8.3.2 大模型 API 调用实践
很多人第一次做 LLM 应用时,停留在“我会调用一下接口”。 但真实开发里,真正重要的是:
怎样把模型调用从一次性 demo,变成稳定、可维护的应用能力。
这一节就从最小请求开始,一步步把这件事讲透。
学习目标
- 理解一个最小 LLM API 调用到底由哪些部分组成
- 知道请求、响应、参数、错误处理分别扮演什么角色
- 学会写一个最小但像样的 API 客户端封装
- 明白为什么“会调接口”和“能做应用”之间还差很多
一、为什么 API 调用是 LLM 应用开发的第一步?
因为这是模型真正进入系统的入口
你前面学的大多数概念,不管多强,最终到了应用里都要落到一件事:
- 发请求
- 拿结果
- 继续处理
所以 API 调用不是“基础杂活”,而是:
大模型能力进入产品的接口层。
一个经常被忽略的问题
很多人只在乎:
- 能不能拿到回复
但真实项目更关心:
- 回复是不是稳定
- 错误怎么处理
- token 成本怎么控制
- 多轮上下文怎么组织
所以这一节的重点不是“会发个 HTTP 请求”,而是“会围绕一次模型调用设计应用代码”。
二、一个最小聊天请求到底包含什么?
最核心的一组要素通常包括:
- 模型名
- 消息列表
- 温度等参数
- 返回内容
你可以先把它理解成:
把任务说明、上下文和控制参数一起交给模型。
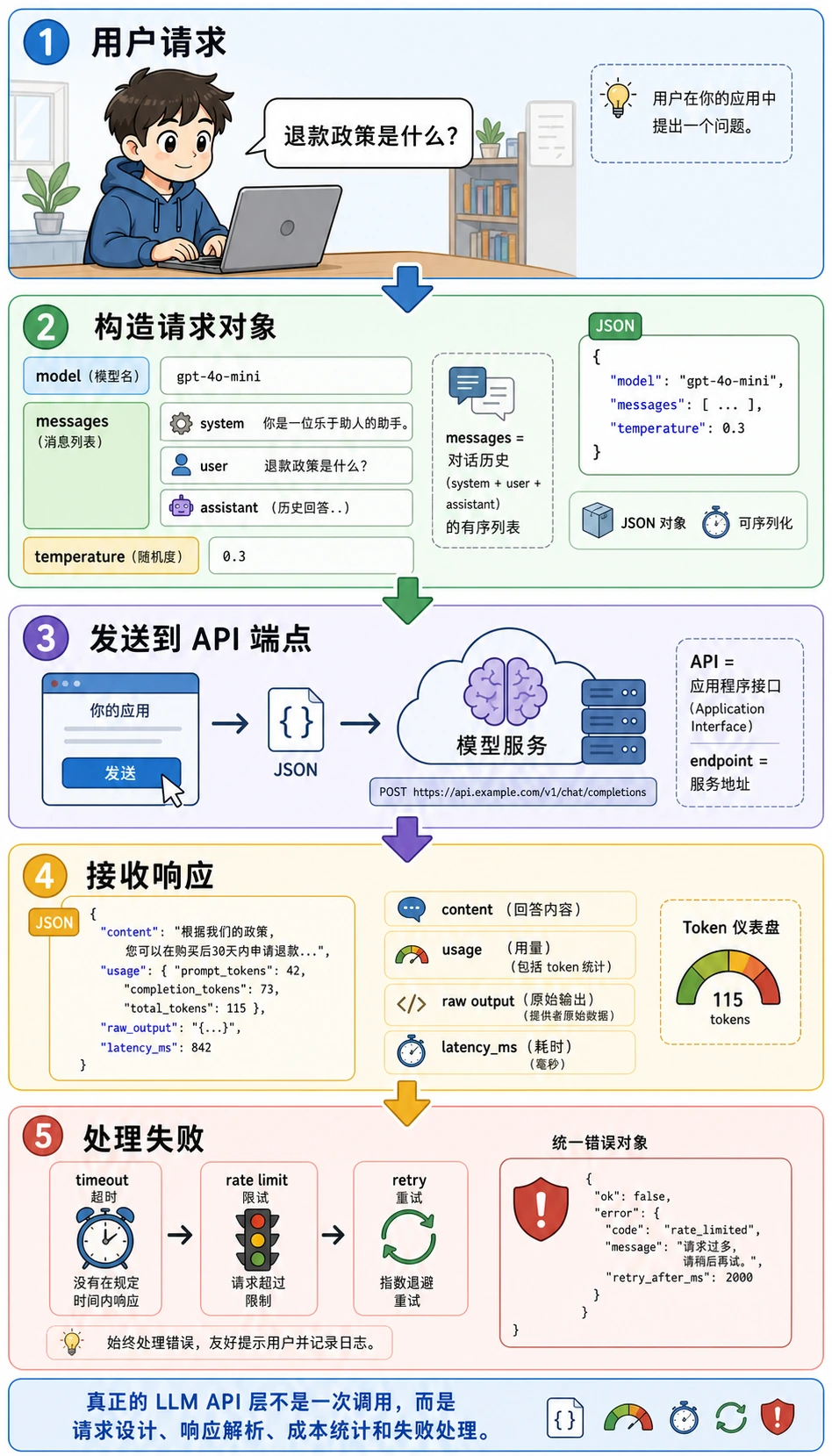
不要把这张图看成“一行调用代码”,而要看成一个运行闭环。API 是应用程序接口,endpoint 是服务地址,JSON 是网络传输里常用的结构化数据格式,usage 记录 token 用量,方便后续做成本和性能分析。
一个最小请求示意
request = {
"model": "demo-chat-model",
"messages": [
{"role": "system", "content": "你是一个课程助手。"},
{"role": "user", "content": "退款政策是什么?"}
],
"temperature": 0.2
}
print(request)
预期输出:
{'model': 'demo-chat-model', 'messages': [{'role': 'system', 'content': '你是一个课程助手。'}, {'role': 'user', 'content': '退款政策是什么?'}], 'temperature': 0.2}
为什么 messages 是列表?
因为聊天模型通常不是只看一条字符串,而是看:
- system 指令
- user 提问
- assistant 历史回答
这样它才能更好理解多轮对话背景。
三、先做一个“离线 mock 客户端”
为了保证代码可直接运行,我们先不用真实网络请求,而是写一个最小模拟版 client。
class MockLLMClient:
def chat(self, messages, model="demo-chat-model", temperature=0.2):
user_message = messages[-1]["content"]
if "退款" in user_message:
reply = "课程购买后 7 天内且学习进度低于 20% 可申请退款。"
elif "证书" in user_message:
reply = "完成所有必修项目并通过结课测试后,可以获得结业证书。"
else:
reply = "这是一个模拟回复。"
return {
"model": model,
"content": reply,
"usage": {
"prompt_tokens": 42,
"completion_tokens": 18
}
}
client = MockLLMClient()
response = client.chat([
{"role": "system", "content": "你是课程助手。"},
{"role": "user", "content": "退款政策是什么?"}
])
print(response)
预期输出:
{'model': 'demo-chat-model', 'content': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}
为什么先做 mock 版?
因为这能让你先理解:
- 输入结构长什么样
- 输出结构长什么样
- 你的业务逻辑该放在哪
而不必一开始就被联网、鉴权和 SDK 细节分散注意力。
四、从“能调”走向“能用”
为什么不能在业务代码里到处直接写 API 调用?
如果你每个地方都写:
client.chat(...)
久了会遇到这些问题:
- 参数不统一
- system prompt 到处散
- 错误处理不一致
- 后面很难切模型或切 provider
一个更像项目代码的封装
class CourseAssistant:
def __init__(self, llm_client):
self.llm = llm_client
self.system_prompt = "你是一个课程助手,回答要准确、简洁。"
def ask(self, user_query):
messages = [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_query}
]
return self.llm.chat(messages)
assistant = CourseAssistant(MockLLMClient())
print(assistant.ask("证书怎么拿?"))
预期输出:
{'model': 'demo-chat-model', 'content': '完成所有必修项目并通过结课测试后,可以获得结业证书。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}
这个封装在教你什么?
它在教你:
模型调用通常应该藏在一个更稳定的应用层接口后面。
这一步非常重要,因为后面你会不断加:
- 业务 prompt
- tool calling
- logging
- retry
五、为什么响应解析同样重要?
你拿到模型输出后,通常不会直接就结束。 你还常常要继续做:
- 展示给用户
- 存数据库
- 进工作流
- 做后处理
所以你最好先习惯把响应拆出来看:
response = assistant.ask("退款政策是什么?")
print("reply =", response["content"])
print("usage =", response["usage"])
预期输出:
reply = 课程购买后 7 天内且学习进度低于 20% 可申请退款。
usage = {'prompt_tokens': 42, 'completion_tokens': 18}
这一步看似简单,但它在提醒你:
模型返回的不只是“文本”,还有很多有价值的元信息。
六、一个最关键的工程问题:错误处理
真实调用里最常见的情况不是“永远成功”,而是:
- 超时
- 限流
- 网络异常
- 服务端错误
一个最小错误处理示例
class UnstableMockLLMClient:
def __init__(self):
self.fail_once = True
def chat(self, messages, model="demo-chat-model", temperature=0.2):
if self.fail_once:
self.fail_once = False
raise RuntimeError("temporary_api_error")
return {
"model": model,
"content": "重试后成功返回。",
"usage": {"prompt_tokens": 20, "completion_tokens": 6}
}
def safe_chat(client, messages):
try:
return client.chat(messages)
except Exception as e:
return {"error": str(e)}
client = UnstableMockLLMClient()
messages = [{"role": "user", "content": "你好"}]
print(safe_chat(client, messages))
print(safe_chat(client, messages))
预期输出:
{'error': 'temporary_api_error'}
{'model': 'demo-chat-model', 'content': '重试后成功返回。', 'usage': {'prompt_tokens': 20, 'completion_tokens': 6}}
为什么这一层一定要认真做?
因为一旦模型调用成了系统中间的一环,错误就不只是“用户没回复”,而是:
- 后面工作流可能全断
- 日志和统计会失真
- 用户体验会突然变差
七、一个真实感更强的重试示例
def retry_chat(client, messages, retries=2):
last_error = None
for _ in range(retries + 1):
try:
return client.chat(messages)
except Exception as e:
last_error = str(e)
return {"error": last_error}
client = UnstableMockLLMClient()
print(retry_chat(client, [{"role": "user", "content": "你好"}]))
预期输出:
{'model': 'demo-chat-model', 'content': '重试后成功返回。', 'usage': {'prompt_tokens': 20, 'completion_tokens': 6}}
这个例子在教你:
API 调用一旦进了工程系统,重试往往不是加分项,而是基础能力。
八、真实项目里还要继续补哪些东西?
当你从 mock 走向真实 API 时,通常还要补:
- 鉴权
- 模型切换
- token 成本统计
- 日志与 trace
- timeout
- provider 适配层
所以真实项目里的 LLM API 层,通常既像:
- 模型入口
也像:
- 一个运行时中间层
九、最常见的误区
以为“拿到 content”就够了
其实 usage、错误结构、trace 信息也很重要。
业务代码里到处散着 client.chat(...)
这会让后面维护很痛苦。
没有统一错误处理
一到线上问题就很容易暴露出来。
LLM API 最小工程规范
当你开始把 API 调用接进真实项目时,可以先用下面这张表检查自己的封装是否够稳。
| 检查项 | 最低要求 | 为什么重要 |
|---|---|---|
| 配置管理 | API key、model、base_url 不写死在业务函数里 | 便于切换环境和保护密钥 |
| 统一入口 | 所有模型调用经过同一个 client 或 service | 便于加日志、重试、限流和成本统计 |
| 超时设置 | 每次请求都有 timeout | 防止一个请求卡住整个流程 |
| 重试策略 | 只对临时错误重试,且有最大次数 | 防止无限重试和成本失控 |
| 错误结构 | 失败时返回统一 error 对象 | 上层业务能稳定处理失败 |
| usage 记录 | 记录 token、模型名、耗时 | 后续才能分析成本和性能 |
| 原始输出保留 | 保存 raw output 或关键 trace | 出错时能复盘模型到底返回了什么 |
这张表的重点是让 API 层成为“稳定接口”,而不是散落在代码里的若干次模型请求。后面的 RAG、结构化输出、Function Calling 和 Agent 都会依赖这一层。
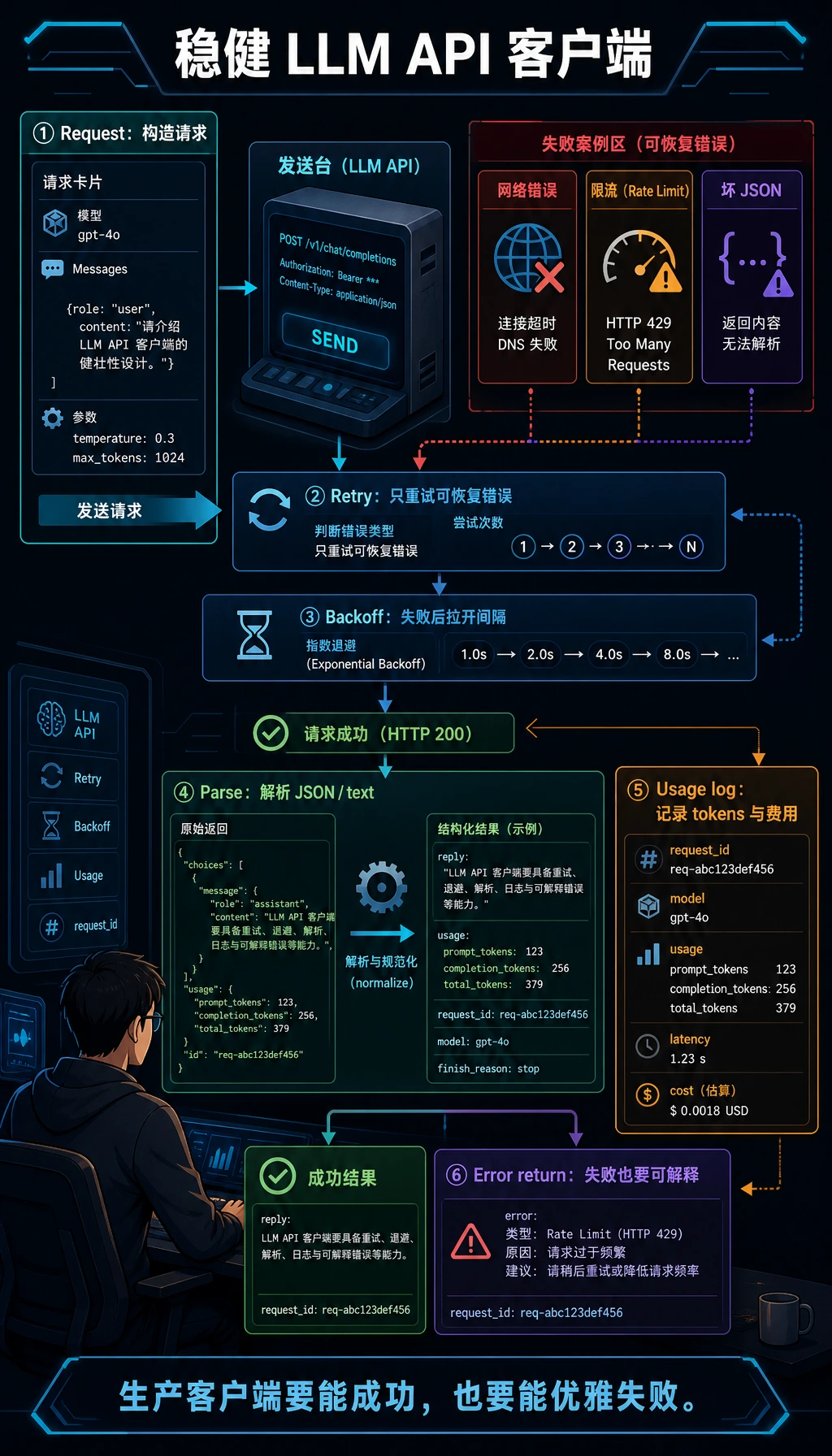
一次模型调用进入项目后,就不再只是 client.chat()。图里把配置、timeout、retry、统一响应、usage、日志和 raw output 放在同一圈,是为了提醒你 API 层要先变成稳定运行时。
一个更像真实项目的响应结构
建议你从一开始就让模型调用返回统一结构,而不是有时返回字符串、有时返回字典、有时抛异常。
import time
def llm_response(ok, content=None, usage=None, error=None, raw=None, latency_ms=0):
return {
"ok": ok,
"content": content,
"usage": usage or {},
"error": error,
"raw": raw,
"latency_ms": latency_ms,
}
def robust_chat(client, messages):
start = time.time()
try:
raw = client.chat(messages)
latency_ms = int((time.time() - start) * 1000)
return llm_response(
ok=True,
content=raw.get("content"),
usage=raw.get("usage"),
raw=raw,
latency_ms=latency_ms,
)
except Exception as e:
latency_ms = int((time.time() - start) * 1000)
return llm_response(ok=False, error=str(e), latency_ms=latency_ms)
print(robust_chat(MockLLMClient(), [{"role": "user", "content": "退款政策是什么?"}]))
示例输出:
{'ok': True, 'content': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}, 'error': None, 'raw': {'model': 'demo-chat-model', 'content': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}, 'latency_ms': 0}
因为这里没有真实网络请求,latency_ms 很可能是 0。换成真实 API 后,它会变成最值得优先观察的信号之一。
这个封装会让上层业务更容易判断:调用是否成功,内容在哪里,token 用了多少,失败原因是什么,请求花了多久。
API 调用日志应该记录什么
LLM 应用出问题时,如果没有日志,通常只能靠猜。建议至少记录这些字段:
| 字段 | 示例 | 用途 |
|---|---|---|
request_id | req_001 | 串联一次调用的上下文 |
model | demo-chat-model | 对比不同模型表现 |
prompt_version | course_assistant_v1 | 追踪是哪版 prompt 出的问题 |
input_preview | 退款政策是什么 | 快速定位用户输入 |
output_preview | 课程购买后 7 天内... | 快速查看模型输出 |
prompt_tokens | 42 | 成本分析 |
completion_tokens | 18 | 成本分析 |
latency_ms | 850 | 性能分析 |
error | timeout | 失败归因 |
注意日志里不要直接保存敏感信息。真实项目里应当对用户隐私、密钥、内部资料做脱敏或权限控制。
小结
这一节最重要的不是“会调用一次模型”,而是理解:
大模型 API 调用真正的工程价值,在于把模型能力包装成可重复、可维护、可扩展的系统接口。
只要这个视角建立起来,后面你再学 LangChain、对话系统、Agent 工具层时,就会自然很多。
练习
- 把
MockLLMClient扩展成能处理“学习顺序”问题。 - 给
CourseAssistant增加一个统一错误返回结构。 - 想一想:为什么真实项目里不应该让业务代码到处直接拼
messages? - 用自己的话解释:为什么说“会调 API”和“会做 LLM 应用”之间还差了一层系统设计?