8.3.3 LangChain の基礎
LangChain を初めて見ると、「モデルを少し調整するだけのもの」に見える人が多いです。
でも、本当に解決したい問題はもっと具体的です。
あなたのアプリがもう単発のモデル呼び出しではなく、複数ステップのコンポーネントの組み合わせになったとき、それをどう見通しよく整理するか?
これが LangChain の価値の入口です。
学習目標
- LangChain のようなチェーン型の抽象化が、なぜ自然に登場するのかを理解する
- Prompt、モデル、パーサー、検索器がチェーンの中でどこにあるかを理解する
- 最小例を通して、「前のステップの出力を次のステップへ渡す」感覚をつかむ
- それがなぜプロトタイプや線形ワークフローに向いているのかを理解する
まず地図を作ろう
この節では、初心者にとって一番わかりやすい順番は「先にフレームワーク API を学ぶ」ことではなく、まず次をはっきり見ることです。
つまり、この節が本当に解決したいのは次の点です。
- なぜチェーン型の抽象化が自然に生まれるのか
- それは一体、何を整理してくれるのか
一、なぜ「チェーン」という抽象化が必要なのか?
実際のアプリは、たいていモデルを 1 回呼ぶだけではないから
たとえば小さな QA システムを作るだけでも、次のようなステップがあります。
- ユーザーの query を整える
- 文書を検索する
- prompt を組み立てる
- モデルを呼ぶ
- 出力を整形する
これをすべて 1 つの関数に手書きしても動かせますが、すぐに次のような状態になりがちです。
- 見通しが悪い
- 再利用しにくい
- デバッグしにくい
チェーン型の抽象化は何をしているのか?
それはつまり、
各ステップを責務がはっきりした小さなコンポーネントにして、順番につなぐ
ということです。
これが LangChain の最も重要な感覚です。
二、最小のチェーン例
class SimpleChain:
def __init__(self, steps):
self.steps = steps
def run(self, value):
for step in self.steps:
value = step(value)
return value
def normalize_query(text):
return text.strip().lower()
def retrieve_docs(query):
if "返金" in query:
return {"query": query, "docs": ["コース購入後 7 日以内なら返金できます。"]}
return {"query": query, "docs": []}
def format_answer(payload):
if payload["docs"]:
return f"資料によると:{payload['docs'][0]}"
return "関連する資料が見つかりませんでした。"
chain = SimpleChain([
normalize_query,
retrieve_docs,
format_answer
])
print(chain.run(" 返金ポリシーは何ですか? "))
期待される出力:
資料によると:コース購入後 7 日以内なら返金できます。
このコードは何を教えているのか?
ここで教えているのは、LangChain の最も核心的な考え方です。
各ステップは自分の入出力だけに集中し、システム全体はそれをつないでタスクを完成させる。
これがチェーン型アプリケーションの一番重要な価値です。
三、Prompt はチェーンの中でどんな役割をするのか?
Prompt は「付属文」ではなく、1 つのコンポーネント
多くのワークフローでは、Prompt 自体が途中の 1 ステップになります。
- query を入力する
- もっとわかりやすい prompt テンプレートを作る
簡単な例
def build_prompt(payload):
docs = payload["docs"]
query = payload["query"]
return f"次の資料をもとに質問に答えてください:資料={docs},質問={query}"
payload = {"query": "返金ポリシーは何ですか", "docs": ["コース購入後 7 日以内なら返金できます。"]}
print(build_prompt(payload))
期待される出力:
次の資料をもとに質問に答えてください:資料=['コース購入後 7 日以内なら返金できます。'],質問=返金ポリシーは何ですか
この例が伝えているのは、
Prompt もチェーンの中の中間変換ノードとして見られる
ということです。
四、さらに「モデル」のステップを加える
オフラインでも動くように、ここでも mock model を使います。
def mock_llm(prompt):
return f"モデル出力:{prompt}"
chain = SimpleChain([
normalize_query,
retrieve_docs,
build_prompt,
mock_llm
])
print(chain.run("返金ポリシーは何ですか?"))
期待される出力:
モデル出力:次の資料をもとに質問に答えてください:資料=['コース購入後 7 日以内なら返金できます。'],質問=返金ポリシーは何ですか?
このステップでいちばん大事な気づき
次のものが見えてきます。
- 検索器
- prompt builder
- model
これらは実は、チェーン上の別々のノードにすぎません。
LangChain が「コンポーネントを組み立てるフレームワーク」に見えるのは、このためです。
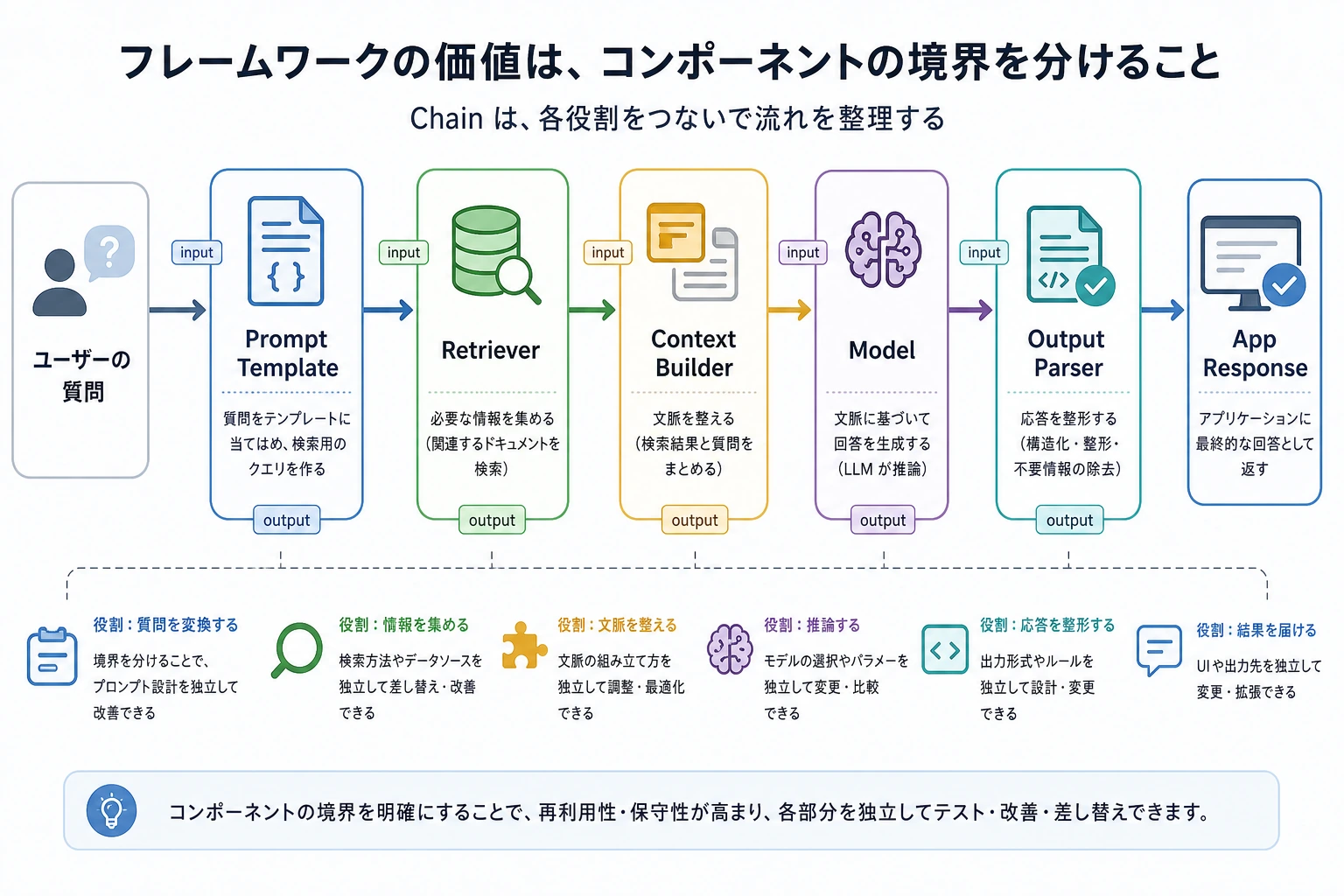
LangChain はコードをかっこよく見せるためのものではなく、Prompt、Retriever、Model、Output Parser などのノード間の入出力境界をはっきり分けるためのものです。初心者はまず「データがどのノードから次のノードへ流れるか」を見てください。
五、なぜ出力パーサーも重要なのか?
多くの人は入力 prompt とモデル出力だけに注目しますが、次のことを忘れがちです。
モデルが出力したあとも、システムはしばしば構造化処理を続ける必要がある。
たとえば:
- 一部のフィールドだけ取り出す
- JSON に変換する
- フロントエンド表示用の形式にマッピングする
最小例
def output_parser(text):
return {
"answer": text.replace("モデル出力:", ""),
"ok": True
}
chain = SimpleChain([
normalize_query,
retrieve_docs,
build_prompt,
mock_llm,
output_parser
])
print(chain.run("返金ポリシーは何ですか?"))
期待される出力:
{'answer': "次の資料をもとに質問に答えてください:資料=['コース購入後 7 日以内なら返金できます。'],質問=返金ポリシーは何ですか?", 'ok': True}
これで次のことが、よりはっきりわかるようになります。
LangChain の本当の価値は、「異なるコンポーネントの境界をきれいに分けること」にあることが多い。
六、なぜプロトタイプに特に向いているのか?
それは、初期の LLM アプリは多くの場合、次のような形だからです。
- 比較的線形なフロー
- 複数のコンポーネントが順番に実行される
たとえば:
- query を整える
- 検索する
- prompt を組み立てる
- モデルを呼ぶ
- 結果を解析する
これはまさに、チェーン型の抽象化が最も気持ちよくハマる場面です。
七、いつから苦しくなるのか?
フローが次のようになってくると、だんだん直線的なチェーンではつらくなります。
- 検索に失敗したら query を書き換えてもう一度検索する
- 答えが十分に安定していなければ reviewer に再チェックさせる
- あるリクエストはツールを使い、別のリクエストは使わない
このような場合、「1 本の直線チェーン」だけではだんだん無理が出てきます。
つまり、
システムに明確な状態分岐やループが出てきたら、チェーン型の抽象化だけでは足りないことがある。
これが、後で LangGraph のような、よりグラフ指向のフレームワークが必要になる理由です。
八、とても重要な実装上の注意
LangChain を学ぶときに、最もよくある失敗は次のようなものです。
- 最初からたくさんのクラス名やインターフェースを覚えようとする
でも、より安定した学び方はたいてい次の順番です。
- まずチェーン型の抽象化が何を解決するのかを理解する
- そのあとで具体的な API を見る
そうしないと、次のようになりやすいです。
- フレームワークのコードは書ける
- でも、なぜそのように組むのかがわからない
初心者が最初に LangChain を使うときの安定した方法
一般に、次の順番がいちばん安全です。
- まずは 1 本の線形チェーンだけ作る
- 各ノードの入出力をまずはっきり表示する
- そのあとで検索、パーサー、より複雑なコンポーネントを追加する
- 最後に、より複雑なグラフ型ワークフローを考える
まとめ
この節でいちばん大事なのは、特定のクラス名を覚えることではなく、次を理解することです。
LangChain の核心的な価値は、「prompt、検索、モデル、解析」という頻出コンポーネントを、よりわかりやすい線形ワークフローとして整理することにある。
このチェーン思考が身につけば、あとで実際のフレームワークの API を見るときに、かなり理解しやすくなります。
この節で持ち帰るべきこと
- LangChain はモデルを置き換えるものではなく、多段アプリケーションを整理するもの
- まずチェーンを理解してからフレームワークを学ぶほうが、API をいきなり覚えるより安定する
- プロトタイプや線形ワークフローには特に向いているが、あらゆる複雑なシステムの最終形ではない
練習
- この
SimpleChainに、query を検索しやすい形に書き換えるステップを 1 つ追加してみてください。 - 自分の言葉で説明してください。なぜ Prompt もチェーンの中の 1 つのコンポーネントとして見られるのでしょうか?
- 考えてみてください。フローに複雑な分岐が入り始めると、なぜチェーン型の抽象化はつらくなるのでしょうか?
- 自分の言葉で説明してください。LangChain はどのような形の問題に最も向いていますか?