10.5.3 视频分析【选修】
视频分析最容易被误解成:
- 把很多图片一帧一帧跑一遍
这当然是起点,但不是全部。 视频真正带来的新问题在于:
同一个目标会随着时间连续变化,而时间本身也带着信息。
所以这节重点是把“时间维度”这件事讲清楚。
学习目标
- 理解视频任务和单帧图像任务的根本区别
- 理解抽帧、跟踪、时序建模各自解决什么问题
- 通过可运行示例建立视频分析最小直觉
- 理解为什么很多视频系统其实是“图像模型 + 时间逻辑”的组合
一、视频为什么比单张图更复杂?
因为同一目标会跨帧出现
一张图里,你只需要回答当前画面。 视频里还要考虑:
- 它刚刚在哪
- 接下来会去哪
因为“变化”本身就是信息
很多视频任务里,真正重要的不是某一帧长什么样, 而是:
- 动作怎么发生
- 轨迹怎么移动
一个类比
单张图像分析像看照片。 视频分析更像看监控回放,你会自然关心:
- 前后关系
- 事件过程
二、视频分析里最常见的几种处理方式
抽帧 + 单帧模型
最简单的方法:
- 定期抽帧
- 每帧单独分析
优点:
- 简单
缺点:
- 容易丢掉时间信息
检测 + 跟踪
适合:
- 行人轨迹
- 车辆轨迹
它的核心是:
- 每一帧先检测
- 再在时间上关联同一目标
时序建模
例如:
- 动作识别
- 事件识别
这类任务更依赖:
- 多帧共同表达一个模式
第一次做视频分析时,最稳的选择顺序
新人第一次做视频任务时, 最容易一上来就觉得“我要不要直接上时序网络”。 但更稳的顺序通常是:
- 先确认任务是不是单帧就够
- 如果单帧不够,再做抽帧 + 汇总
- 如果还不够,再做检测 + 跟踪
- 最后才上真正的时序建模
这个顺序很值, 因为很多真实视频系统并不是一上来就重模型, 而是先把:
- 抽帧策略
- 跟踪逻辑
- 事件定义
先讲清楚
![]()
视频不是“很多张图片堆起来”。读这张图时先看 frame sampling,再看 detection + tracking 如何把同一目标跨帧串起来,最后才看 temporal window 如何判断动作或事件。
三、先跑一个最小轨迹跟踪示例
frames = [
[{"id": None, "x": 10, "y": 10}],
[{"id": None, "x": 12, "y": 11}],
[{"id": None, "x": 15, "y": 13}],
]
def assign_track_ids(frames, max_distance=5):
next_id = 1
prev_objects = []
for frame in frames:
for obj in frame:
matched_id = None
for prev in prev_objects:
distance = abs(obj["x"] - prev["x"]) + abs(obj["y"] - prev["y"])
if distance <= max_distance:
matched_id = prev["id"]
break
if matched_id is None:
matched_id = next_id
next_id += 1
obj["id"] = matched_id
prev_objects = [dict(item) for item in frame]
return frames
tracked = assign_track_ids(frames)
for frame in tracked:
print(frame)
预期输出:
[{'id': 1, 'x': 10, 'y': 10}]
[{'id': 1, 'x': 12, 'y': 11}]
[{'id': 1, 'x': 15, 'y': 13}]
同一个目标一直保持 ID 1,因为相邻帧之间移动得足够小。如果移动距离超过 max_distance,这个极简 tracker 就可能误分配一个新 ID。
这个例子最想表达什么?
视频分析里很多系统的第一步不是复杂时序网络, 而是:
- 把跨帧的同一目标串起来
为什么这对业务很重要?
如果不能把同一目标在不同帧里关联起来, 很多任务根本做不下去:
- 计数
- 行为分析
- 越界告警
再补一个“滑动窗口看动作”的最小示例
跟踪能解决“同一个目标是不是同一个”的问题, 但很多视频任务还会关心:
- 一小段时间里到底发生了什么动作
下面这个最小例子先让你体会:
- 视频分析很多时候不是看一帧
- 而是看一小段时间窗口
sequence = [0, 0, 1, 1, 1, 0, 0] # 0=静止, 1=运动
window_size = 3
windows = []
for i in range(len(sequence) - window_size + 1):
window = sequence[i:i + window_size]
windows.append(window)
for idx, window in enumerate(windows):
motion_ratio = sum(window) / len(window)
label = "moving_event" if motion_ratio >= 0.67 else "static_or_unclear"
print(idx, window, label)
预期输出:
0 [0, 0, 1] static_or_unclear
1 [0, 1, 1] static_or_unclear
2 [1, 1, 1] moving_event
3 [1, 1, 0] static_or_unclear
4 [1, 0, 0] static_or_unclear
只有连续三帧都在移动的窗口会被标记为 moving event。这就是单帧标签和时序事件标签之间的关键差别。
这个例子最关键的地方是:
- 视频任务常常天然要看一小段时间
- 单帧判断对,未必就能说明整个事件判断对
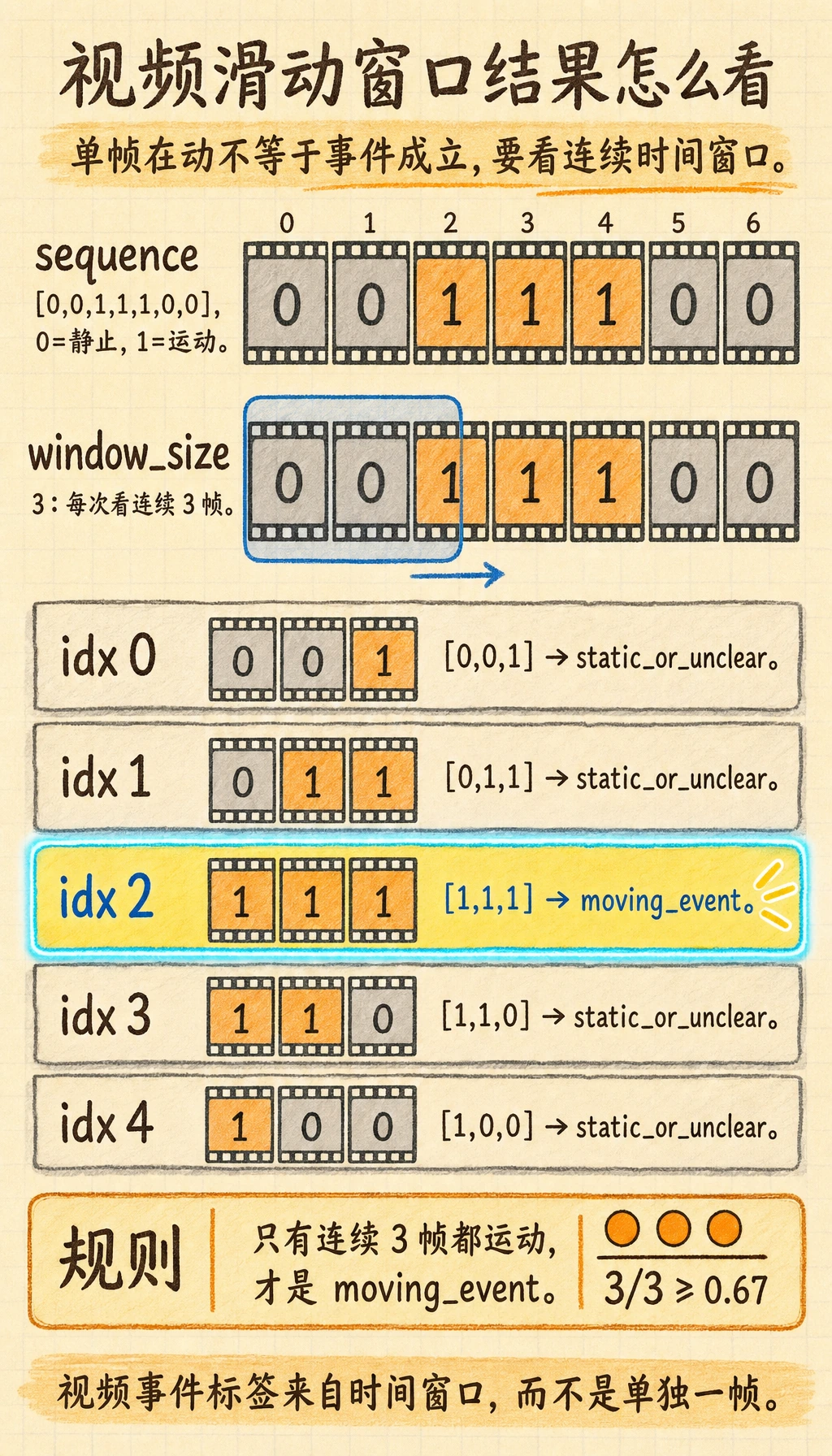
单帧状态只是观察值,事件标签应该来自一个时间窗口和一条规则。这个例子里,1 表示“这一帧在动”,而 moving_event 表示“相邻几帧都有足够证据,才算一个事件”。
四、先定义事件,再选择模型
视频项目一旦把“事件”写成一个小合同,后面的模型选择和评估就会清楚很多。
| 要决定什么 | 新人可接受的定义 | 更深入的项目定义 |
|---|---|---|
| 观察什么 | 每一帧是运动还是静止 | 帧状态包含目标 ID、区域、置信度和时间戳 |
| 事件何时开始 | 连续三帧都在运动 | 开始规则、结束规则、最短持续时间和允许中断长度 |
| 系统输出什么 | moving_event 或 static_or_unclear | start_time、end_time、track_id、置信度和证据帧 |
| 产品能容忍什么 | 偶尔误判或晚一点提醒 | 误报成本、漏报成本、最大告警延迟和人工复核流程 |
模型只是系统的一部分。很多时候,真正决定产品是否可靠的,是事件规则。
window_size决定系统看多长的历史。窗口越大通常越稳,但反应越慢。stride决定窗口多久移动一次。步长越小延迟越低,但计算量更高。threshold决定事件规则有多严格。阈值越高误报越少,但可能漏掉短动作。- 平滑或滞回规则可以减少信号抖动时标签来回跳的问题。
对有经验的学习者来说,一个很重要的习惯是把事件定义和模型代码分开。这样你可以用同一批检测结果,反复测试不同窗口大小、阈值和延迟预算,而不必每次都重新训练模型。
五、评估时序行为,而不只看单帧准确率
单帧准确率回答的是“这一帧识别对了吗”。视频系统还要回答:“事件是不是在正确时间、正确目标上被识别出来,并且没有不稳定地来回抖动?”
| 现象 | 应该检查什么 | 常见修正方向 |
|---|---|---|
| ID 切换 | 遮挡或交叉附近的 track ID 时间线 | 调整关联距离、加入外观特征,或换更强的 tracker |
| 标签抖动 | 事件边界前后的逐帧标签 | 加平滑、滞回,或更严格的窗口规则 |
| 短事件漏检 | 抽帧间隔和最短事件时长的关系 | 抽帧更密、缩短窗口,或增加快速触发路径 |
| 告警太晚 | 真实开始时间和预测开始时间的差 | 减小 stride、减少缓冲,或使用更轻的模型 |
| 单帧噪声触发假事件 | 窗口里的原始帧状态 | 要求连续证据,而不是只接受某一帧的强信号 |
汇报视频项目时,至少应该放一个时序指标,例如事件 precision/recall、开始时间误差、结束时间误差、ID 切换次数或告警延迟。这样作品才不像演示,而更像真实的视频系统。
六、最容易踩的坑
把视频当作独立图片集合
这样很容易丢掉:
- 轨迹
- 动作
- 事件顺序
抽帧策略过粗
抽帧太稀,会漏掉关键瞬间。一个简单检查方法是把抽帧间隔和你关心的最短事件时长放在一起比。如果事件只持续 0.4 秒,而你每 1 秒才抽一帧,那么模型再准也可能看不到这个事件。
只看单帧精度,不看时序稳定性
真实视频系统更该关注:
- 抖动
- 漏跟踪
- ID 切换
- 事件开始和结束误差
- 告警延迟
七、如果把视频分析做成项目,最值得展示什么
如果你想把这类题做成作品集页, 最值得展示的通常不是一串模型名, 而是下面这 6 样:
- 抽帧或时序建模的整体流程图
- 清楚的事件定义表
- 一条目标轨迹或事件窗口示意
- 一个小型时序指标表
- 一组典型失败案例,包括误报和漏报
- 你为什么最后选“抽帧 / 跟踪 / 时序模型”这条路线
这样别人会更容易看出:
- 你在做的是视频系统
- 而不只是把很多图片堆在一起
小结
这节最重要的是建立一个判断:
视频分析的难点不只是“帧更多”,而是必须把时间维度纳入建模,理解目标和事件是如何跨帧连续发生的。
这节最该带走什么
- 视频任务最关键的新维度不是像素,而是时间
- 很多视频系统其实是“单帧模型 + 时间逻辑”组合出来的
- 第一次做视频项目时,先把任务的时间需求分清楚,比直接追复杂模型更值
练习
- 把示例改成两个目标同时移动,看看简单跟踪逻辑是否会混乱。
- 为什么说很多视频系统其实是“单帧模型 + 时间逻辑”的组合?
- 抽帧太稀可能带来什么风险?
- 想一想:哪些视频任务必须显式建模时间,而不能只看单帧?
- 把
window_size从3改成5,误报和告警延迟会分别发生什么变化? - 增加一条规则:只有事件至少持续两个窗口才触发。它能减少哪类噪声?又可能漏掉哪类短事件?