8.3.5 HuggingFace エコシステムを深く理解する
HuggingFace に初めて触れると、多くの人はまず次のような点に目が行きます。
- モデルをダウンロードできる
- pipeline がとても便利
でも、実際にそれがエンジニアリングでどんな価値を持つのかを理解するには、ある API だけを見るのではなく、なぜそれが一つの完全なエコシステムを形成しているのかを見る必要があります。
学習目標
- HuggingFace エコシステムの中で、特に重要な層が何かを理解する
- モデル、データ、トークナイザー、pipeline、hub の役割を区別できるようにする
- なぜ HuggingFace が LLM アプリの「基盤インフラ」になるのかを理解する
- いつ pipeline だけでよくて、いつより下層まで見に行くべきかを判断できるようにする
HuggingFace はなぜ単なるモデルライブラリではないのか?
多くの人の第一印象
だいたい次のようなものです。
- モデルをダウンロードできる
- すぐに推論できる
もちろんそれも正しいですが、まだ十分ではありません。
より正確な理解
HuggingFace は、モデル利用を中心にした完全なエコシステムに近いです。
- モデルのリポジトリ
- データセットツール
- トークナイザーツール
- 推論インターフェース
- 学習と微調整のための基礎コンポーネント
つまり、その重要性は「たくさんのモデルがある」ことだけではなく、むしろ:
モデルが研究から実利用へ進むまでの道筋全体を、よりスムーズにしてくれることです。
まずエコシステムの重要な層を整理する
Tokenizers
テキストを、モデルが扱える token に変換する役割です。
Models
実際の forward 計算を担当します。
Datasets
学習 / 評価データを整理・処理します。
Pipelines
よくあるタスクをワンクリックで呼び出せる形にまとめます。
Hub
次の役割を担います。
- モデルのホスティング
- データセットのホスティング
- 設定やカード説明の共有
まず一言で覚えるなら:
HuggingFace は一点のツールではなく、モデル利用のための一連のチェーン全体を支えるエコシステムです。
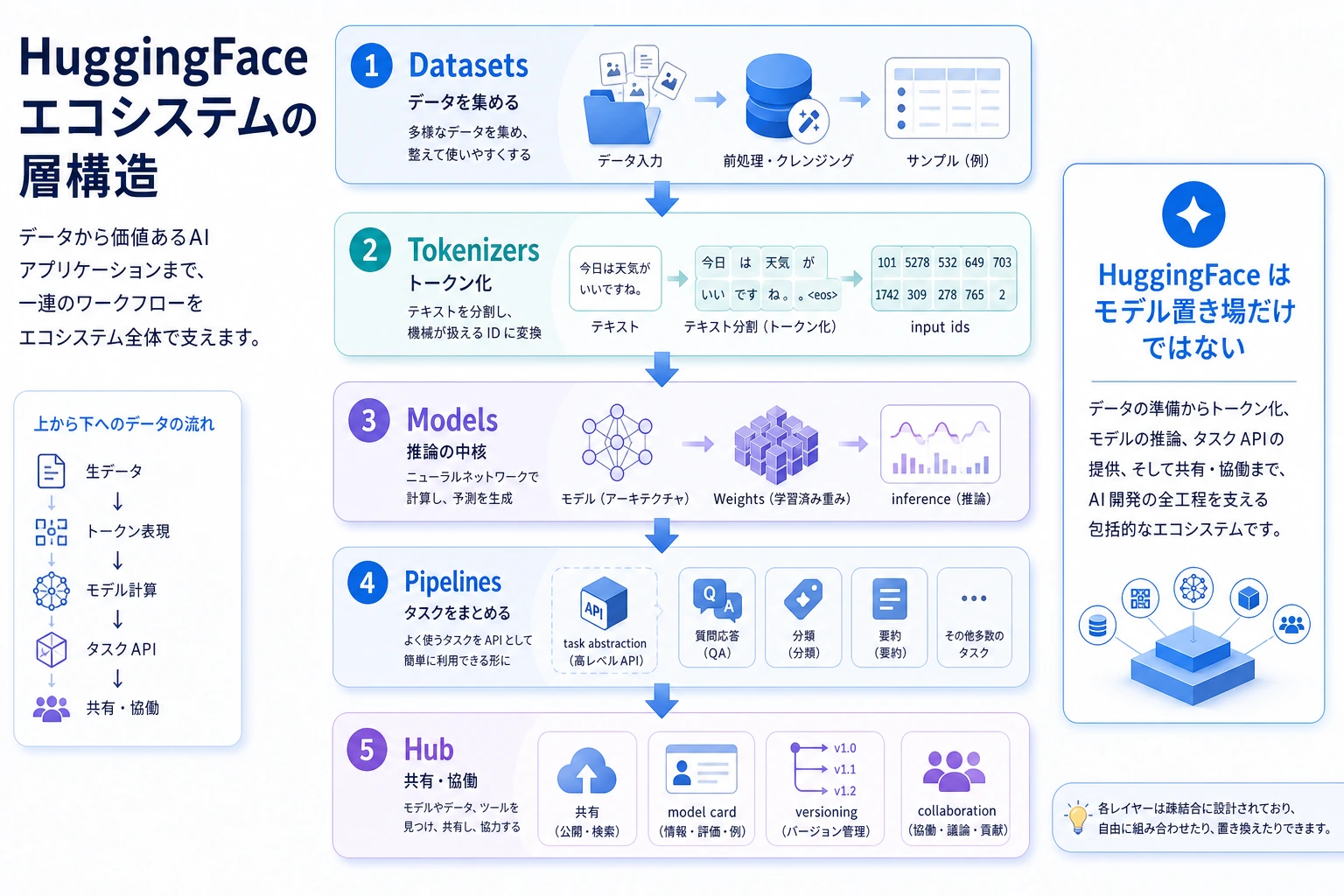
下から上へ見ていきます。Datasets がデータを供給し、Tokenizers が入力を定義し、Models が計算を行い、Pipelines がタスク単位の簡単な入口を提供し、Hub が共有と協働を担当します。HuggingFace を「モデルをダウンロードするサイト」とだけ理解しないようにしましょう。
なぜ Tokenizer はエンジニアリングで特に重要なのか?
なぜなら、モデルは生のテキストを直接理解するわけではないからです。
最初に見るのは次のようなものです。
- token ids
つまり tokenizer が決めるのは次の点です。
- テキストをどう分割するか
- 特殊記号をどう扱うか
- 長さをどう切り詰めるか、またはどうパディングするか
これは、tokenizer が小さな細部ではなく、モデル入力層における重要なルールであることを意味します。
小さな例
tokenizer_layer = {
"text": "返品ポリシーは何ですか?",
"tokens": ["返", "品", "ポ", "リ", "シ", "ー", "は", "何", "で", "す", "か", "?"],
"input_ids": [101, 23, 45, 67, 89]
}
print(tokenizer_layer)
想定出力:
{'text': '返品ポリシーは何ですか?', 'tokens': ['返', '品', 'ポ', 'リ', 'シ', 'ー', 'は', '何', 'で', 'す', 'か', '?'], 'input_ids': [101, 23, 45, 67, 89]}
後で transformers の実際の tokenizer を使うと、token ids はモデルの語彙から生成されます。ここで大事なのは、モデルが受け取るのは生の文章ではなく、ids と mask だという点です。
なぜ pipeline はこんなに人気なのか?
すぐに検証するのに特に向いているから
たとえば、次のようなものを素早く試したいとします。
- 感情分類
- テキスト要約
- テキスト生成
pipeline を使うと、たくさんの定型コードを減らせます。
最小例
class MockPipeline:
def __call__(self, text):
return [{"label": "positive", "score": 0.91, "text": text}]
pipe = MockPipeline()
print(pipe("この授業はとても分かりやすかったです"))
想定出力:
[{'label': 'positive', 'score': 0.91, 'text': 'この授業はとても分かりやすかったです'}]
この例で大事なのは結果そのものではなく、次の点を意識することです。
pipeline は「タスク単位の簡単な入口」に近いものです。
その価値は速さにありますが、同時に、たいていは最も低レベルで最も制御しやすい層ではない、ということでもあります。
いつ pipeline だけでは足りないのか?
次のようなことが必要になったら、pipeline だけでは難しくなることが多いです。
- カスタム batch
- より細かい前処理・後処理
- カスタム学習や評価
- より複雑なシステムへの組み込み
その場合は、たいてい次の層まで降りていく必要があります。
- pipeline
そこからさらに下へ:
- tokenizer + model
これはとても重要なエンジニアリング判断です。
pipeline は素早い導入に向いていますが、すべての複雑な本番シナリオに向いているわけではありません。
なぜ model hub はこんなに重要なのか?
それは次の問題を解決してくれるからです。
- モデルをどう共有するか
- データセットをどう共有するか
- 設定をどう揃えるか
- 説明ドキュメントをどう添えるか
これによって、多くのモデルエコシステムは次のような状態から:
- 論文の中の名前
次のように変わります。
- 実際に他の人がダウンロードして試せるリソース
だからこそ、HuggingFace の価値の大部分は個別の API ではなく、むしろ次にあります。
モデルの世界を、協働できる公共インフラとして整理していることです。
なぜ Datasets も見逃せないのか?
初心者はモデルだけに注目して、データ層を見落としがちです。
でも実際のエンジニアリングでは、次のこともとても重要です。
- データをどう読み込むか
- どう分割するか
- どうフィルタリングするか
なので、HuggingFace エコシステムが強いのは、モデルが多いからだけではなく、次の点にもあります。
- モデルとデータの流れがきちんと整理されている
実用的な使用レベルの判断
まずはこう覚えるとよいでしょう。
- すぐに効果を試したい:まず pipeline
- 細かく制御したい:tokenizer + model を見る
- 学習 / 微調整をしたい:さらにデータと学習の流れを見る
この順番は重要です。最初からいきなり下層ばかり追うと、細部に埋もれてしまいやすいからです。
実践:コードを書く前に HuggingFace の層を選ぶ
大きなライブラリを import したりモデルをダウンロードしたりする前に、まず目的を書き出し、それを解決できる一番浅い層を選びます。これだけで時間を節約でき、デバッグもしやすくなります。
def choose_hf_layer(goal):
rules = [
("簡単な感情", "pipeline", "タスク単位の入口で素早く検証する"),
("独自前処理", "tokenizer + model", "切り詰め、padding、batch、後処理を制御する"),
("微調整", "datasets + trainer", "サンプル、分割、指標、学習を制御する"),
("共有", "hub", "model card と設定つきで成果物を公開する"),
]
for keyword, layer, reason in rules:
if keyword in goal:
return {"goal": goal, "layer": layer, "reason": reason}
return {"goal": goal, "layer": "まず pipeline から始める", "reason": "まずタスクを検証し、詰まったときだけ下層へ進む"}
goals = [
"簡単な感情分類デモ",
"独自前処理つきの長いサポートチケット",
"領域分類器を微調整する",
"教材生成モデルを共有する",
]
for item in goals:
plan = choose_hf_layer(item)
print(f"{plan['goal']} -> {plan['layer']} | {plan['reason']}")
想定出力:
簡単な感情分類デモ -> pipeline | タスク単位の入口で素早く検証する
独自前処理つきの長いサポートチケット -> tokenizer + model | 切り詰め、padding、batch、後処理を制御する
領域分類器を微調整する -> datasets + trainer | サンプル、分割、指標、学習を制御する
教材生成モデルを共有する -> hub | model card と設定つきで成果物を公開する
この小さな練習は、実際のプロジェクトでも役立ちます。pipeline から tokenizer + model へ下りる理由を説明できないなら、複雑さを早く入れすぎている可能性があります。
実際にオンラインで試すときは、現在の安定した Hugging Face パッケージを python -m pip install -U transformers datasets tokenizers accelerate で入れ、この mock 例を transformers.pipeline(...) または AutoTokenizer + AutoModel... に置き換えます。チームで再現できるよう、プロジェクトメモには model id を固定して書いておきましょう。
初学者がよくハマる落とし穴
HuggingFace は単なるモデルリポジトリだと思ってしまう
実際には、もっと完全なエコシステムです。
pipeline しか使えず、下層の流れが分からない
少し複雑なエンジニアリングになると詰まりやすくなります。
モデルだけを見て、tokenizer とデータを見ない
そのままだと、システム理解がずっと表面的なままになってしまいます。
まとめ
この節で最も大事なのは、いくつかのライブラリ名を覚えることではなく、次を理解することです。
HuggingFace の本当の価値は、モデル、データ、トークナイザー、推論インターフェース、共有メカニズムを一つの完全なエコシステムチェーンとして整理している点にあります。
この点を理解すると、今後モデルアプリケーションや微調整を見るときに、なぜそれがこんなに重要なのかがよりはっきり分かるようになります。
練習
- 自分の言葉で説明してください:なぜ HuggingFace は単なるモデルリポジトリではないのですか?
- 考えてみてください:なぜ pipeline はすぐに検証するのに向いているのに、複雑な本番システムには必ずしも向いていないのですか?
- 実際のプロジェクトを作るなら、なぜ tokenizer とデータ層も視野に入れる必要があるのでしょうか?
- 自分の言葉でまとめてください:Hub、pipeline、model、tokenizer は、それぞれ何を解決しているものに近いですか?