8.3.5 HuggingFace 生态深入
很多人第一次接触 HuggingFace,会先看到:
- 模型能下载
- pipeline 很方便
但真正要理解它在工程里的价值,不能只看某个 API,而要看它为什么会形成一个完整生态。
学习目标
- 理解 HuggingFace 生态里最关键的几层分别是什么
- 分清模型、数据、分词器、pipeline 和 hub 的角色
- 理解它为什么会成为 LLM 应用的“基础设施生态”
- 建立什么时候只用 pipeline、什么时候要往底层走的判断
HuggingFace 为什么不只是一个模型库?
很多人对它的第一印象
通常是:
- 能下载模型
- 能快速推理
这当然对,但还不够完整。
更准确的理解
HuggingFace 更像一个围绕模型使用的完整生态:
- 模型仓库
- 数据集工具
- 分词器工具
- 推理接口
- 训练与微调基础组件
所以它的重要性不只是“有很多模型”,而是:
让模型从研究走向使用的整个路径都更顺了。
先把生态的几个关键层分清
Tokenizers
负责把文本变成模型可吃的 token。
Models
负责真正的前向计算。
Datasets
负责组织和处理训练 / 评估数据。
Pipelines
负责把常见任务包装成一键调用接口。
Hub
负责:
- 托管模型
- 托管数据集
- 分享配置和卡片说明
一句话先记:
HuggingFace 不是一个点工具,而是一整条模型使用链的生态。
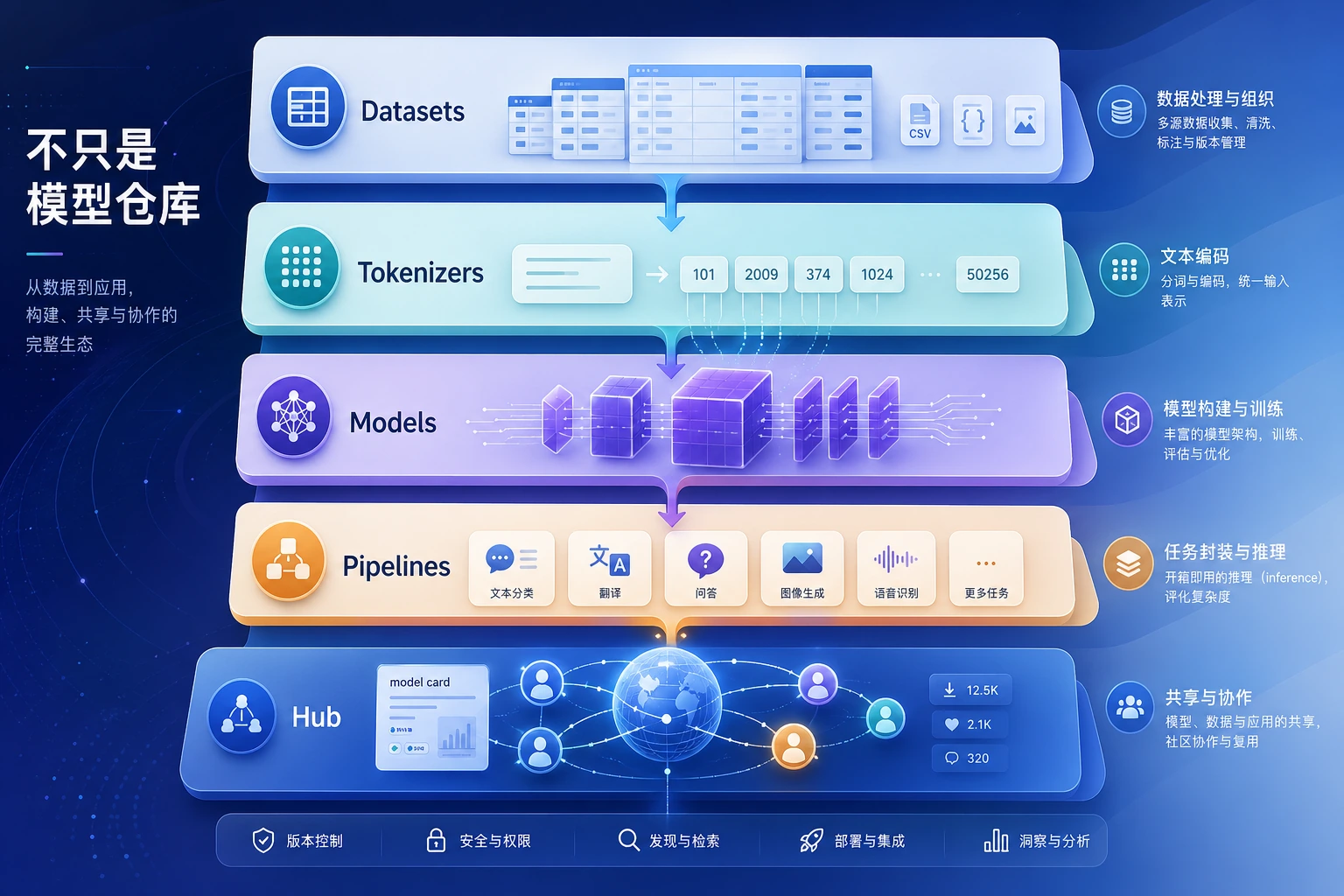
从下往上看:Datasets 供给数据,Tokenizers 规定输入,Models 做计算,Pipelines 提供任务级快捷入口,Hub 负责共享和协作。不要只把 HuggingFace 理解成“下载模型的网站”。
为什么 Tokenizer 在工程里特别重要?
因为模型并不直接理解原始文本。 它先看到的是:
- token ids
所以 tokenizer 决定了:
- 文本怎样切
- 特殊符号怎样处理
- 长度怎样截断或补齐
这意味着 tokenizer 不是小细节,而是模型输入层的关键规则。
一个很小的示意
tokenizer_layer = {
"text": "退款政策是什么?",
"tokens": ["退", "款", "政", "策", "是", "什", "么", "?"],
"input_ids": [101, 23, 45, 67, 89]
}
print(tokenizer_layer)
预期输出:
{'text': '退款政策是什么?', 'tokens': ['退', '款', '政', '策', '是', '什', '么', '?'], 'input_ids': [101, 23, 45, 67, 89]}
后面使用 transformers 里的真实 tokenizer 时,token ids 会由模型词表生成,不需要你手写。这里要抓住的工程重点是:模型真正接收的是 ids 和 mask,而不是原始句子。
为什么 pipeline 这么受欢迎?
因为它特别适合快速验证
比如你只想快速试一下:
- 情感分类
- 文本摘要
- 文本生成
pipeline 可以让你少写很多样板代码。
一个最小示意
class MockPipeline:
def __call__(self, text):
return [{"label": "positive", "score": 0.91, "text": text}]
pipe = MockPipeline()
print(pipe("这节课讲得很清楚"))
预期输出:
[{'label': 'positive', 'score': 0.91, 'text': '这节课讲得很清楚'}]
这个例子最重要的不是结果本身,而是让你意识到:
pipeline 更像“任务级快捷入口”。
它的价值是快,但这也意味着它通常不是最底层、最可控的那层。
什么时候不能只靠 pipeline?
如果你开始需要:
- 自定义 batch
- 更精细的前后处理
- 自定义训练或评估
- 更复杂的系统嵌入
那就往往要从:
- pipeline
往下走到:
- tokenizer + model
这也是一个很重要的工程判断:
pipeline 适合快速上手,不一定适合所有复杂生产场景。
为什么 model hub 这么关键?
因为它解决了:
- 模型怎么分享
- 数据集怎么分享
- 配置怎么对齐
- 说明文档怎么附着
这让很多模型生态从:
- 论文里的名字
变成:
- 能真正被别人拉下来试用的资源
所以 HuggingFace 的价值很大一部分其实不在单个 API,而在:
它把模型世界组织成了可协作的公共基础设施。
Datasets 为什么也不能忽略?
很多初学者会只盯模型,却忽略数据层。 但真实工程里:
- 数据怎样读取
- 怎样切分
- 怎样过滤
同样是大事。
所以 HuggingFace 生态之所以强,不只是因为模型多,而是因为:
- 模型和数据链条都被组织起来了
一个实用的使用层级判断
可以先这样记:
- 想快速试效果:先 pipeline
- 想做精细控制:看 tokenizer + model
- 想做训练 / 微调:再进一步看数据和训练链路
这个顺序很重要,因为很多人一上来就直接啃底层,反而容易被细节淹没。
动手判断:写代码前先选 HuggingFace 层级
在导入大型库或下载模型之前,先写清楚目标,再选择能解决问题的最浅一层。这样能节省时间,也能让项目更容易调试。
def choose_hf_layer(goal):
rules = [
("快速情感", "pipeline", "用任务级快捷入口快速验证想法"),
("自定义预处理", "tokenizer + model", "控制截断、补齐、批处理和后处理"),
("微调", "datasets + trainer", "控制样本、切分、指标和训练"),
("分享", "hub", "用 model card 和配置发布产物"),
]
for keyword, layer, reason in rules:
if keyword in goal:
return {"goal": goal, "layer": layer, "reason": reason}
return {"goal": goal, "layer": "先从 pipeline 开始", "reason": "先验证任务,再在遇到限制时往底层走"}
goals = [
"快速情感分类演示",
"自定义预处理长客服工单",
"微调一个领域分类器",
"分享一个课件生成模型",
]
for item in goals:
plan = choose_hf_layer(item)
print(f"{plan['goal']} -> {plan['layer']} | {plan['reason']}")
预期输出:
快速情感分类演示 -> pipeline | 用任务级快捷入口快速验证想法
自定义预处理长客服工单 -> tokenizer + model | 控制截断、补齐、批处理和后处理
微调一个领域分类器 -> datasets + trainer | 控制样本、切分、指标和训练
分享一个课件生成模型 -> hub | 用 model card 和配置发布产物
这个小练习在真实项目里很有用:如果你说不清为什么要从 pipeline 下沉到 tokenizer + model,大概率是过早增加了复杂度。
真实联网实验时,可以使用当前稳定的 Hugging Face 包:python -m pip install -U transformers datasets tokenizers accelerate,再把这里的 mock 示例换成 transformers.pipeline(...) 或 AutoTokenizer + AutoModel...。项目笔记里要固定 model id,方便团队复现同样行为。
初学者最常踩的坑
以为 HuggingFace 只是模型仓库
其实它更像完整生态。
只会 pipeline,不懂底层链路
一到复杂工程就容易卡住。
只看模型,不看 tokenizer 和数据
这样会让你对系统理解一直停留在表层。
小结
这一节最重要的不是记住几个库名,而是理解:
HuggingFace 的真正价值,在于它把模型、数据、分词器、推理接口和分享机制组织成了一条完整生态链。
理解这一点,你后面看模型应用和微调时,就会更清楚它到底为什么这么重要。
练习
- 用自己的话解释:为什么说 HuggingFace 不只是一个模型仓库?
- 想一想:pipeline 为什么适合快速验证,但不总适合复杂生产系统?
- 如果你要做一个真实项目,为什么 tokenizer 和数据层也必须纳入视野?
- 用自己的话总结:Hub、pipeline、model、tokenizer 各自更像在解决什么问题?