E.C 古典的 ML ロードマップ
データセットが小さい、特徴量がはっきりしている、重いモデルを試す前に強いベースラインがほしい。そんなときに使う選択モジュールです。
まずベースラインの地図を見る
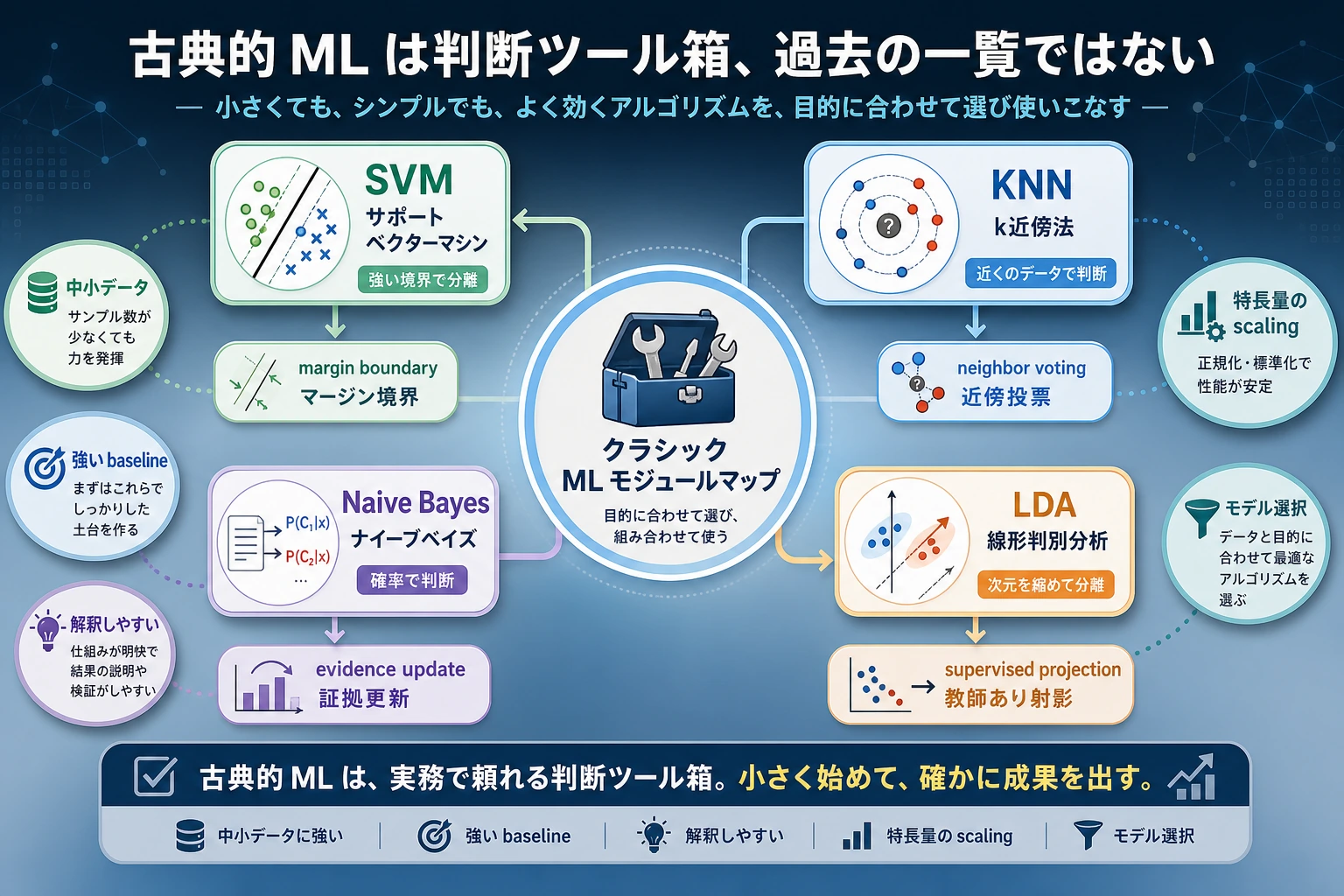
古典的 ML は、「この問題はシンプルな特徴量だけで解けるのか」を先に確かめる助けになります。
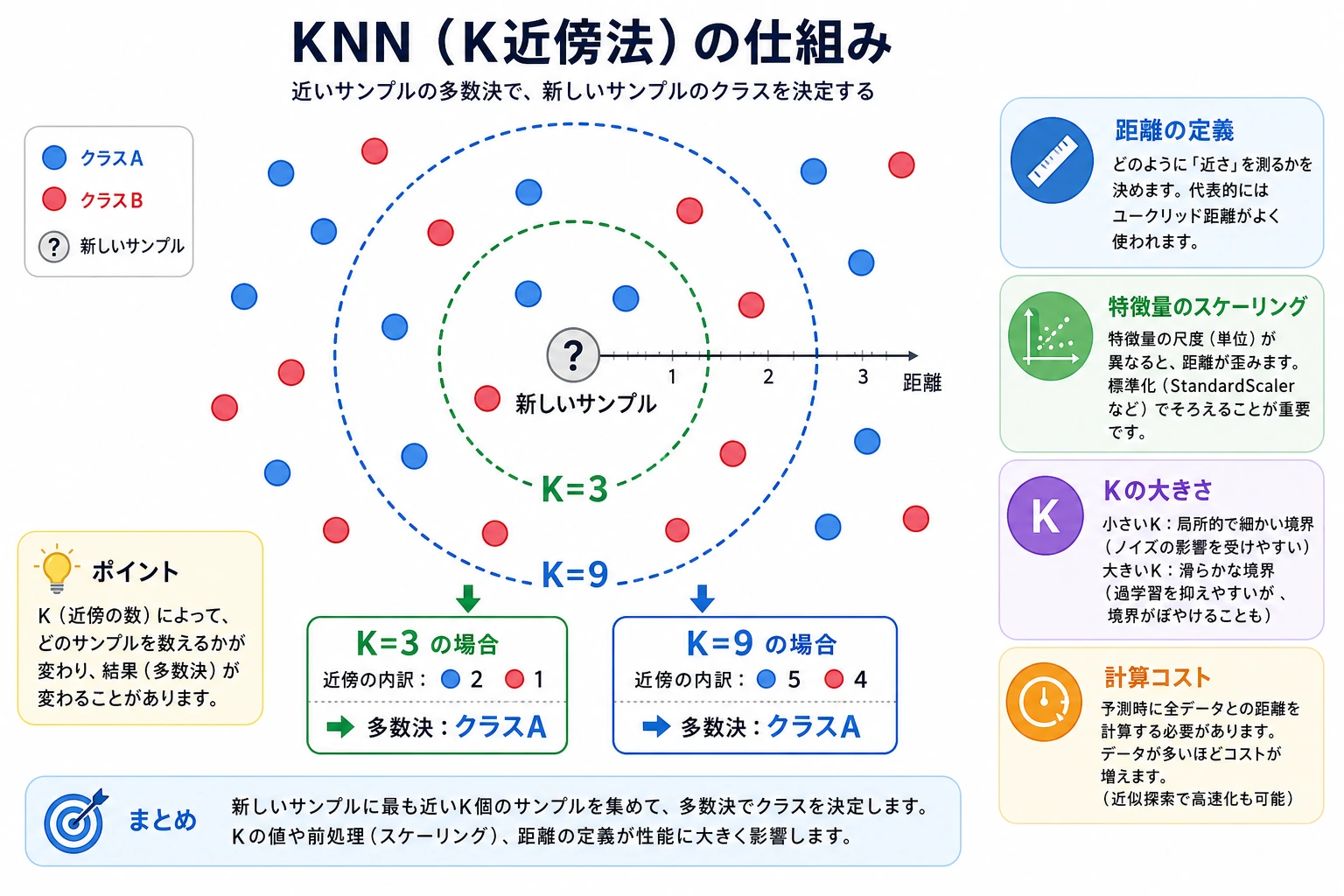
最小の KNN ベースラインを動かす
def distance(a, b):
return sum((x - y) ** 2 for x, y in zip(a, b)) ** 0.5
train = [
([0.1, 0.2], "low"),
([0.2, 0.1], "low"),
([0.8, 0.9], "high"),
([0.9, 0.8], "high"),
]
point = [0.75, 0.85]
nearest = min(train, key=lambda row: distance(row[0], point))
print("prediction:", nearest[1])
print("neighbor:", nearest[0])
期待される出力:
prediction: high
neighbor: [0.8, 0.9]
これはベースライン作成の最小習慣です。特徴量を決め、距離を比べ、予測し、その結果を後で比較できるように残します。
この順番で学ぶ
| Step | レッスン | 実践で残す成果 |
|---|---|---|
| 1 | E.C.1 SVM | マージン、サポートベクトル、C、カーネル選択を説明する |
| 2 | E.C.2 KNN | 距離と投票によるベースラインを作る |
| 3 | E.C.3 ナイーブベイズ | 証拠の件数をクラス確率に変換する |
| 4 | E.C.4 LDA | 特徴量を投影してクラスを分ける |
合格チェック
古典的なベースラインを 1 つ作り、それがなぜ適切か説明し、より重いモデルまたは後続プロジェクトの結果と比較できれば合格です。