E.C.1 サポートベクターマシン
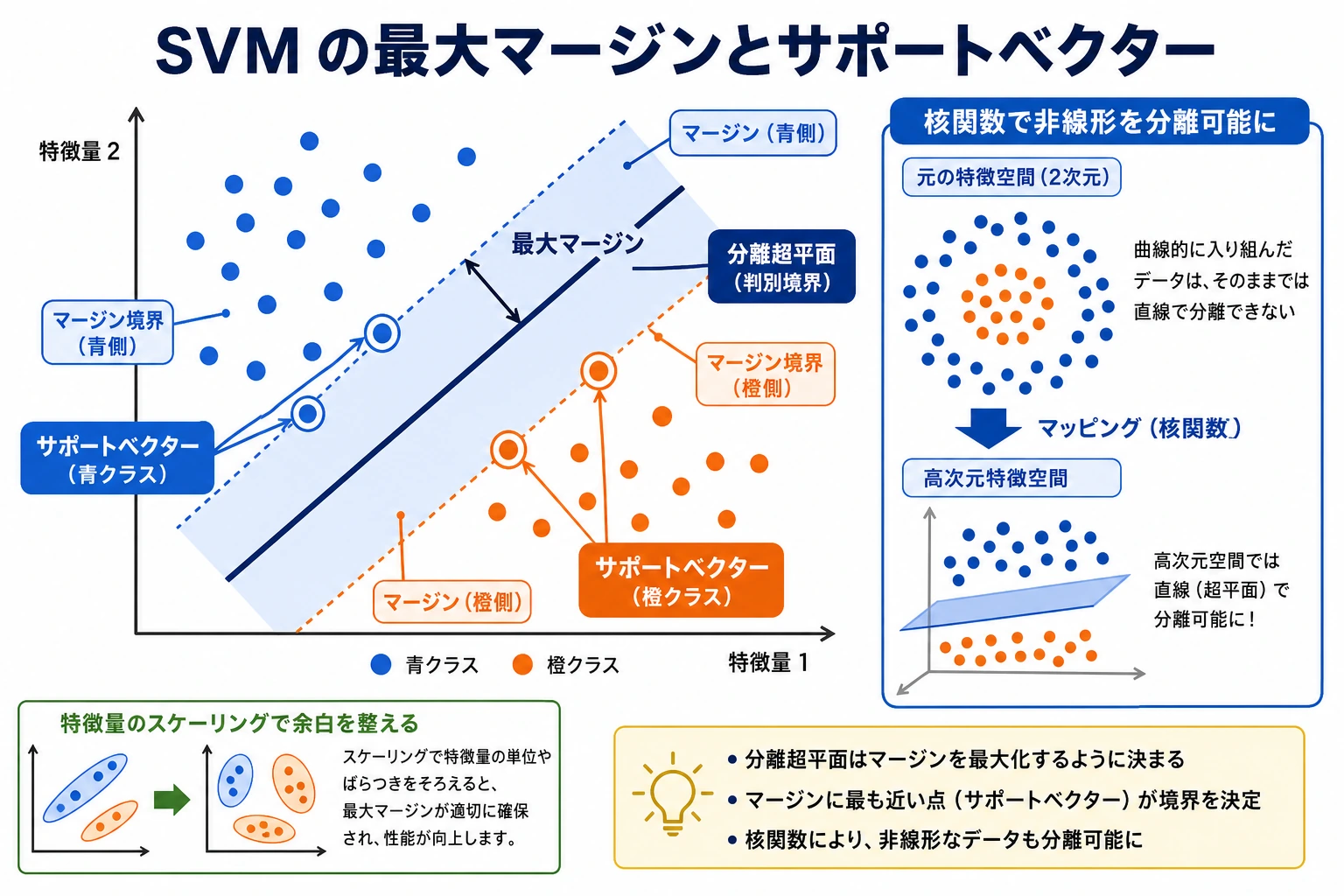
SVM は、マージンができるだけ大きい決定境界を探します。境界に最も近い点がサポートベクトルで、境界の位置を強く決める重要なサンプルです。
準備するもの
- Python 3.10+
- 現在の安定版
scikit-learnとnumpy
python -m pip install -U scikit-learn numpy
重要用語
- Margin(マージン):境界から最も近いサンプルまでの距離。
- Support vector(サポートベクトル):境界近くの重要サンプル。
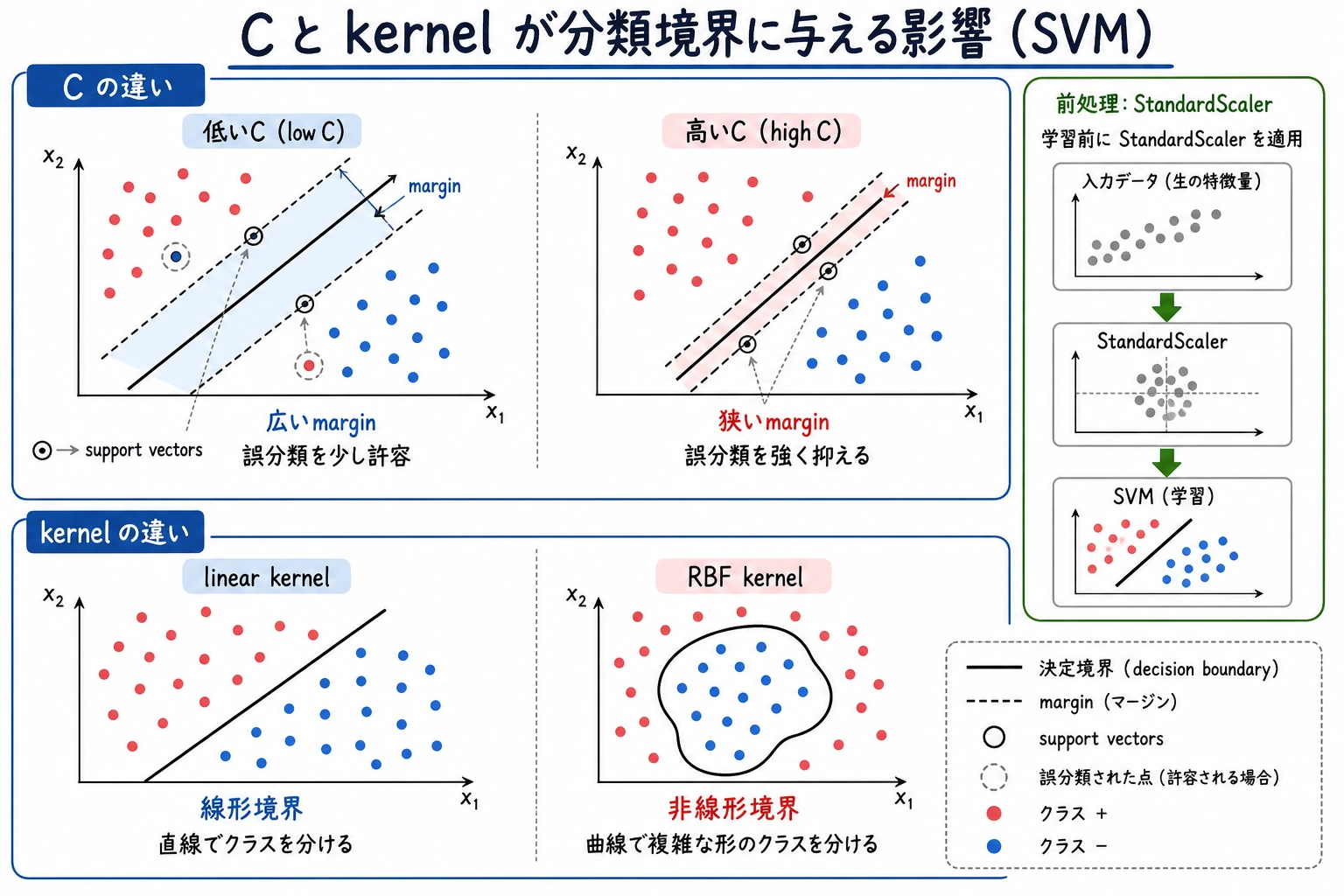
C:誤分類をどれだけ許すかを調整する値。大きいほど訓練データに強く合わせやすい。- Kernel(カーネル):境界を線形にするか非線形にするかを決める。
- Scaling(スケーリング):SVM では特徴量の範囲をそろえることが多くの場合必要。
線形 SVM ベースラインを動かす
svm_baseline.py を作成します。
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
X = np.array([
[1.0, 1.2],
[1.3, 0.9],
[1.1, 1.0],
[4.0, 4.2],
[4.3, 3.8],
[3.9, 4.1],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline(
StandardScaler(),
SVC(kernel="linear", C=1.0),
)
model.fit(X, y)
pred = model.predict([[1.2, 1.1], [4.2, 4.0]])
svc = model.named_steps["svc"]
print("predictions:", pred.tolist())
print("support_per_class:", svc.n_support_.tolist())
実行します。
python svm_baseline.py
期待される出力:
predictions: [0, 1]
support_per_class: [2, 1]
これが最小限の SVM 習慣です。特徴量をスケーリングし、モデルを学習し、予測し、サポートベクトルを確認します。
境界を変える
この単独の比較コードを実行します。
from sklearn.svm import SVC
for kernel in ["linear", "rbf"]:
if kernel == "linear":
model = SVC(kernel="linear", C=1.0)
else:
model = SVC(kernel="rbf", C=1.0, gamma="scale")
print(model)
期待される出力の先頭は次のようになります。
SVC(kernel='linear')
SVC()
境界が単純なら、まず linear を使います。線形 SVM が明らかに足りない場合や、境界が曲線的に見える場合に rbf を試します。
実用的な判断
SVM を試す場面:
- データが小中規模。
- 特徴量がすでに意味を持っている。
- クラス境界が比較的はっきりしている。
- 重いモデルの前に強いベースラインがほしい。
データが非常に大きい場合や、予測レイテンシが極端に厳しい場合は注意します。
よくある間違い
StandardScaler()を忘れる。- 線形を試す前に複雑な kernel から始める。
- 特徴量の質を確認せず、
Cと kernel だけを調整する。
練習
境界付近にノイズ点を2つ追加し、C=0.1、C=1.0、C=10.0 を比べます。それぞれのサポートベクトル数を記録してください。