8.3.9 模板化文档生成(Word / PPT)
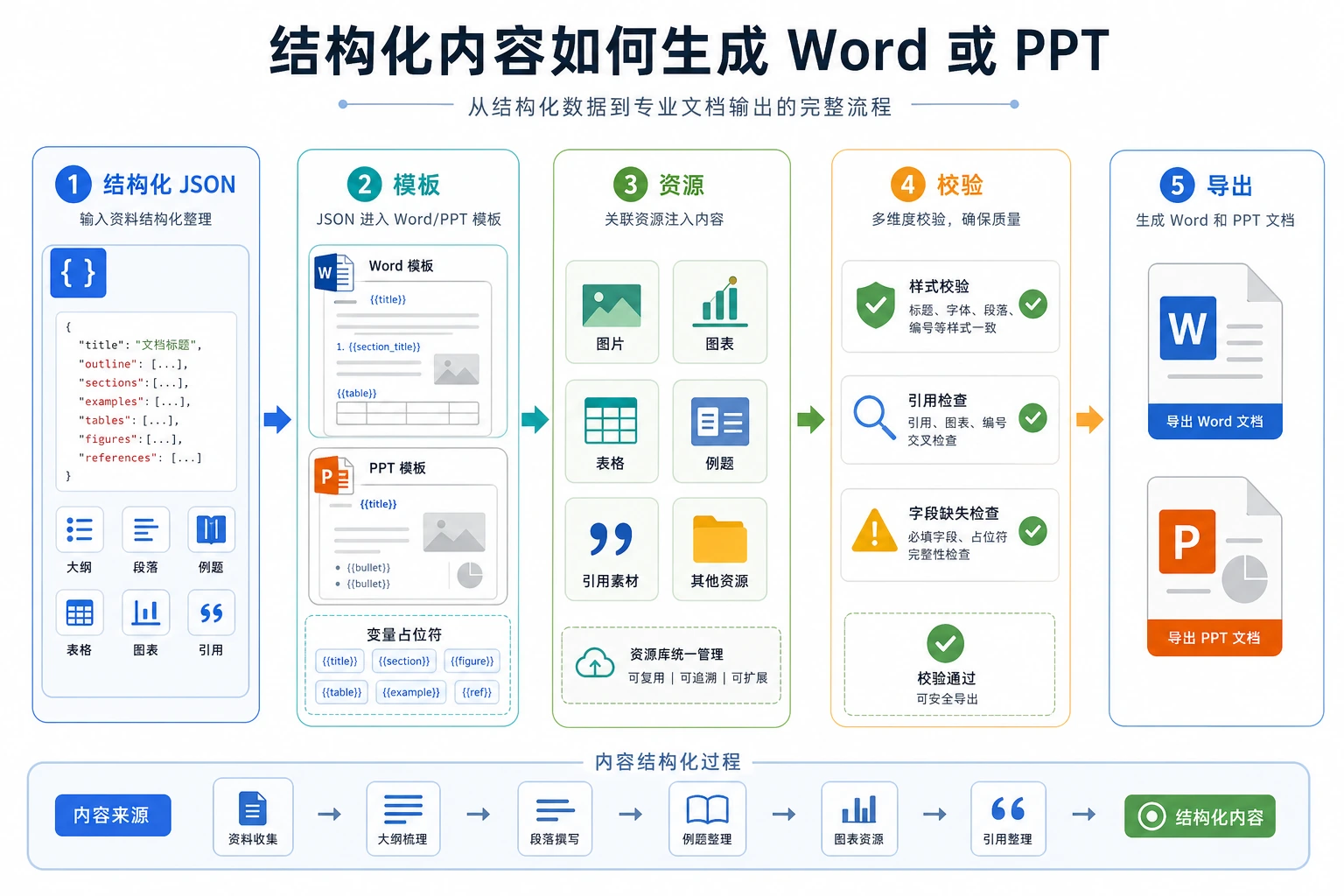
很多新人做“生成 Word / 课件”时,最容易直接让模型输出一大段正文, 然后希望它天然就符合:
- 章节顺序
- 格式要求
- 例题位置
- 课件风格
这通常不稳。
更稳的做法通常是:
先让模型产出结构化内容,再把结构填进模板。
学习目标
- 理解为什么文档生成最好走“结构 -> 模板 -> 导出”路线
- 理解 Word / PPT 生成和普通聊天输出的差别
- 看懂一个最小模板填充流程
- 建立“结构化输出先于文档排版”的工程直觉
先建立一张地图
模板化文档生成更适合按“主题 -> 大纲 -> 内容块 -> 模板导出”来理解:
所以这节真正想解决的是:
- 为什么不要让模型直接“自由写一整份 Word”
- 为什么固定模板会让生成结果更稳
为什么模板化这么重要?
因为你的目标不是普通问答, 而是要交付:
- 像课件的文档
这意味着系统不只要回答对, 还要满足:
- 结构稳定
- 栏目固定
- 标题级别固定
- 例题和总结位置合理
一个更适合新人的总类比
你可以把文档生成理解成:
- 先写提纲,再填内容,最后排版
如果一上来直接写整篇正文, 很容易发生:
- 结构乱
- 内容重复
- 例题跑到不该去的位置
所以更稳的方式通常是:
- 先定骨架
- 再填血肉
一个最小结构化课件对象示例
courseware = {
"title": "折扣应用题讲解",
"target_audience": "小学高年级",
"sections": [
{
"heading": "一、知识点回顾",
"content_type": "concept",
"items": ["折扣 = 原价 × 折扣率"],
},
{
"heading": "二、例题讲解",
"content_type": "example",
"items": ["商品原价 100 元,打 8 折后价格是多少?"],
},
{
"heading": "三、课堂练习",
"content_type": "exercise",
"items": ["一件衣服原价 80 元,打 7 折后是多少元?"],
},
],
}
print(courseware)
预期输出:
{'title': '折扣应用题讲解', 'target_audience': '小学高年级', 'sections': [{'heading': '一、知识点回顾', 'content_type': 'concept', 'items': ['折扣 = 原价 × 折扣率']}, {'heading': '二、例题讲解', 'content_type': 'example', 'items': ['商品原价 100 元,打 8 折后价格是多少?']}, {'heading': '三、课堂练习', 'content_type': 'exercise', 'items': ['一件衣服原价 80 元,打 7 折后是多少元?']}]}
这个例子最重要的价值是:
- 先把“要生成什么结构”说清楚
也就是说,模型不应该直接输出最终 .docx,
而应该先输出一份结构化内容对象。
一个更适合真实项目的课件 schema
如果你的目标是“生成符合固定格式的 Word 课件”, 建议在最小对象上再多补两层:
- 页面级或章节级顺序
- 模板字段级映射
一个更稳的课件 schema 往往至少包含:
| 字段 | 用途 |
|---|---|
title | 文档标题 |
audience | 适用对象 |
teaching_goal | 教学目标 |
sections | 正文结构 |
source_refs | 引用来源 |
template_version | 用的是哪个模板 |
这张表特别适合新人,因为它会提醒你:
- 你不是在生成“长文本”
- 你是在生成“可被模板稳定消费的数据对象”
一个最小模板填充示例
下面这个例子不用真实 python-docx,
先用最简单的字符串模板讲清楚工作流。
template = """# {title}
适用对象:{target_audience}
{body}
"""
def render_body(sections):
blocks = []
for section in sections:
blocks.append(section["heading"])
for item in section["items"]:
blocks.append(f"- {item}")
blocks.append("")
return "\n".join(blocks)
result = template.format(
title=courseware["title"],
target_audience=courseware["target_audience"],
body=render_body(courseware["sections"]),
)
print(result)
预期输出:
# 折扣应用题讲解
适用对象:小学高年级
一、知识点回顾
- 折扣 = 原价 × 折扣率
二、例题讲解
- 商品原价 100 元,打 8 折后价格是多少?
三、课堂练习
- 一件衣服原价 80 元,打 7 折后是多少元?
这个例子特别适合初学者,因为它会帮助你先看到:
- 模板化的核心不是库
- 而是“先有结构,再套模板”
模板字段应该怎么设计?
第一次做这类系统时,特别推荐先把模板字段明写出来。
| 模板字段 | 对应内容 |
|---|---|
{title} | 课件标题 |
{target_audience} | 适用对象 |
{teaching_goal} | 教学目标 |
{concept_block} | 知识点回顾 |
{example_block} | 例题讲解 |
{exercise_block} | 课堂练习 |
{source_block} | 来源说明 |
它的好处是:
- 模型知道自己要产什么
- 模板渲染层知道自己要填什么
- 你后面改版时也知道是哪一层出了问题
Word / PPT 真正要额外处理什么?
在真实工程里,除了正文内容,你还会处理:
- 标题样式
- 段落层级
- 编号
- 表格
- 图片位置槽
- 页眉页脚
- 幻灯片页布局
所以模板化文档生成其实是两层问题:
- 内容结构
- 文档排版
一个最小“结构对象 -> 模板字段”示例
def to_template_payload(courseware):
blocks = {"concept": [], "example": [], "exercise": []}
for section in courseware["sections"]:
blocks[section["content_type"]].extend(section["items"])
return {
"title": courseware["title"],
"target_audience": courseware["target_audience"],
"teaching_goal": "理解折扣的基本计算方法",
"concept_block": "\n".join(f"- {x}" for x in blocks["concept"]),
"example_block": "\n".join(f"- {x}" for x in blocks["example"]),
"exercise_block": "\n".join(f"- {x}" for x in blocks["exercise"]),
"source_block": "来源:内部知识库 + 外部资料补充",
}
payload = to_template_payload(courseware)
print(payload)
预期输出:
{'title': '折扣应用题讲解', 'target_audience': '小学高年级', 'teaching_goal': '理解折扣的基本计算方法', 'concept_block': '- 折扣 = 原价 × 折扣率', 'example_block': '- 商品原价 100 元,打 8 折后价格是多少?', 'exercise_block': '- 一件衣服原价 80 元,打 7 折后是多少元?', 'source_block': '来源:内部知识库 + 外部资料补充'}
这个小例子最值得新人注意的是:
- 结构对象不一定等于模板对象
- 中间往往还会有一层“字段整理”
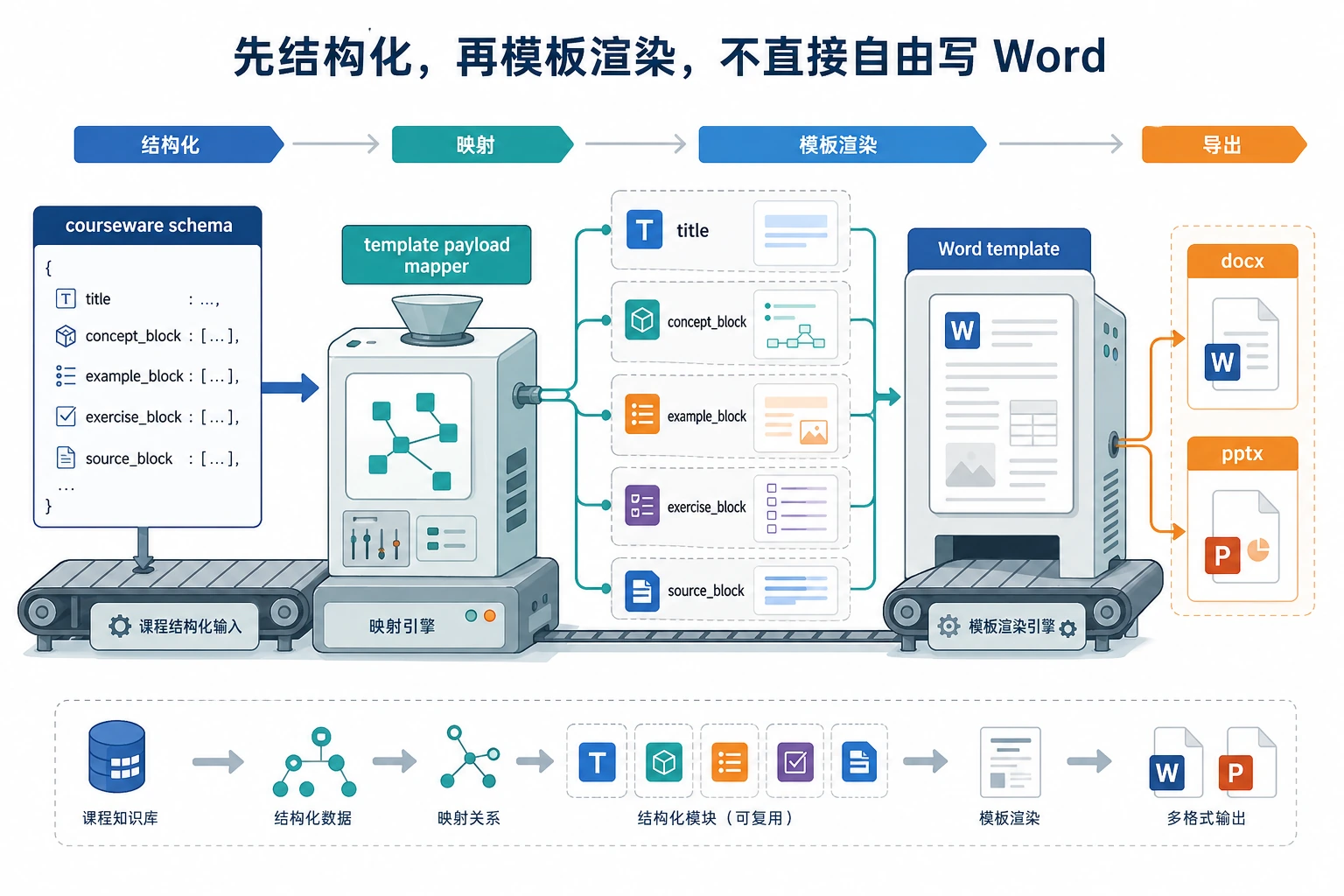
不要让模型直接“写 Word”。先产出 courseware schema,再整理成 template payload,最后交给 docx/pptx 渲染层。这样格式错误和内容错误才容易分开排查。
动手做:渲染前先校验模板字段
在把数据交给 python-docx、docxtpl 或 python-pptx 之前,先检查 template payload 是否包含所有必填字段。这样可以避免导出后才发现 Word 文档有一半是空的。
REQUIRED_FIELDS = [
"title",
"target_audience",
"teaching_goal",
"concept_block",
"example_block",
"exercise_block",
"source_block",
]
def validate_payload(payload):
missing = [field for field in REQUIRED_FIELDS if not payload.get(field)]
if missing:
return False, f"缺少字段:{missing}"
return True, "ok"
def render_markdown_handout(payload):
ok, message = validate_payload(payload)
if not ok:
raise ValueError(message)
return f"""# {payload['title']}
适用对象:{payload['target_audience']}
教学目标:{payload['teaching_goal']}
## 知识点回顾
{payload['concept_block']}
## 例题讲解
{payload['example_block']}
## 课堂练习
{payload['exercise_block']}
## 来源说明
{payload['source_block']}
"""
payload = {
"title": "折扣应用题讲解",
"target_audience": "小学高年级",
"teaching_goal": "理解折扣的基本计算方法",
"concept_block": "- 折扣 = 原价 × 折扣率",
"example_block": "- 商品原价 100 元,打 8 折后价格是多少?",
"exercise_block": "- 一件衣服原价 80 元,打 7 折后是多少元?",
"source_block": "来源:内部知识库 + 外部资料补充",
}
print(validate_payload(payload))
print(render_markdown_handout(payload))
预期输出:
(True, 'ok')
# 折扣应用题讲解
适用对象:小学高年级
教学目标:理解折扣的基本计算方法
## 知识点回顾
- 折扣 = 原价 × 折扣率
## 例题讲解
- 商品原价 100 元,打 8 折后价格是多少?
## 课堂练习
- 一件衣服原价 80 元,打 7 折后是多少元?
## 来源说明
来源:内部知识库 + 外部资料补充
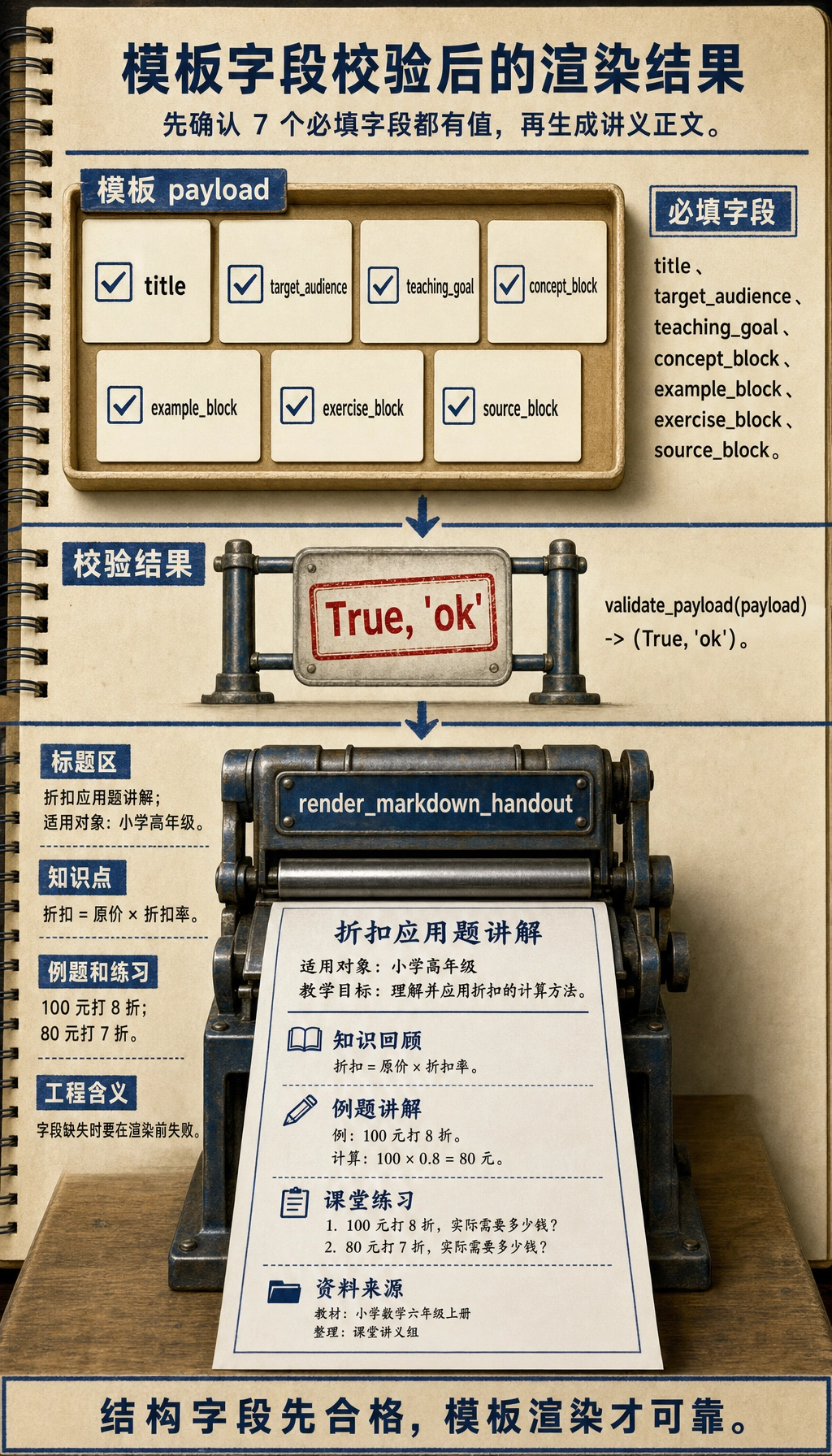
这个检查很简单,但它体现了 demo 和工程管线的区别:每个渲染步骤都应该在缺少必填结构字段时尽早失败。
为什么这一层和 Prompt / 结构化输出强相关?
因为你通常会让模型先产出:
- JSON
- 大纲
- 标题列表
- 每节的知识点 / 例题 / 练习
而不是直接产出一份“自由散文式”长文档。
这部分最相关的已有课程是:
第一次做这个模块时,最稳的范围控制
第一次做时,最稳的范围通常是:
- 先只生成
Word - 先只支持一种模板
- 先不加图片自动布局
- 先不做复杂样式切换
这样更容易先证明:
- 结构对象稳定
- 模板字段稳定
- 导出链路稳定
一个新人可直接照抄的生成顺序
第一次做这种系统时,更稳的顺序通常是:
- 先定义课件结构
- 先生成结构化 JSON / 大纲
- 再填知识点和例题
- 最后再导出 Word / PPT
这样会比一上来直接生成 .docx 内容稳定很多。
实际工程里会用到哪些库?
这部分当前课程里还没有展开到具体库使用层, 但你做项目时大概率会接触:
python-docxdocxtplpython-pptx
所以这节可以看成是:
- 先把思路讲顺
- 具体库再去查官方文档
如果把它做成项目,最值得展示什么?
最值得展示的通常不是:
- “我们能导出 Word”
而是:
- 结构化内容对象长什么样
- 模板长什么样
- 最终 Word / PPT 和结构之间是怎么对应的
- 哪些格式要求是稳定可控的
这样别人会更容易看出:
- 你理解的是模板化生成
- 不只是“让模型写长文”
小结
- 模板化文档生成最关键的是先定义稳定 schema,再定义模板字段
- “结构对象 -> 字段整理 -> 模板渲染” 这三层分开后,系统会稳很多
- 第一次做时,先把单模板 Word 导出跑顺,比同时做 Word 和 PPT 更稳
这节最该带走什么
- 文档生成最稳的路线通常是“结构化输出 -> 模板渲染 -> 文档导出”
- 先定结构,再填内容,比直接让模型自由写整份课件稳得多
- 如果你的目标是生成 Word / 课件,这一层是项目成败的关键环节