8.3.6 对话系统与多轮管理
很多人一做聊天应用,第一反应是:
- 维护一个
history - 把历史一起塞给模型
这能做出最基础 demo,但离一个真正可用的对话系统还有很远。
这一节的重点,就是把“多轮对话”这件事拆清楚。
学习目标
- 理解单轮问答和多轮对话系统的核心区别
- 理解会话状态、上下文窗口、澄清问题这些基本概念
- 看懂一个最小多轮对话管理器
- 明白为什么对话系统的关键不只是记历史,而是管状态
先建立一张地图
多轮对话这节最适合新人的理解顺序不是“把历史都塞进去”,而是先看清:
所以这节真正想解决的是:
- 多轮系统为什么比单轮问答难
- “有历史”为什么不等于“有状态”
一个更适合新人的总类比
你可以把多轮对话系统想成:
- 一个客服在和用户持续聊天
用户不会每一轮都把背景重新讲一遍。 所以客服必须记住:
- 现在聊的主题是什么
- 哪些关键信息已经知道
- 哪些信息还缺
如果只把聊天记录全堆在旁边,但没有真正整理状态, 这个客服还是会很容易答乱。
为什么多轮对话比单轮问答难得多?
单轮问答更像“一问一答”
例如:
- 用户问一句
- 系统回一句
这类系统即使没有长期状态,也能工作。
多轮对话真正难在哪?
因为后续轮次经常会省略信息:
- “退款政策是什么?”
- “那我已经学了 30% 还能退吗?”
第二句里的“那我”其实默认继承了第一轮主题。 如果系统不记得前文,就会理解不完整。
所以多轮对话真正难的地方不是“消息变多了”,而是:
上下文依赖和状态延续。
一个对话系统通常至少要管什么?
最少通常要管:
- 会话历史
- 当前主题
- 用户澄清信息
- 是否需要追问
也就是说,对话系统不仅要“生成回答”,还要管理:
这段对话现在处于什么状态。
一个最小对话管理器示例
def new_session():
return {
"history": [],
"topic": None
}
def add_turn(session, role, content):
session["history"].append({"role": role, "content": content})
session = new_session()
add_turn(session, "user", "退款政策是什么?")
add_turn(session, "assistant", "你是想看时间范围,还是资格条件?")
print(session)
预期输出:
{'history': [{'role': 'user', 'content': '退款政策是什么?'}, {'role': 'assistant', 'content': '你是想看时间范围,还是资格条件?'}], 'topic': None}
这段代码虽然很小,但它已经在教什么?
它在教你:
- 对话系统天然就有状态
- 状态至少包括历史和当前主题
这就是从“单次调用模型”走向“对话系统”的第一步。
再看一个最小“状态流”示例
state = {
"topic": "refund",
"slots": {"progress": None},
}
user_message = "我已经学了 30% 还能退吗?"
if "30%" in user_message:
state["slots"]["progress"] = "30%"
print(state)
预期输出:
{'topic': 'refund', 'slots': {'progress': '30%'}}
这个示例很适合初学者,因为它会帮助你看到:
- 对话系统真正要保留的,不只是原话
- 还包括结构化的状态
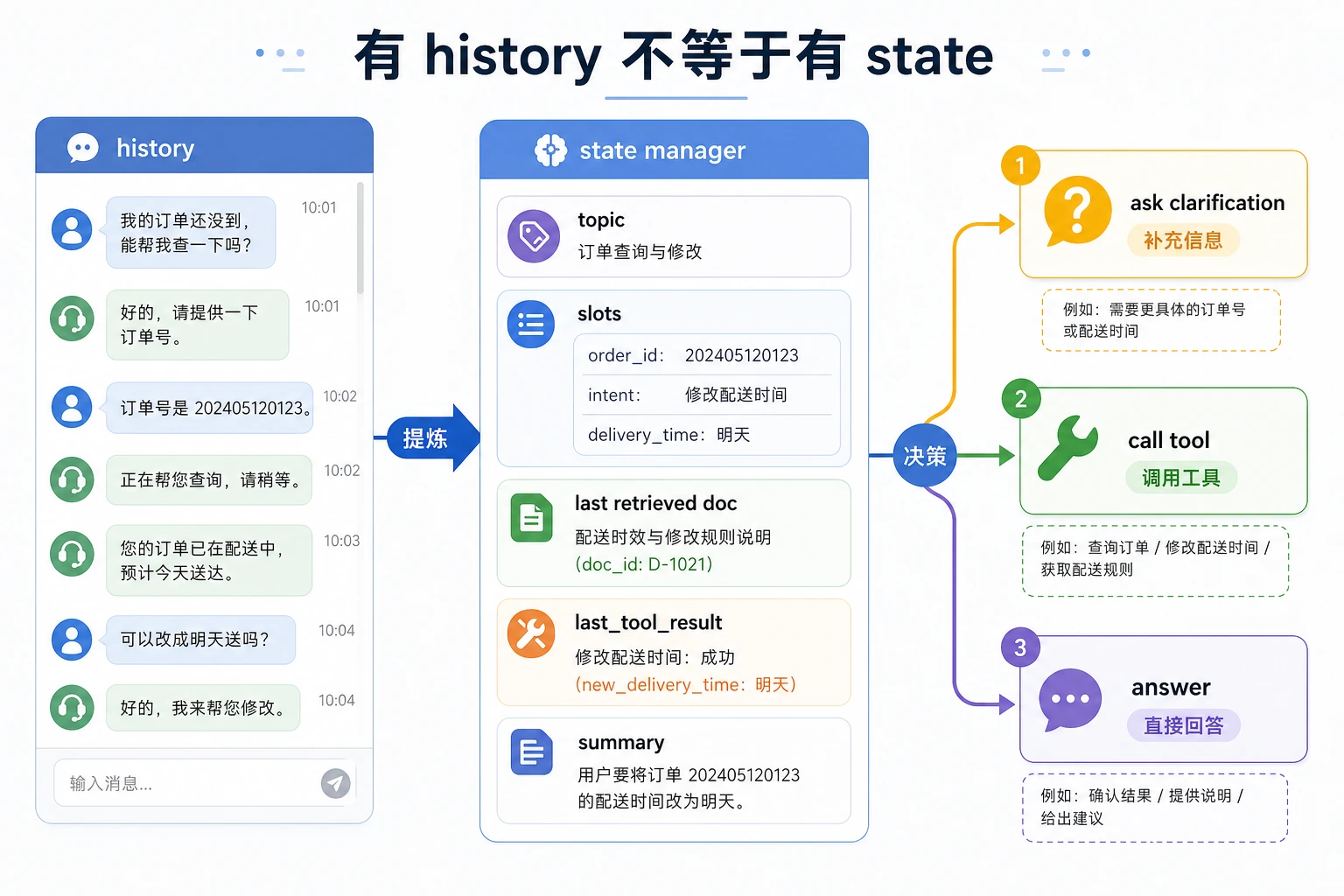
历史记录是原始材料,state 才是系统正在维护的“当前理解”。图里把 topic、slots、last_tool_result 和 summary 分开,是为了避免把所有上下文都粗暴塞进 prompt。
对话系统不是只会回答,还要会追问
为什么追问能力很关键?
因为用户输入很多时候是不完整的。
例如:
- “帮我查天气”
这时系统如果直接瞎猜城市,体验通常会变差。 更合理的做法是:
先补齐缺失信息。
一个最小追问示例
def dialog_step(session, user_message):
add_turn(session, "user", user_message)
if "天气" in user_message and "北京" not in user_message and "上海" not in user_message:
reply = "你想查哪个城市的天气?"
add_turn(session, "assistant", reply)
return reply
reply = f"系统正在处理:{user_message}"
add_turn(session, "assistant", reply)
return reply
session = new_session()
print(dialog_step(session, "帮我查天气"))
print(session["history"])
预期输出:
你想查哪个城市的天气?
[{'role': 'user', 'content': '帮我查天气'}, {'role': 'assistant', 'content': '你想查哪个城市的天气?'}]
这已经体现出一个很关键的能力:
对话系统不只是答,还要能管理信息缺口。
为什么追问其实是一种“系统更稳”的表现?
很多新人会误以为:
- 系统越少追问越聪明
但真实产品里,很多时候恰恰相反:
- 先追问把条件补齐
- 往往比直接乱猜更可靠
为什么“只把全部历史塞给模型”不够?
历史太长会带来什么?
- token 成本上升
- 响应变慢
- 无关信息越来越多
所以真实系统通常会做选择
例如:
- 只保留最近 N 轮
- 当前主题单独存状态
- 更早历史做摘要
也就是说,多轮管理不只是“有历史”,而是:
怎样保留有用历史。
动手做:保留近期轮次,压缩旧历史
下面这个小练习模拟一个真实系统常见做法:最近几轮保留原始消息,更早的历史压缩成简短摘要。
def compact_history(history, keep_last=2):
older = history[:-keep_last]
recent = history[-keep_last:]
if older:
summary = " | ".join(f"{turn['role']}: {turn['content']}" for turn in older)
else:
summary = None
return {
"summary": summary,
"recent": recent
}
history = [
{"role": "user", "content": "退款政策是什么?"},
{"role": "assistant", "content": "购买后 7 天内且学习进度低于 20% 可退款。"},
{"role": "user", "content": "如果我已经学了 30% 呢?"},
{"role": "assistant", "content": "那通常不符合退款条件。"},
]
memory_view = compact_history(history, keep_last=2)
print(memory_view)
预期输出:
{'summary': 'user: 退款政策是什么? | assistant: 购买后 7 天内且学习进度低于 20% 可退款。', 'recent': [{'role': 'user', 'content': '如果我已经学了 30% 呢?'}, {'role': 'assistant', 'content': '那通常不符合退款条件。'}]}
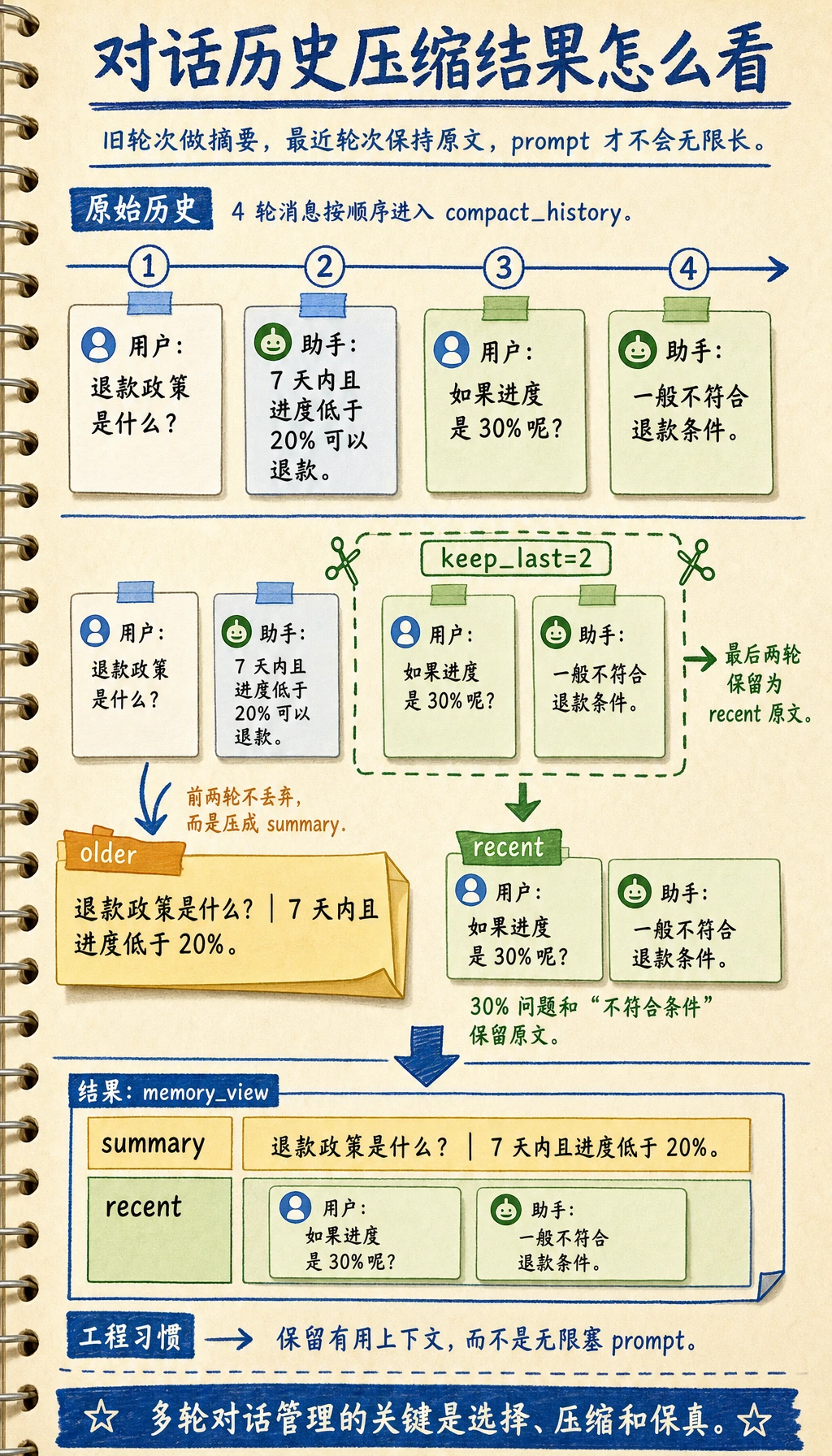
这仍然是教学版代码,但它训练的是很重要的工程习惯:不要让 prompt 无限增长。最近对话保留准确内容,较早上下文要有意识地摘要。
一个更完整一点的多轮示例
def dialog_reply(session, user_message):
add_turn(session, "user", user_message)
if "退款" in user_message:
session["topic"] = "refund"
reply = "退款政策是:购买后 7 天内且学习进度低于 20% 可退款。你是想看时间,还是想判断自己是否符合资格?"
elif "30%" in user_message and session["topic"] == "refund":
reply = "如果你的学习进度是 30%,通常不符合退款条件。"
else:
reply = "我可以继续帮助你处理当前主题。"
add_turn(session, "assistant", reply)
return reply
session = new_session()
print(dialog_reply(session, "退款政策是什么?"))
print(dialog_reply(session, "那如果我已经学了 30% 呢?"))
print(session)
预期输出:
退款政策是:购买后 7 天内且学习进度低于 20% 可退款。你是想看时间,还是想判断自己是否符合资格?
如果你的学习进度是 30%,通常不符合退款条件。
{'history': [{'role': 'user', 'content': '退款政策是什么?'}, {'role': 'assistant', 'content': '退款政策是:购买后 7 天内且学习进度低于 20% 可退款。你是想看时间,还是想判断自己是否符合资格?'}, {'role': 'user', 'content': '那如果我已经学了 30% 呢?'}, {'role': 'assistant', 'content': '如果你的学习进度是 30%,通常不符合退款条件。'}], 'topic': 'refund'}
这个例子真正比普通问答多了什么?
它多出来的关键不是模型更强,而是:
- 主题跟踪
- 上下文继承
也就是说:
对话系统的核心,常常首先是状态设计。
一个新人很值得先记的状态表
| 状态类型 | 它在记录什么 |
|---|---|
| history | 之前说过的话 |
| topic | 现在主要在聊什么 |
| slot | 当前任务还缺哪些关键信息 |
| tool state | 工具是否已经调用、结果是否已拿到 |
这个表非常适合初学者,因为它能把“多轮对话的复杂性”拆成几个清楚的箱子。
对话系统常见的几类状态
topic state
当前到底在聊什么。
slot state
哪些关键信息已经知道,哪些还缺。
例如天气系统里:
- 城市已知 / 未知
- 日期已知 / 未知
tool state
哪些工具已经调过,哪些结果已经拿到。
这在 Agent 化对话里特别重要。
如果你的目标是“知识库驱动的课件生成助手”,最该维护哪些槽位?
这类项目和普通聊天最大的不同是:
- 用户常常不会一次把要求说全
比如用户可能先说:
- “帮我做一个折扣应用题的 Word 课件”
后面才补:
- “面向小学高年级”
- “要有 3 道练习题”
- “风格偏课堂讲解”
所以第一次做时,很适合把槽位先定成:
| 槽位 | 它在记录什么 |
|---|---|
topic | 课件主题 |
audience | 面向对象 / 年级 |
doc_format | Word / PPT |
style | 课堂讲解 / 提纲式 / 讲义式 |
exercise_count | 练习题数量 |
一个最小状态对象可以先写成:
state = {
"topic": "折扣应用题",
"audience": None,
"doc_format": "word",
"style": None,
"exercise_count": None,
}
print(state)
预期输出:
{'topic': '折扣应用题', 'audience': None, 'doc_format': 'word', 'style': None, 'exercise_count': None}
这个例子最重要的价值是:
- 让新人先明白“多轮对话在项目里到底在补什么信息”
一个更像真实项目的最小追问示例
def next_question(state):
if not state["audience"]:
return "这份课件主要面向哪个年级或人群?"
if not state["style"]:
return "你希望它更像课堂讲解,还是提纲式讲义?"
if not state["exercise_count"]:
return "你希望最后附几道练习题?"
return "信息已经比较完整,可以开始生成课件结构。"
state = {
"topic": "折扣应用题",
"audience": None,
"doc_format": "word",
"style": None,
"exercise_count": None,
}
print(next_question(state))
state["audience"] = "小学高年级"
print(next_question(state))
预期输出:
这份课件主要面向哪个年级或人群?
你希望它更像课堂讲解,还是提纲式讲义?
这会帮助新人先建立一个非常重要的直觉:
- 对话系统不是为了“多聊几句”
- 而是为了把生成任务需要的参数慢慢补齐
新人第一次做对话系统时最稳的顺序
更稳的顺序通常是:
- 先做单轮问答
- 再补主题状态
- 再补追问逻辑
- 最后再补工具状态和更复杂记忆
如果一开始就想把所有状态都做满,通常会很乱。
如果把它做成项目,最值得展示什么
最值得展示的通常不是:
- 一长串聊天截图
而是:
- 一轮带上下文继承的对话
- 主题状态如何变化
- 槽位如何被补齐
- 什么时候系统选择追问
- 什么时候系统继续回答
这样别人会更容易看出:
- 你做的是一个多轮系统
- 不只是把历史拼起来给模型
为什么多轮对话特别容易“跑偏”?
因为它很容易受这些影响:
- 上一轮主题残留
- 历史太长
- 用户表达不完整
- 状态没有显式记录
所以你会发现:
做对话系统时,“状态管理”往往比“回复多漂亮”更重要。
初学者最常踩的坑
只维护 history,不维护结构化状态
系统会越来越难控。
一问不清就瞎猜
很多时候追问比乱答好。
历史无限堆长
成本和噪声都会上升。
小结
这一节最重要的不是做出一个“会聊天”的函数,而是理解:
对话系统的核心,在于管理多轮状态,而不只是生成多轮文本。
只要这个区别真正建立起来,后面你再学智能助手、Agent 对话和记忆系统时,就会顺很多。
这节最该带走什么
- 对话系统的本质首先是状态管理
- 历史、主题、槽位和工具状态都可能是关键
- 先把简单状态做好,再逐步扩展,比一开始做“大记忆系统”更稳
练习
- 给本节示例再加一个“证书”主题状态。
- 为天气查询任务设计一个
slot state,比如城市和日期。 - 想一想:为什么“追问”往往是比“乱猜”更好的对话策略?
- 用自己的话解释:为什么说多轮对话的核心是状态管理,而不是历史拼接?