8.3.2 大モデル API 呼び出し実践
多くの人は、最初に LLM アプリを作るとき、「とりあえず API を呼べる」ところで止まりがちです。
でも、実際の開発で本当に大切なのは次です。
モデル呼び出しを一回きりの demo ではなく、安定して保守できるアプリ機能にすること。
この節では、最小リクエストから始めて、そのやり方を順番にしっかり説明します。
学習目標
- 最小の LLM API 呼び出しが、どんな要素で成り立つかを理解する
- リクエスト、レスポンス、パラメータ、エラー処理がそれぞれ何を担うかを知る
- 最小だけれど実用的な API クライアントのラップを書けるようになる
- 「API を呼べること」と「アプリを作れること」の間に、まだ大きな差があると分かる
一、なぜ API 呼び出しが LLM アプリ開発の第一歩なのか?
モデルが本当にシステムに入ってくる入口だから
前に学んだ概念は、どれだけ強力でも、最終的にアプリの中では次の 1 つに落ち着きます。
- リクエストを送る
- 結果を受け取る
- その後で処理する
だから API 呼び出しは「基礎の雑務」ではなく、次のものです。
大モデルの能力が製品に入るためのインターフェース層。
よく見落とされるポイント
多くの人が気にするのは次です。
- 返答を取れるかどうか
でも、実際のプロジェクトでは次のほうが重要です。
- 返答は安定しているか
- エラーはどう処理するか
- token コストをどう抑えるか
- 複数ターンのコンテキストをどう組み立てるか
だから、この節の重点は「HTTP リクエストを 1 回送れること」ではなく、「1 回のモデル呼び出しを中心にアプリコードをどう設計するか」です。
二、最小のチャットリクエストには何が含まれるのか?
最も基本的な要素は、通常次の通りです。
- モデル名
- メッセージ一覧
- 温度などのパラメータ
- 返却内容
まずは次のように捉えるとよいです。
タスク説明、コンテキスト、制御パラメータをまとめてモデルに渡す。
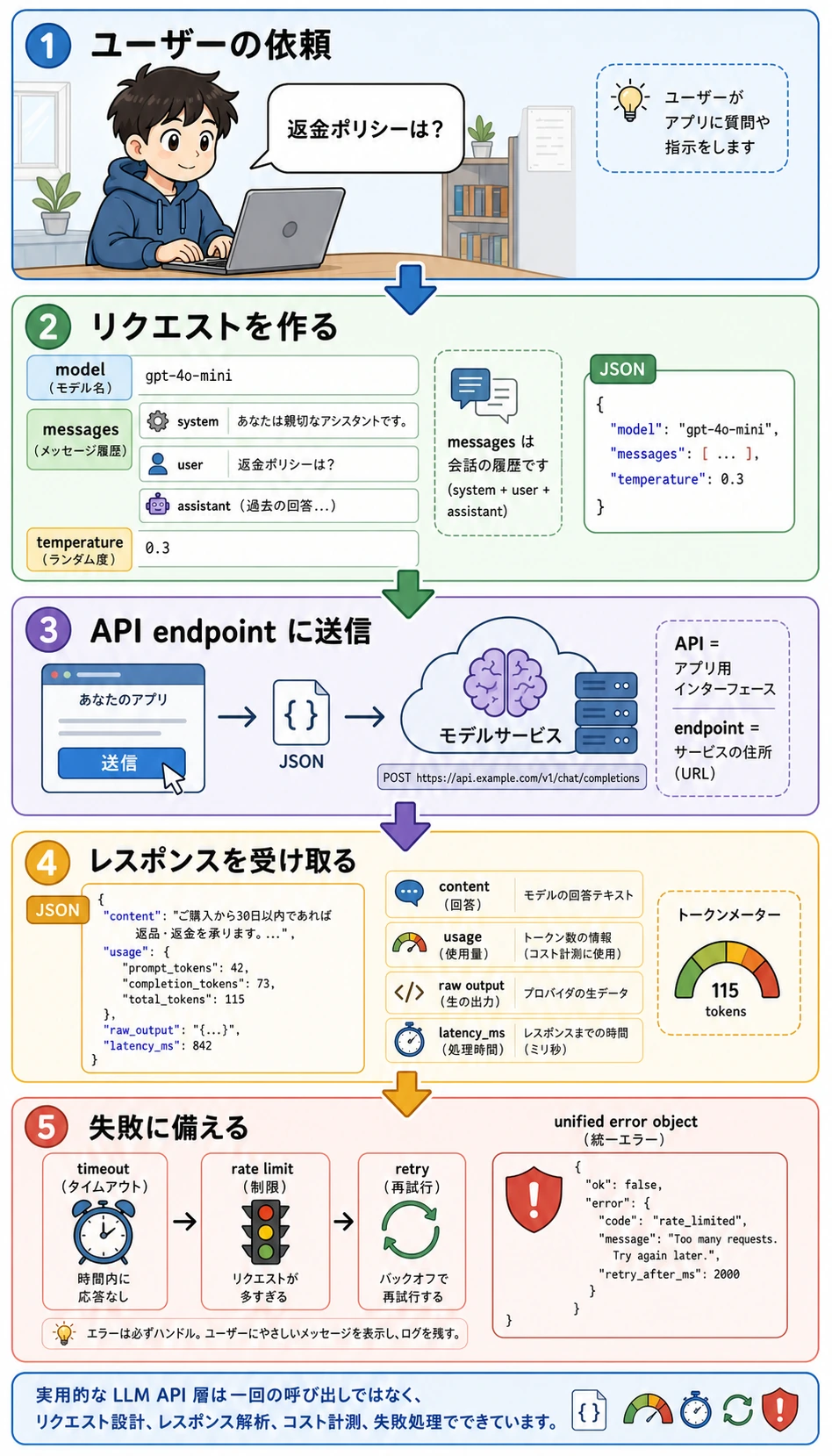
この図は「1 行の呼び出し」ではなく、実行時の閉ループとして読んでください。API はアプリケーション用のインターフェース、endpoint はサービスの住所、JSON はネットワークで送る構造化データ形式、usage は token 使用量を記録して後からコストや性能を分析するための情報です。
最小リクエストのイメージ
request = {
"model": "demo-chat-model",
"messages": [
{"role": "system", "content": "あなたはコースアシスタントです。"},
{"role": "user", "content": "返金ポリシーは何ですか?"}
],
"temperature": 0.2
}
print(request)
期待される出力:
{'model': 'demo-chat-model', 'messages': [{'role': 'system', 'content': 'あなたはコースアシスタントです。'}, {'role': 'user', 'content': '返金ポリシーは何ですか?'}], 'temperature': 0.2}
なぜ messages はリストなのか?
チャットモデルは通常、1 つの文字列だけを見るのではなく、次のものを見ます。
- system の指示
- user の質問
- assistant の過去の返答
こうすることで、複数ターンの会話背景をよりよく理解できます。
三、まずは「オフライン mock クライアント」を作る
コードをそのまま実行できるように、最初は本物のネットワークリクエストを使わず、最小のシミュレーション版 client を書きます。
class MockLLMClient:
def chat(self, messages, model="demo-chat-model", temperature=0.2):
user_message = messages[-1]["content"]
if "返金" in user_message:
reply = "講座購入後 7 日以内かつ学習進捗が 20% 未満であれば、返金申請できます。"
elif "証明書" in user_message:
reply = "すべての必修項目を完了し、修了テストに合格すると、修了証明書を取得できます。"
else:
reply = "これはシミュレーションの返答です。"
return {
"model": model,
"content": reply,
"usage": {
"prompt_tokens": 42,
"completion_tokens": 18
}
}
client = MockLLMClient()
response = client.chat([
{"role": "system", "content": "あなたはコースアシスタントです。"},
{"role": "user", "content": "返金ポリシーは何ですか?"}
])
print(response)
期待される出力:
{'model': 'demo-chat-model', 'content': '講座購入後 7 日以内かつ学習進捗が 20% 未満であれば、返金申請できます。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}
なぜ先に mock 版を作るのか?
それは、次のことを先に理解できるからです。
- 入力構造がどうなっているか
- 出力構造がどうなっているか
- 自分のビジネスロジックをどこに置くべきか
こうすれば、最初からネット接続、認証、SDK の細かい仕様に気を取られずにすみます。
四、「呼べる」から「使える」へ進む
なぜ業務コードのあちこちに直接 API 呼び出しを書いてはいけないのか?
もし毎回あちこちで次のように書くとします。
client.chat(...)
すると、長く使ううちに次の問題が出ます。
- パラメータが統一されない
- system prompt が散らばる
- エラー処理がバラバラになる
- 後でモデルや provider を切り替えにくい
プロジェクトコードらしいラップ
class CourseAssistant:
def __init__(self, llm_client):
self.llm = llm_client
self.system_prompt = "あなたはコースアシスタントです。回答は正確で簡潔にしてください。"
def ask(self, user_query):
messages = [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_query}
]
return self.llm.chat(messages)
assistant = CourseAssistant(MockLLMClient())
print(assistant.ask("証明書はどうやって取得しますか?"))
期待される出力:
{'model': 'demo-chat-model', 'content': 'すべての必修項目を完了し、修了テストに合格すると、修了証明書を取得できます。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}
このラップから何を学ぶのか?
ここで学ぶのは次です。
モデル呼び出しは、より安定したアプリ層のインターフェースの後ろに隠すべきであること。
この考え方はとても重要です。というのも、後から次のものをどんどん足すことになるからです。
- 業務用 prompt
- tool calling
- logging
- retry
五、なぜレスポンスの解析も同じくらい重要なのか?
モデルの出力を受け取っても、通常はそこで終わりではありません。
その後、さらに次の処理をすることが多いです。
- ユーザーに表示する
- データベースに保存する
- ワークフローに流す
- 後処理する
だから、まずはレスポンスを分解して見る習慣をつけるとよいです。
response = assistant.ask("返金ポリシーは何ですか?")
print("reply =", response["content"])
print("usage =", response["usage"])
期待される出力:
reply = 講座購入後 7 日以内かつ学習進捗が 20% 未満であれば、返金申請できます。
usage = {'prompt_tokens': 42, 'completion_tokens': 18}
一見すると単純ですが、これは次のことを教えてくれます。
モデルの返却値は「テキスト」だけではなく、価値のあるメタ情報も含んでいる。
六、一番重要な工程上の問題:エラー処理
実際の呼び出しでよくあるのは、「いつも成功する」ことではなく、次のようなケースです。
- タイムアウト
- レート制限
- ネットワーク異常
- サーバー側エラー
最小のエラー処理例
class UnstableMockLLMClient:
def __init__(self):
self.fail_once = True
def chat(self, messages, model="demo-chat-model", temperature=0.2):
if self.fail_once:
self.fail_once = False
raise RuntimeError("temporary_api_error")
return {
"model": model,
"content": "再試行後に正常に返答できました。",
"usage": {"prompt_tokens": 20, "completion_tokens": 6}
}
def safe_chat(client, messages):
try:
return client.chat(messages)
except Exception as e:
return {"error": str(e)}
client = UnstableMockLLMClient()
messages = [{"role": "user", "content": "こんにちは"}]
print(safe_chat(client, messages))
print(safe_chat(client, messages))
期待される出力:
{'error': 'temporary_api_error'}
{'model': 'demo-chat-model', 'content': '再試行後に正常に返答できました。', 'usage': {'prompt_tokens': 20, 'completion_tokens': 6}}
なぜこの層を丁寧に作る必要があるのか?
モデル呼び出しがシステムの中間に入ると、エラーは単に「ユーザーに返事が来ない」だけでは済みません。次のような影響があります。
- その後のワークフローが全部止まる
- ログや集計がずれる
- ユーザー体験が急に悪くなる
七、より実践的な再試行の例
def retry_chat(client, messages, retries=2):
last_error = None
for _ in range(retries + 1):
try:
return client.chat(messages)
except Exception as e:
last_error = str(e)
return {"error": last_error}
client = UnstableMockLLMClient()
print(retry_chat(client, [{"role": "user", "content": "こんにちは"}]))
期待される出力:
{'model': 'demo-chat-model', 'content': '再試行後に正常に返答できました。', 'usage': {'prompt_tokens': 20, 'completion_tokens': 6}}
この例が教えているのは次です。
API 呼び出しがシステムに入ったら、retry は付加機能ではなく、基本能力になる。
八、本番プロジェクトでは何をさらに追加するのか?
mock から本物の API に進むとき、普通は次も追加します。
- 認証
- モデル切り替え
- token コストの集計
- ログと trace
- timeout
- provider 互換層
つまり、本番の LLM API 層は、次の 2 つの顔を持つことが多いです。
- モデルの入口
そして
- 実行時の中間層
九、よくある誤解
「content が取れれば十分」と思ってしまう
実際には、usage、エラー構造、trace 情報もとても大切です。
業務コードのあちこちに client.chat(...) が散らばる
こうなると、後で保守するのがとても大変になります。
統一したエラー処理がない
本番で問題が起きたとき、すぐに表面化しやすくなります。
LLM API の最小エンジニアリング規範
API 呼び出しを本番プロジェクトに組み込むときは、次の表で自分のラップが十分安定しているか確認できます。
| チェック項目 | 最低要件 | 重要な理由 |
|---|---|---|
| 設定管理 | API key、model、base_url を業務関数に直書きしない | 環境切り替えと秘密情報保護がしやすい |
| 統一入口 | すべてのモデル呼び出しを同じ client か service 経由にする | logging、retry、レート制限、コスト集計を追加しやすい |
| timeout 設定 | 各リクエストに timeout を入れる | 1 回のリクエストで全体が止まるのを防ぐ |
| retry 方針 | 一時的エラーだけを最大回数付きで再試行する | 無限 retry とコスト暴走を防ぐ |
| エラー構造 | 失敗時は統一した error オブジェクトを返す | 上位ロジックが安定して失敗処理できる |
| usage 記録 | token、モデル名、所要時間を記録する | 後でコストと性能を分析できる |
| 生出力の保存 | raw output か重要な trace を保存する | 問題発生時にモデルの返答を追跡できる |
この表のポイントは、API 層を「安定したインターフェース」にすることです。コードのあちこちに散らばった複数回のモデル呼び出しにしてはいけません。後で学ぶ RAG、構造化出力、Function Calling、Agent はすべてこの層に依存します。
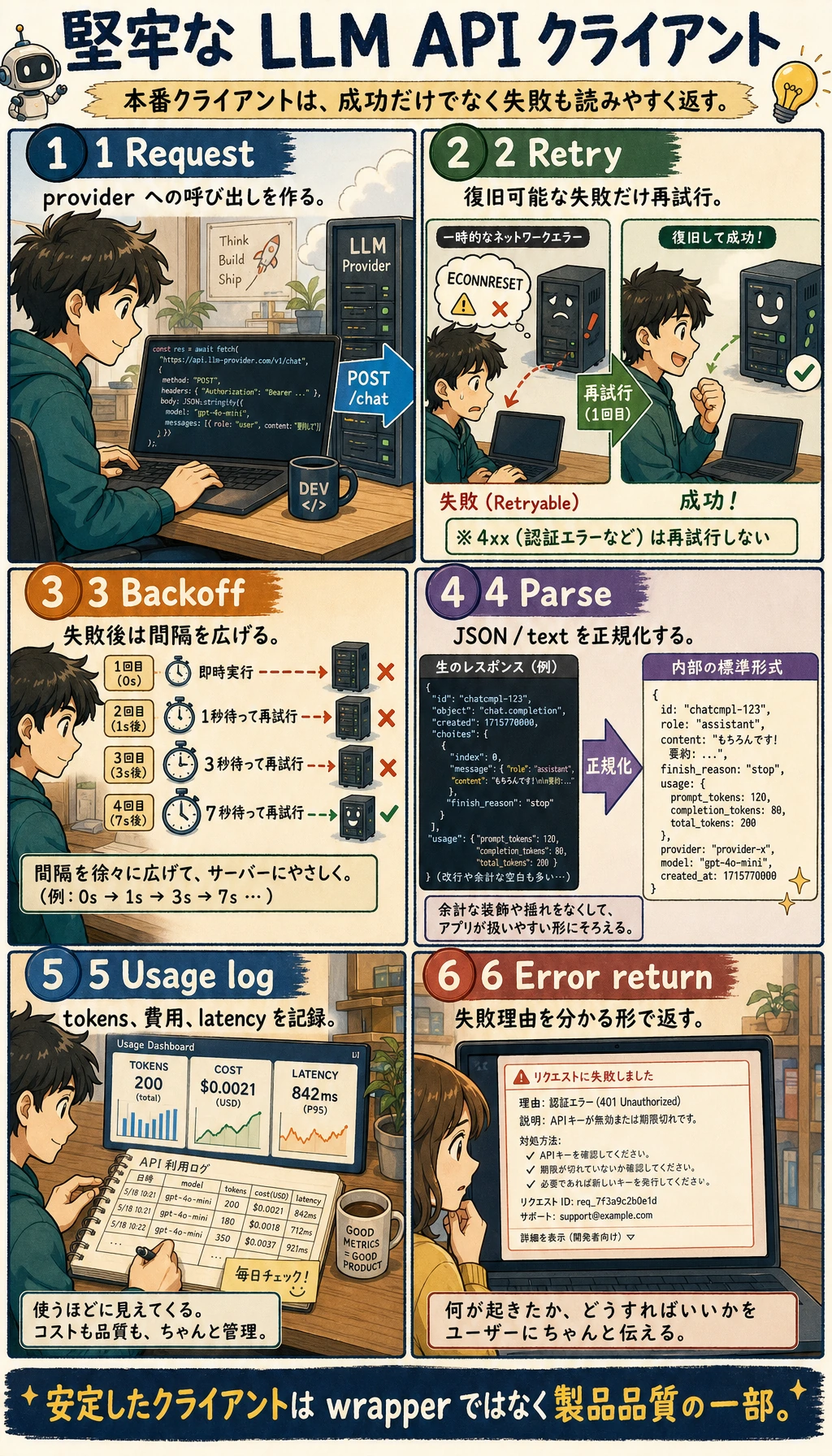
1 回のモデル呼び出しがプロジェクトに入ると、もはや client.chat() だけではありません。図では、設定、timeout、retry、統一レスポンス、usage、ログ、raw output を同じ輪にまとめています。API 層をまず安定したランタイムにする必要があることを思い出してください。
より本番に近いレスポンス構造
最初から、モデル呼び出しは統一された構造を返すようにしておくのがおすすめです。文字列だけ返したり、辞書だったり、例外を投げたりが混ざらないようにしましょう。
import time
def llm_response(ok, content=None, usage=None, error=None, raw=None, latency_ms=0):
return {
"ok": ok,
"content": content,
"usage": usage or {},
"error": error,
"raw": raw,
"latency_ms": latency_ms,
}
def robust_chat(client, messages):
start = time.time()
try:
raw = client.chat(messages)
latency_ms = int((time.time() - start) * 1000)
return llm_response(
ok=True,
content=raw.get("content"),
usage=raw.get("usage"),
raw=raw,
latency_ms=latency_ms,
)
except Exception as e:
latency_ms = int((time.time() - start) * 1000)
return llm_response(ok=False, error=str(e), latency_ms=latency_ms)
print(robust_chat(MockLLMClient(), [{"role": "user", "content": "返金ポリシーは何ですか?"}]))
出力例:
{'ok': True, 'content': '講座購入後 7 日以内かつ学習進捗が 20% 未満であれば、返金申請できます。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}, 'error': None, 'raw': {'model': 'demo-chat-model', 'content': '講座購入後 7 日以内かつ学習進捗が 20% 未満であれば、返金申請できます。', 'usage': {'prompt_tokens': 42, 'completion_tokens': 18}}, 'latency_ms': 0}
この mock 例では実際のネットワーク呼び出しがないため、latency_ms は 0 になることがあります。本物の API では、まず見るべき信号の 1 つになります。
このラップがあると、上位の業務コードは次の判断をしやすくなります。呼び出しは成功したか、内容はどこか、token はどれくらい使ったか、失敗理由は何か、リクエストにどれくらい時間がかかったか、です。
API 呼び出しログには何を記録すべきか
LLM アプリで問題が起きたとき、ログがないと、たいてい推測するしかありません。少なくとも次の項目は記録するのがおすすめです。
| 項目 | 例 | 用途 |
|---|---|---|
request_id | req_001 | 1 回の呼び出しの文脈をつなぐ |
model | demo-chat-model | モデルごとの違いを比べる |
prompt_version | course_assistant_v1 | どの版の prompt で問題が起きたか追う |
input_preview | 返金ポリシーは何ですか | ユーザー入力をすばやく特定する |
output_preview | 講座購入後 7 日以内... | モデル出力をすばやく確認する |
prompt_tokens | 42 | コスト分析 |
completion_tokens | 18 | コスト分析 |
latency_ms | 850 | 性能分析 |
error | timeout | 失敗原因の特定 |
注意: ログには敏感情報をそのまま保存しないでください。実際のプロジェクトでは、ユーザーの個人情報、キー、社内資料はマスキングするか、権限管理を行うべきです。
まとめ
この節で最も大事なのは、「1 回モデルを呼べること」そのものではありません。理解すべきなのは次です。
大モデル API 呼び出しの本当のエンジニアリング価値は、モデル能力を繰り返し使えて、保守しやすく、拡張できるシステムインターフェースにすることにある。
この視点ができると、次に LangChain、対話システム、Agent のツール層を学ぶときも、ずっと自然に理解できるようになります。
練習
MockLLMClientを拡張して、「学習順序」の質問にも答えられるようにしてみましょう。CourseAssistantに統一されたエラー返却構造を追加してください。- 考えてみましょう: なぜ本番プロジェクトでは、業務コードのあちこちで
messagesを直接組み立てるべきではないのでしょうか? - 自分の言葉で説明してみましょう: なぜ「API を呼べること」と「LLM アプリを作れること」の間には、まだ 1 層のシステム設計が必要なのでしょうか?