10.5.4 OCR 文字识别【选修】
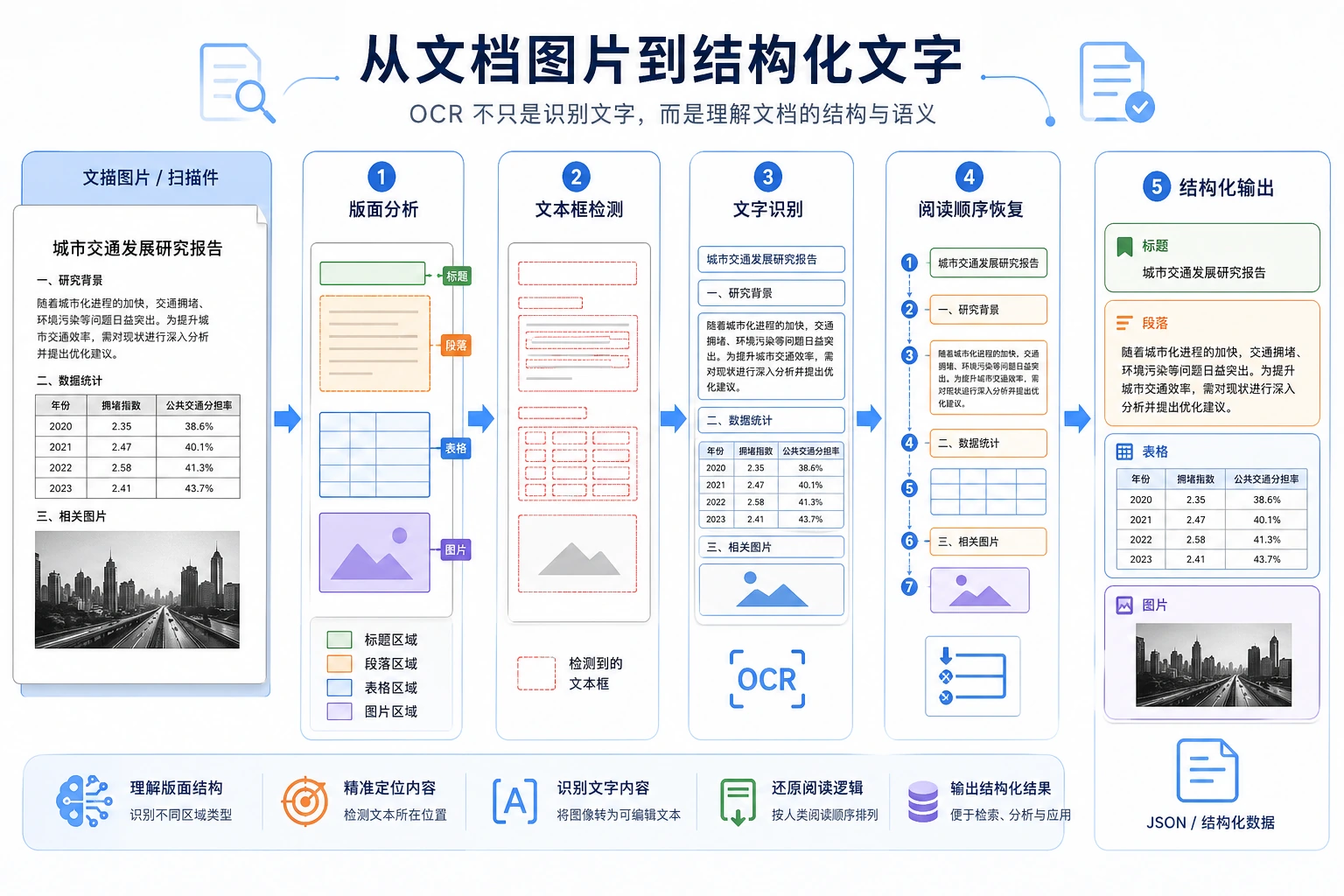
OCR 很容易被说成一句话:
- 把图片里的字识别出来
但真实项目里,问题会更细:
- 字在哪里
- 顺序是什么
- 多栏版面怎么读
- 倾斜和模糊怎么办
所以 OCR 更像一条流水线,而不是单个模型。
学习目标
- 理解 OCR 中“检测”和“识别”的区别
- 理解文档版面为什么会进一步增加复杂度
- 通过可运行示例建立 OCR 流水线直觉
- 理解 OCR 在表单、票据、文档场景中的特殊难点
先建立一张地图
OCR 这节最适合新人的理解顺序不是“先看识别结果”,而是先看清流水线:
所以这节真正想解决的是:
- 为什么 OCR 不是单一模型
- 为什么检测、识别、版面理解要拆开看
一、OCR 通常分哪几步?
文本检测
先找出文字区域在哪里。
文本识别
再把每块文字区域转成字符序列。
版面与结构理解
在复杂文档场景里,还要回答:
- 哪段先读
- 哪段属于标题
- 哪段属于表格或正文
一个更适合新人的总类比
你可以把 OCR 想成一个三人小组在处理一张发票:
- 第一个人先拿笔把所有文字圈出来
- 第二个人把每一块圈出来的文字读出来
- 第三个人再决定这些文字谁是标题、谁是金额、谁是日期
这样理解后,OCR 就不会再像:
- 一个神秘的大模型黑盒
而更像:
- 一条有明确分工的流水线
二、先看一个最小 OCR 流水线示例
image_blocks = [
{"box": (0, 0, 50, 20), "pixels": "INV-001"},
{"box": (0, 30, 80, 50), "pixels": "TOTAL 299"},
]
def detect_text_regions(image_blocks):
return [block["box"] for block in image_blocks]
def recognize_text(image_blocks):
return [{"box": block["box"], "text": block["pixels"]} for block in image_blocks]
regions = detect_text_regions(image_blocks)
texts = recognize_text(image_blocks)
print("regions:", regions)
print("texts:", texts)
预期输出:
regions: [(0, 0, 50, 20), (0, 30, 80, 50)]
texts: [{'box': (0, 0, 50, 20), 'text': 'INV-001'}, {'box': (0, 30, 80, 50), 'text': 'TOTAL 299'}]

第一行是检测结果:文字区域在哪里。第二行是识别结果:每个检测到的区域里写了什么。
这个例子最关键的地方是什么?
它清楚分开了:
- 找文字在哪里
- 把文字读出来
这正是 OCR 最基础的两阶段结构。
为什么很多 OCR 错误不在“识别字本身”?
因为如果检测阶段就把文字框切错:
- 漏了一半
- 顺序乱了
后面的识别再强也没法完全补救。
新人第一次学 OCR,最该先记什么?
最值得先记住的是:
- 检测负责“字在哪”
- 识别负责“字是什么”
- 文档场景里还常常要回答“先读哪、属于哪一块”
三、OCR 为什么经常比想象中更难?
文字不总是规则排版
可能会遇到:
- 倾斜
- 透视变形
- 模糊
- 遮挡
文档不总是单栏单行
例如:
- 表格
- 发票
- 医疗单据
这时“识别文字”只是第一步, 真正难的是结构理解。
字符级别错误会影响下游业务
像编号、金额、日期这种字段, 识错一位就可能直接影响业务。
再看一个最小“阅读顺序恢复”示例
lines = [
{"y": 80, "text": "TOTAL 299"},
{"y": 20, "text": "INVOICE"},
{"y": 50, "text": "INV-001"},
]
def restore_reading_order(lines):
return [item["text"] for item in sorted(lines, key=lambda x: x["y"])]
print(restore_reading_order(lines))
预期输出:
['INVOICE', 'INV-001', 'TOTAL 299']
原始列表顺序是乱的,但按纵坐标排序后,就能恢复这个简单文档从上到下的自然阅读顺序。
这个例子很小,但它能帮新人先建立一个关键直觉:
- OCR 做完识别,不代表任务结束
- 文字顺序和结构恢复,常常同样重要
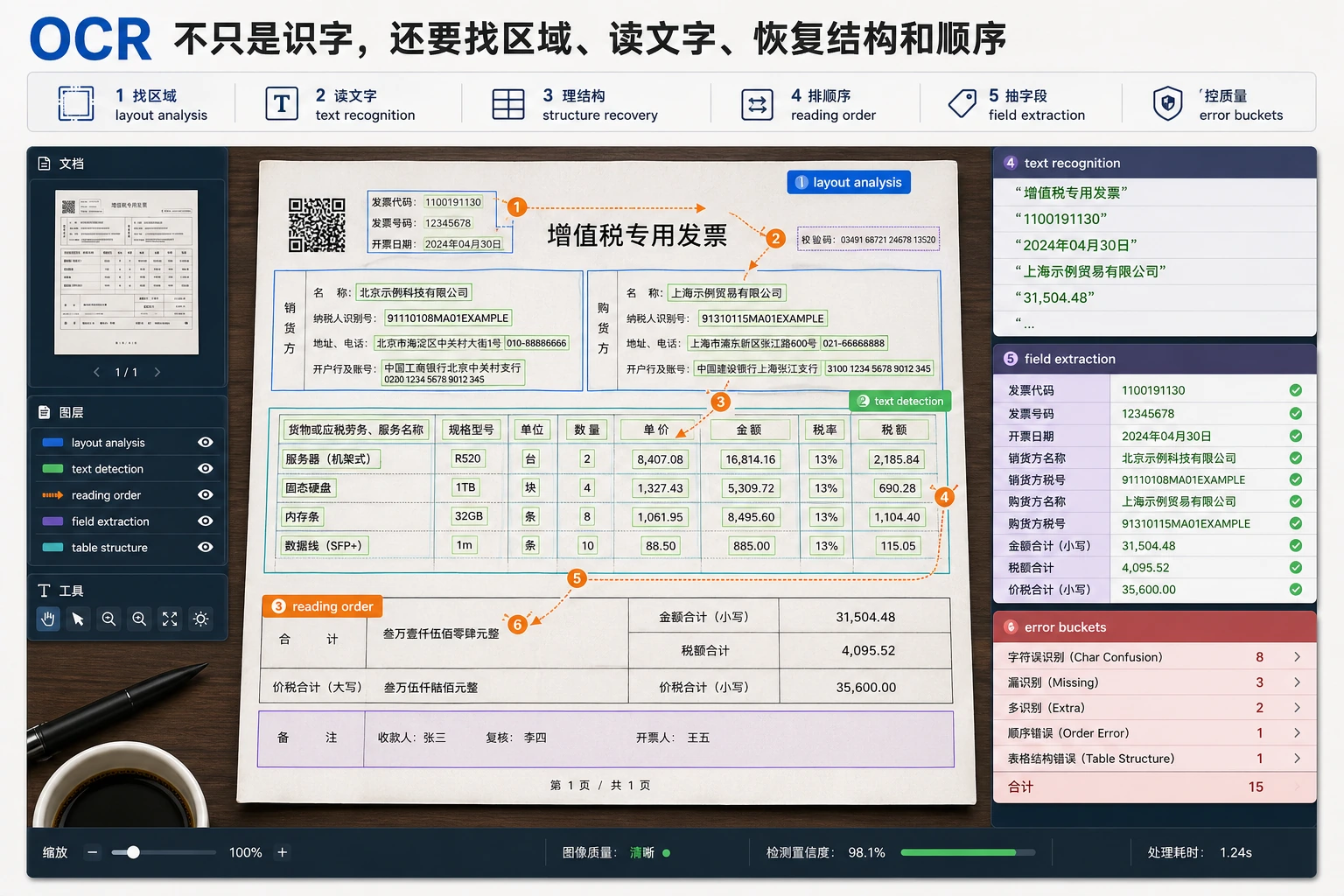
OCR 项目要分三层排查:文本检测有没有框准,文本识别有没有读对,版面结构有没有恢复顺序。票据、表格、双栏文档经常错在第三层。
四、一个新人可直接照抄的项目推进顺序
更稳的顺序通常是:
- 先做清晰单栏小样本
- 再看倾斜和模糊样本
- 再补版面顺序和结构理解
- 最后再进入票据、表格这类更复杂文档
这样会比一开始就做复杂票据系统更容易稳住。
如果你要把 OCR 做成项目,最值得先选哪类题目?
更稳的起点通常是:
- 清晰票据字段抽取
- 简单单栏文档识别
- 少量固定模板表单
这类题目的好处是:
- 检测区域更清楚
- 业务字段更容易评估
- 失败样本更容易分析
如果把 OCR 做成项目,最值得先展示什么
更像真实项目的展示顺序通常是:
- 原图
- 文本检测框
- 识别后的文本块
- 恢复后的字段或阅读顺序
- 失败样本分析
这样读者一眼就能看懂:
- 是哪一步出了问题
- 你的系统重点优化了哪一段流水线
五、最容易踩的坑
只看识别准确率,不看检测质量
OCR 是多阶段流水线,前一步错会传给后一步。
只做字符识别,不做结构恢复
很多文档类项目真正要的是:
- 字段
- 表格结构
- 阅读顺序
忽略图像预处理
例如:
- 二值化
- 去噪
- 倾斜校正
在很多场景里非常重要。
一个更像真实项目的最小错误分桶表
errors = [
{"type": "detection_miss", "count": 4},
{"type": "wrong_character", "count": 7},
{"type": "reading_order", "count": 3},
]
for item in errors:
print(f"{item['type']}: {item['count']}")
预期输出:
detection_miss: 4
wrong_character: 7
reading_order: 3
这个小表会告诉你下一步该看哪里:漏检文字框、字符识别错,还是文档顺序错。每一类问题通常都需要不同修法。
这个表虽然简单,但很像真实 OCR 项目里会做的第一步:
- 先分清错误主要来自检测、识别,还是结构恢复
不这样分,你就很容易:
- 识别模型拼命换了一圈
- 结果真正问题其实在检测或阅读顺序
六、如果把它做成作品集,最值得展示什么
- 原图
- 检测框结果
- 识别文本结果
- 字段恢复结果
- 一组典型失败样本
这样会比只展示“识别出来了哪些字”更像真实文档 AI 项目。
小结
这节最重要的是建立一个流水线判断:
OCR 不是单一“识字模型”,而是一条包含文本检测、文本识别和版面理解的多阶段系统。
只要这条线清楚了,后面你做票据、表单、文档理解项目就不会只盯识别模型本身。
这节最该带走什么
- OCR 的核心是流水线,不是单点模型
- 很多问题会在检测和结构层就已经决定上限
- 文档类 OCR 项目特别值得单独分析版面和字段恢复
练习
- 给示例再加一个新文字块,思考阅读顺序该怎么恢复。
- 为什么检测阶段的错误会直接拖垮 OCR 最终效果?
- 想一想:表格票据和普通街景文字识别,哪一层难点差别最大?
- 如果金额字段总识错一位,你会先查检测、识别还是后处理?为什么?