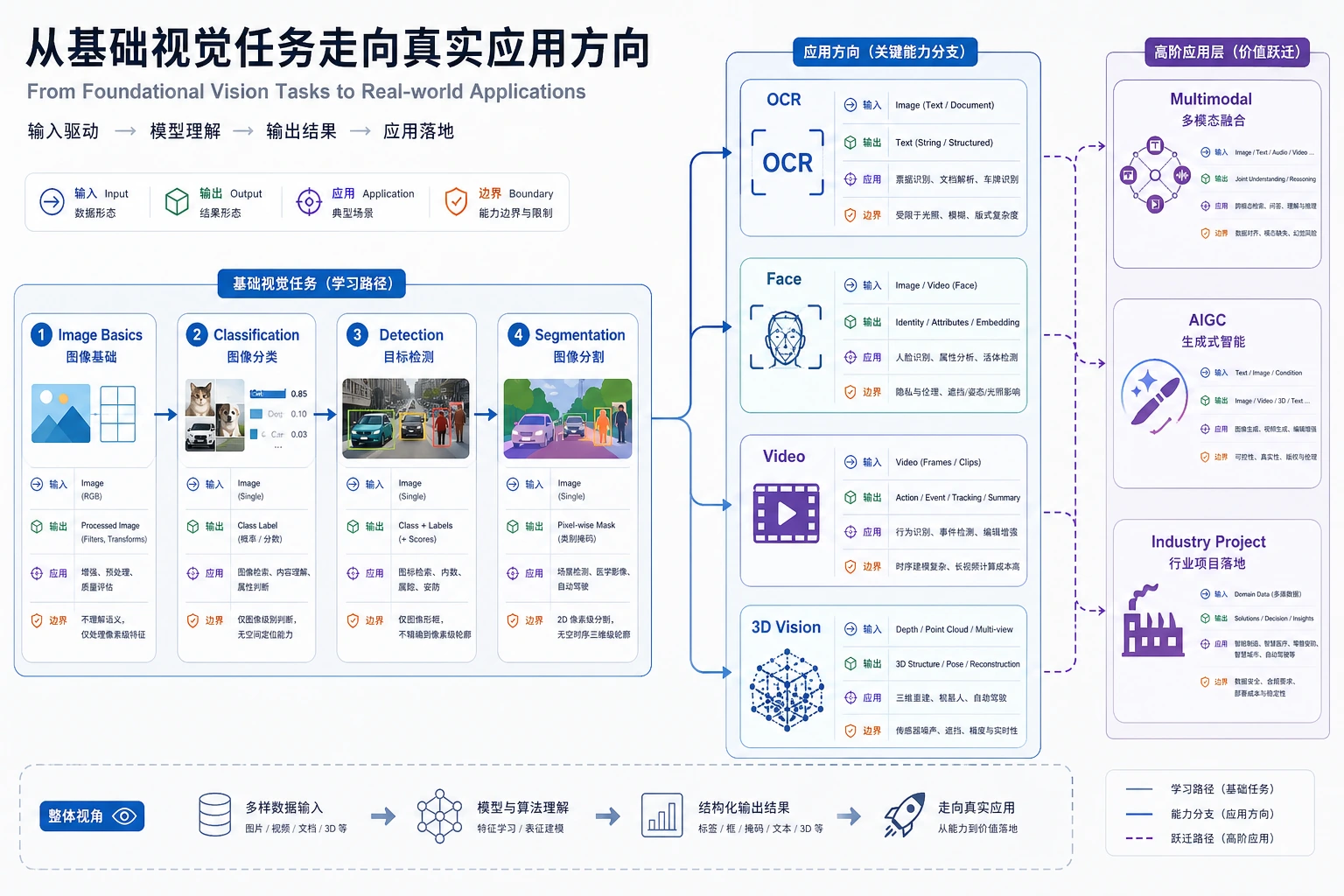
10.5.1 高级视觉路线图:OCR、人脸、视频、3D
高级视觉不是模型名称集合,而是建立在同一视觉基础上的应用方向:输入更复杂、输出更复杂、约束和风险也更多。
先看方向地图
![]()
OCR 适合文档,人脸识别适合身份敏感场景,视频适合时间和运动,3D 视觉适合空间结构。
跑一个方向选择检查
选择一个方向深入,不要四个方向都浅尝辄止。
requirement = {
"input": "screenshot",
"needs_text": True,
"needs_identity": False,
"needs_time": False,
"needs_depth": False,
}
if requirement["needs_text"]:
direction = "OCR"
elif requirement["needs_identity"]:
direction = "Face"
elif requirement["needs_time"]:
direction = "Video"
elif requirement["needs_depth"]:
direction = "3D"
else:
direction = "Classification or detection"
print("direction:", direction)
print("first_output:", "text with layout")
预期输出:
direction: OCR
first_output: text with layout
做人脸、监控、医疗或身份项目时,先写清隐私和使用边界,再展示结果。
按这个顺序学
| 步骤 | 方向 | 实操产出 |
|---|---|---|
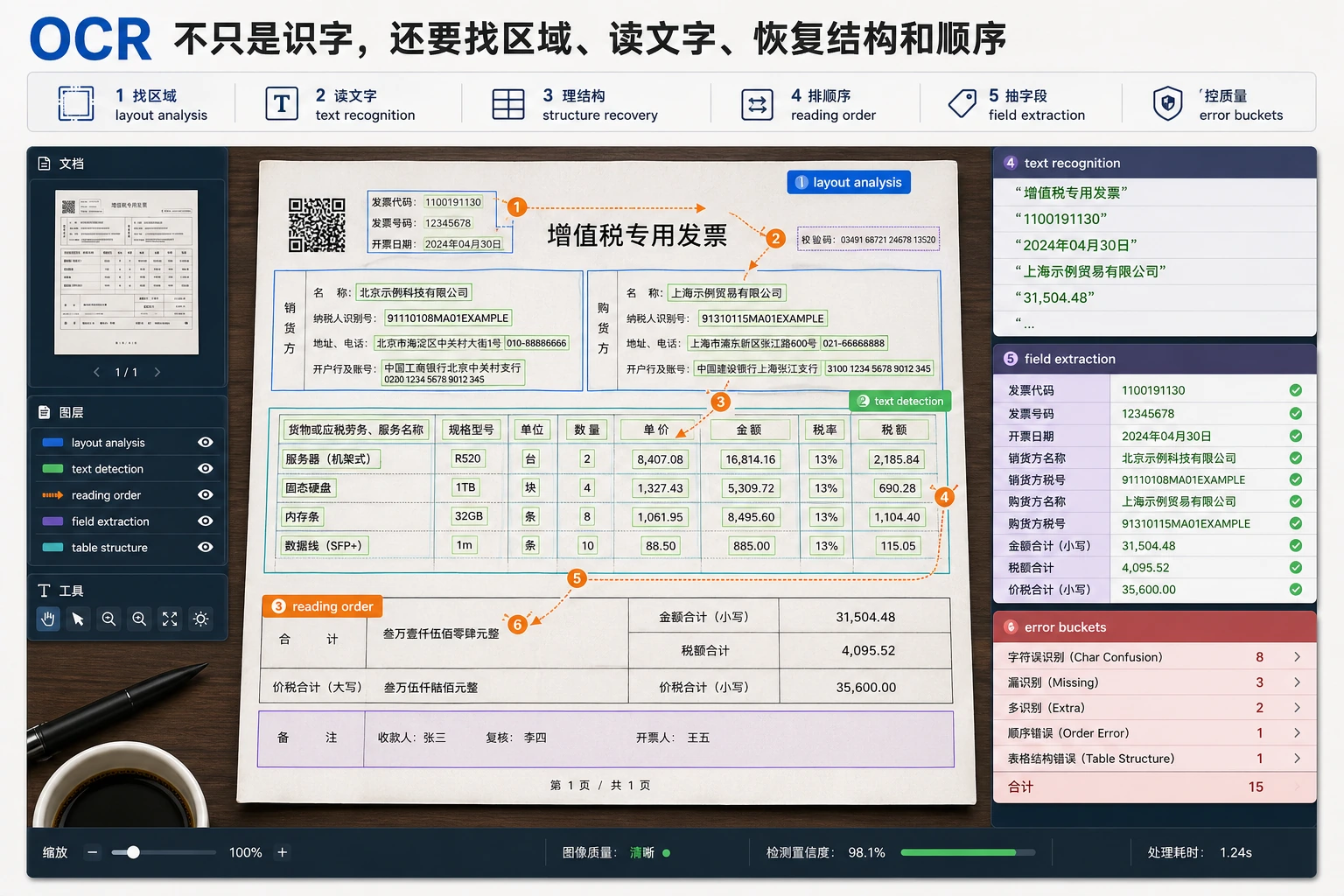
| 1 | OCR | 抽取文本、版面、字段、置信度和失败样例 |
| 2 | 人脸 | 检测人脸,解释阈值、隐私和偏见风险 |
| 3 | 视频 | 跨帧追踪事件并记录时间维度失败 |
| 4 | 3D 视觉 | 解释深度、点云、几何和传感器假设 |
通过标准
如果你能选择一个方向,定义输入/输出,运行最小项目,并记录失败案例和使用边界,就通过了本章。