8.3.7 大模型辅助编程
AI 辅助编程不是“让模型替你写完所有代码”,而是把模型放进开发流程:帮你理解代码、生成草稿、补测试、查 bug、做重构建议。真正重要的是你如何验证它。
学习目标
- 知道大模型适合辅助哪些编程任务
- 能写出更清晰的代码生成和调试 Prompt
- 理解为什么测试、diff 和代码审查仍然必不可少
- 能把 AI 编程过程记录进项目 README 或开发日志
AI 辅助编程适合做什么
大模型擅长生成样板代码、解释陌生 API、改写函数、生成测试用例、总结错误日志和提出重构方向。它不擅长保证代码一定正确,也不一定理解你的项目上下文、隐含约束和线上风险。
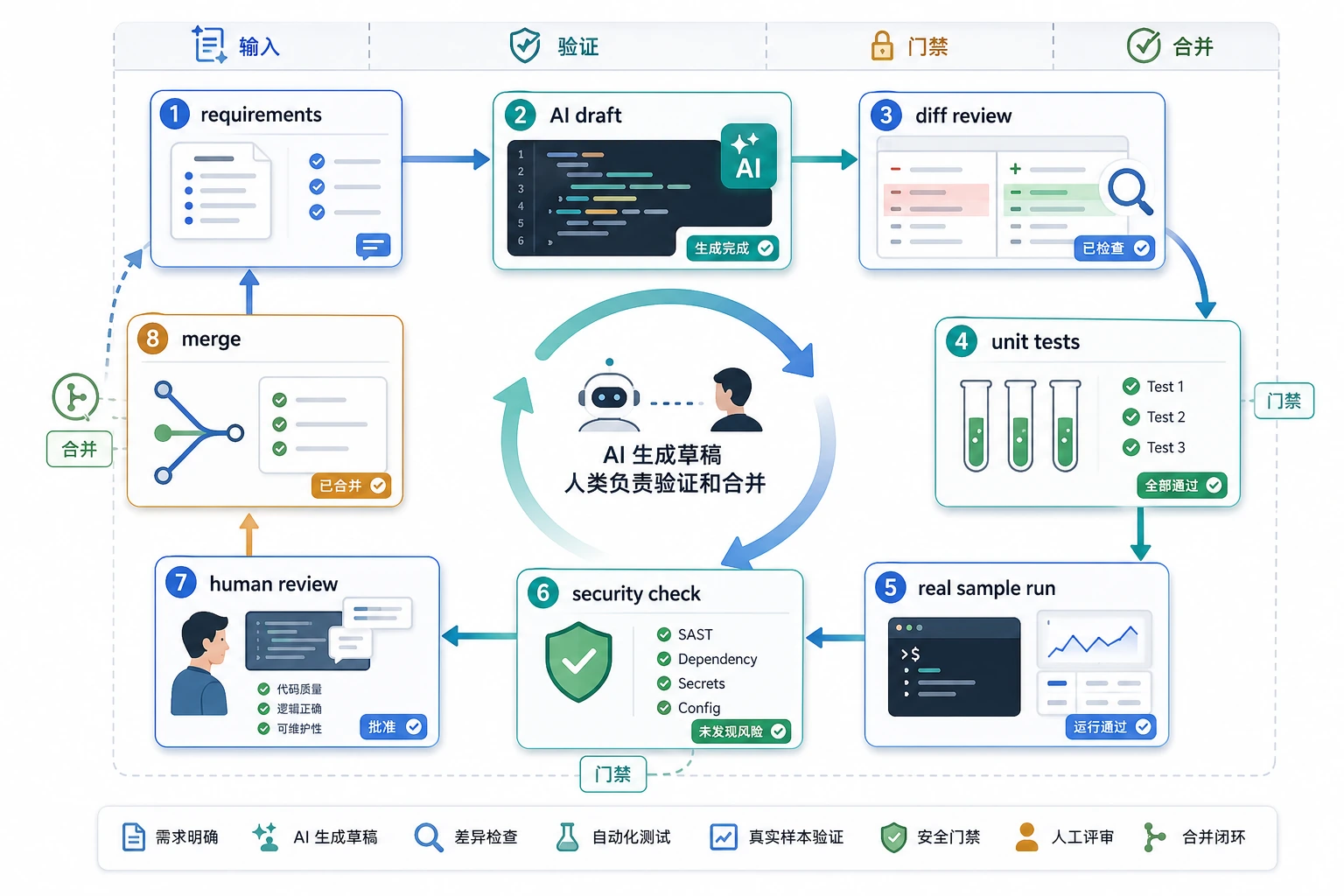
把模型当“草稿生成器”,不是当“最终合并者”。一段 AI 代码至少要经过需求约束、diff、测试、真实样例和人工审查这几关,才适合进入项目。
写代码前先让模型复述约束
比起直接说“帮我写一个 RAG 系统”,更好的方式是给出输入、输出、依赖、边界和验收标准。
请写一个 Python 函数,输入 Markdown 文本,输出按标题切分后的 chunk 列表。
要求:
1. 保留标题层级;
2. 每个 chunk 不超过 800 字;
3. 不使用外部库;
4. 给出 3 个测试用例。
这种 Prompt 会比模糊需求稳定得多,因为模型知道什么算完成。
生成代码后必须验证
AI 生成代码后,至少做三件事:读 diff、跑测试、跑一个真实样例。不要因为代码看起来像对的就直接合并。
python -m pytest
python demo.py
如果项目没有测试,可以先让模型补最小测试。测试应该覆盖正常输入、边界输入和错误输入。
动手做:验证 AI 生成的 Markdown 切分器
下面这个脚本是一个完整可运行的小流程:先给模型约束,让它生成草稿,再用测试验证草稿。把它保存成 ai_chunker_demo.py,然后运行 python ai_chunker_demo.py。
import unittest
def split_markdown_by_heading(markdown, max_chars=800):
chunks = []
current = []
def flush():
if not current:
return
text = "\n".join(current).strip()
if not text:
return
if len(text) > max_chars:
raise ValueError("chunk_too_large")
chunks.append(text)
for line in markdown.splitlines():
if line.startswith("#") and current:
flush()
current = [line]
else:
current.append(line)
flush()
return chunks
class SplitMarkdownTests(unittest.TestCase):
def test_raises_when_chunk_too_large(self):
with self.assertRaises(ValueError):
split_markdown_by_heading("# 标题\n" + "a" * 20, max_chars=10)
def test_preserves_headings(self):
chunks = split_markdown_by_heading("# 退款\n政策正文")
self.assertEqual(chunks[0], "# 退款\n政策正文")
def test_splits_by_headings(self):
text = "# 退款\n政策正文\n## 细节\n更多内容"
chunks = split_markdown_by_heading(text)
self.assertEqual(len(chunks), 2)
self.assertTrue(chunks[1].startswith("## 细节"))
if __name__ == "__main__":
unittest.main(verbosity=2)
预期输出:
test_preserves_headings (__main__.SplitMarkdownTests.test_preserves_headings) ... ok
test_raises_when_chunk_too_large (__main__.SplitMarkdownTests.test_raises_when_chunk_too_large) ... ok
test_splits_by_headings (__main__.SplitMarkdownTests.test_splits_by_headings) ... ok
----------------------------------------------------------------------
Ran 3 tests in ...
OK

你要建立的是这个习惯:模型可以生成函数草稿,但测试负责定义草稿是否合格。真实项目里,每发现一个 bug 或漏掉的需求,就补一个测试。
调试时提供完整上下文
调试 Prompt 最好包含:错误日志、相关代码、你期望的行为、实际行为、你已经尝试过什么。只贴一句报错,模型往往只能猜。
下面是报错、函数代码和测试输入。请先判断最可能原因,再给出最小修改,不要重写整个文件。
要求“最小修改”很重要,它能避免模型把原本清晰的代码改成另一套风格。
AI 代码审查清单
| 检查项 | 问题 |
|---|---|
| 正确性 | 是否覆盖需求和边界条件 |
| 安全性 | 是否处理路径、权限、密钥和外部输入 |
| 可维护性 | 命名、结构、重复代码是否合理 |
| 依赖 | 是否引入不必要的新库 |
| 测试 | 是否有可运行测试证明行为 |
适合记录进作品集的内容
如果你在项目中使用 AI 辅助编程,可以记录:你给模型的关键 Prompt、模型第一次输出的问题、你如何测试和修正、最终代码和初版有什么差异。这比只说“我用了 AI”更能体现工程能力。
常见误区
第一个误区是把 AI 输出当成权威答案。第二个误区是不提供项目上下文,导致模型生成和现有架构不兼容的代码。第三个误区是不看 diff,只要能跑就接受。第四个误区是让模型一次改太多文件,导致很难定位问题。
练习
- 让模型为一个已有函数生成 3 个 pytest 测试,再人工检查是否覆盖边界。
- 给模型一段报错日志,要求它只做最小修改。
- 比较“模糊 Prompt”和“带验收标准 Prompt”的代码质量差异。
- 写一段 README,说明你如何使用 AI 辅助完成项目但仍然做了验证。
过关标准
学完本节后,你应该能把 AI 当成开发助手而不是替代开发者,能写出带约束和验收标准的编程 Prompt,能通过测试和代码审查验证输出,并能把 AI 协作过程沉淀成可复盘的工程记录。