10.5.2 人脸检测与识别【选修】
人脸任务看起来像“只是检测一个特殊目标”, 但真实系统通常至少包含:
- 找到脸
- 对齐
- 提特征
- 比较相似度
所以这节更重要的是理解:
人脸系统往往是一条流水线,不是单个模型。
学习目标
- 理解人脸检测、对齐和识别之间的区别
- 通过可运行示例理解特征比对的直觉
- 理解人脸系统为什么特别关注误识和隐私问题
- 建立人脸任务的整体流水线感
先建立一张地图
人脸任务最适合新人的理解方式不是“一个模型识别人脸”,而是先把完整流水线看清:
这条线一旦理清,你就不会把人脸系统误以为只是“检测一个特殊类别”。
一个更适合新人的总类比
你可以把人脸系统想成机场值机的三步:
- 先找到旅客是谁
- 再把证件摆正、对齐
- 最后才拿来和系统里的档案做比对
这样理解后,人脸识别就不会再像:
- 一个神秘的“认人模型”
而更像:
- 一条先整理输入、再做比较的流水线
一、人脸识别系统通常有哪些步骤?
- 检测:先找到脸在哪
- 对齐:把角度和姿态尽量规范化
- 表示:提取人脸向量
- 匹配:比较向量相似度
为什么“对齐”这一步经常被低估?
因为很多新人会天然觉得:
- 把脸框出来就够了
但实际系统里,如果人脸角度、姿态、裁切范围差太多, 后面的 embedding 往往会明显不稳定。
所以对齐的作用更像是:
先把输入拉回到一个更可比的状态。
二、先看一个最小相似度比对示例
from math import sqrt
face_a = [0.9, 0.2, 0.1]
face_b = [0.88, 0.22, 0.12]
face_c = [0.1, 0.8, 0.9]
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
na = sqrt(sum(x * x for x in a))
nb = sqrt(sum(x * x for x in b))
return dot / (na * nb)
print("a vs b:", round(cosine(face_a, face_b), 4))
print("a vs c:", round(cosine(face_a, face_c), 4))
预期输出:
a vs b: 0.9994
a vs c: 0.3034
face_a 和 face_b 非常接近,而 face_c 在 embedding 空间里离得很远。真实系统里,这个分数还需要配合阈值和拒绝策略一起使用。
这个例子最重要的直觉
人脸识别很多时候不是直接分类名字, 而是:
- 看两张脸的表示是否足够接近
新人第一次学这节,最该先记什么?
最值得先记的其实是:
- 检测负责“先把脸找出来”
- 对齐负责“把姿态拉回更可比的状态”
- 识别很多时候是在比较 embedding,而不是直接输出名字
阈值为什么会直接影响系统体验?
因为阈值本质上是在决定:
- 多像才算同一个人
阈值设得太松:
- 容易误识
阈值设得太严:
- 容易漏识
这类问题通常不只是模型问题,而是系统配置问题。
再看一个最小“阈值怎么改变结果”示例
similarities = [0.93, 0.81, 0.68]
threshold = 0.8
def match_results(scores, threshold):
return ["same_person" if score >= threshold else "different_person" for score in scores]
print(match_results(similarities, threshold))
预期输出:
['same_person', 'same_person', 'different_person']
阈值为 0.8 时,前两个分数会被接受为同一个人,最后一个会被拒绝。如果提高阈值,中间那个样本可能从“接受”变成“拒绝”。
这个示例很小,但它能帮助新人立住一个系统直觉:
- 人脸识别很多时候不是“模型告诉你答案”
- 而是“模型给分数,系统再根据阈值做决定”
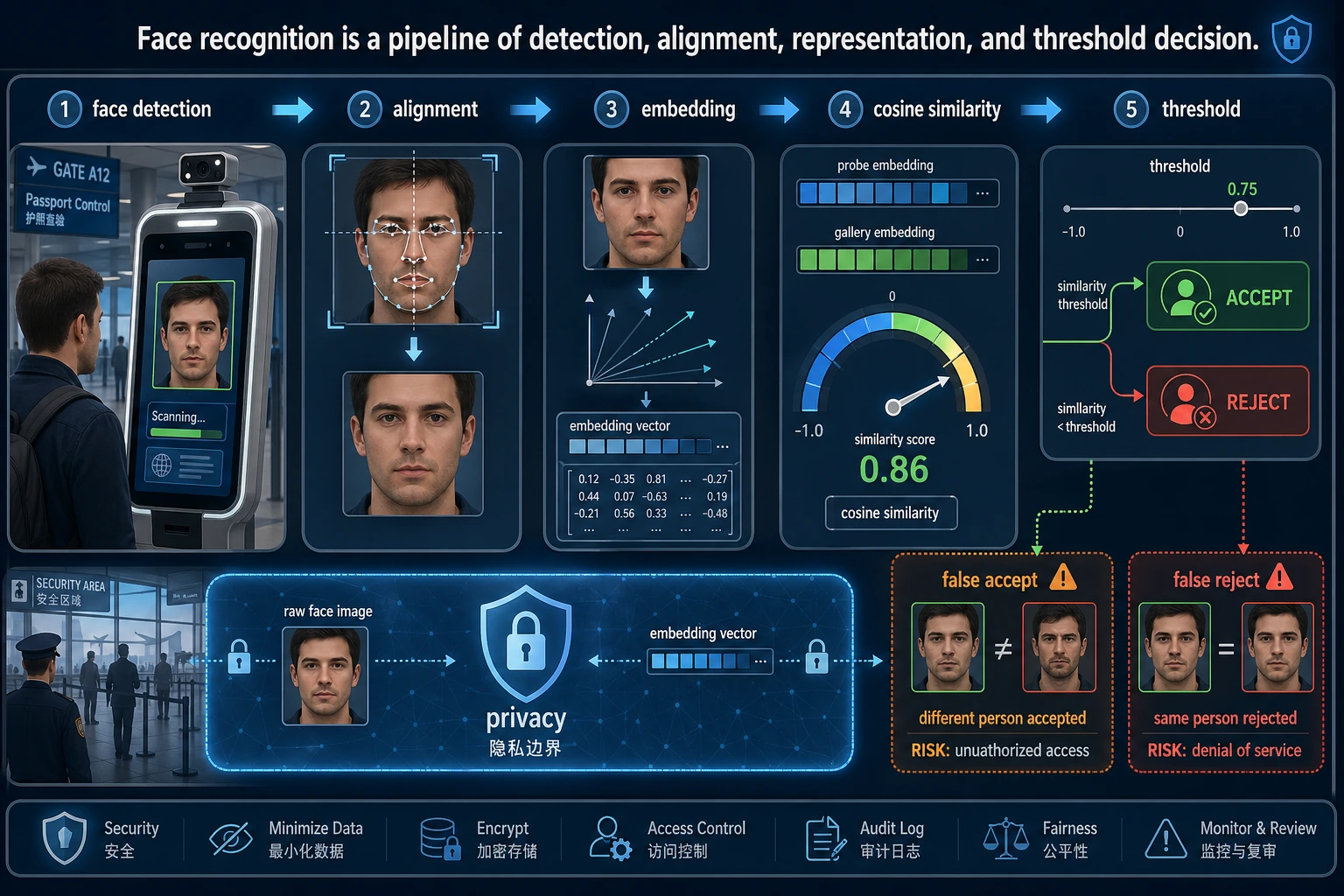
人脸系统不是一个模型:检测先找脸,对齐让输入可比,embedding 做相似度表示,阈值决定 same / different。阈值太松会误识,太严会漏识。
三、最常见误区
只看检测,不看对齐
对齐往往会直接影响后续识别稳定性。
只看相似度,不看阈值风险
阈值设太宽容易误识, 设太严又容易漏识。
忽略隐私和合规
人脸任务几乎天然带有更高合规要求。
只展示成功识别,不展示误识和拒识
如果只展示:
- 成功认出了谁
那这个项目更像演示,而不像系统。 更像真实项目的展示应该同时包括:
- 正确识别
- 错误匹配
- 本该拒绝但阈值太松的样例
- 本该识别却被阈值拒掉的样例
四、为什么这一节特别适合训练“系统思维”?
因为它会逼你意识到:
- 单一模型结果不等于完整系统能力
- 阈值、误识、漏识、合规都会进入最终判断
这和很多真实 CV 系统都很像。
一个新人可直接照抄的学习顺序
更稳的顺序通常是:
- 先理解检测
- 再理解对齐
- 再理解 embedding 相似度
- 最后再看阈值和系统风险
如果一开始就只盯识别模型,反而最容易看不懂整条链。
如果把它做成项目,最值得先展示什么
更像真实项目的展示顺序通常是:
- 原图中的检测框
- 对齐前后对比
- 两张脸的 embedding 相似度
- 不同阈值下的匹配结果
- 误识 / 漏识 / 拒识案例
这样读者一眼就能看懂:
- 问题出在检测
- 还是对齐
- 还是阈值本身
如果把它做成项目,最值得展示什么
- 检测结果
- 对齐前后对比
- embedding 相似度对比
- 不同阈值下的误识 / 漏识变化
这样会比只贴“识别成功截图”更像真正项目。
小结
这节最重要的是建立一个系统判断:
人脸检测与识别不是单一模型问题,而是一条从检测到匹配的完整流水线。
这节最该带走什么
- 人脸系统本质上是流水线
- embedding 和阈值决定后续匹配体验
- 这类系统天然比普通视觉任务更需要考虑风险和合规
练习
- 自己构造几组向量,看看相似度阈值怎么影响匹配判断。
- 为什么说人脸系统特别依赖阈值设置?
- 对齐为什么会影响识别质量?
- 想一想:人脸系统为什么要特别重视隐私?