E.C.3 ナイーブベイズ
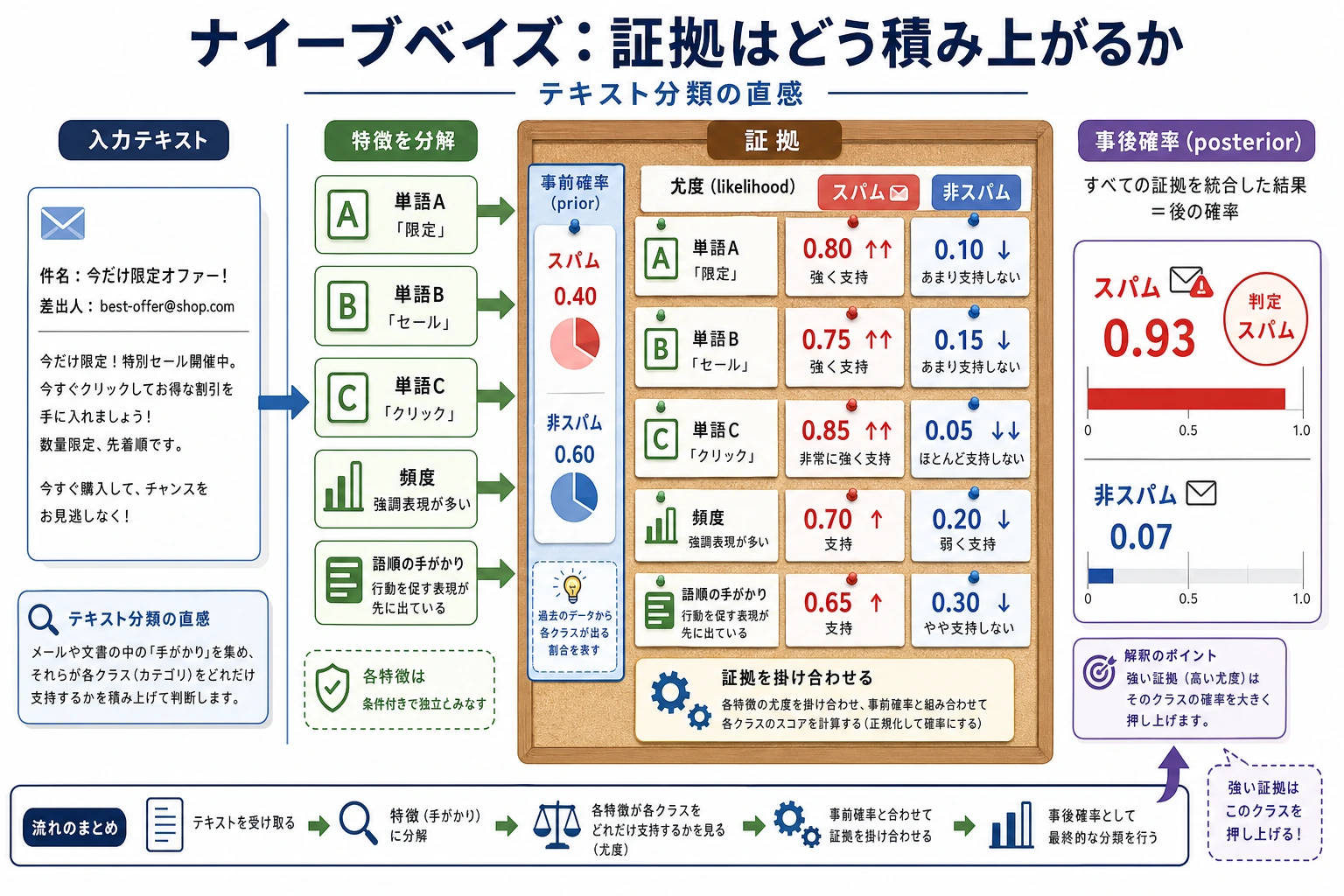
ナイーブベイズは、観測された証拠をどのクラスがより生成しやすいかを比べます。テキスト分類では、単語数だけでも安くて有用なベースラインになることがあります。
準備するもの
- Python 3.10+
- 現在の安定版
scikit-learn
python -m pip install -U scikit-learn
重要用語
- Bag of words:単語数でテキストを表現する方法。
- 条件付き確率:あるクラスが与えられたとき、その証拠が現れる確率。
- ナイーブ仮定:クラスが決まれば、各特徴量は互いに独立だとみなす仮定。
- Smoothing(平滑化):未知語が確率ゼロになるのを防ぐ。
alpha:MultinomialNBの平滑化の強さ。
テキスト分類器を動かす
naive_bayes_text.py を作成します。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
texts = [
"How long does a refund take?",
"How do I apply for a refund?",
"When can I issue an invoice?",
"Where is the e-invoice sent?",
"What should I do if I forget my password?",
"Where is the password reset entry?",
]
labels = [
"refund",
"refund",
"invoice",
"invoice",
"password",
"password",
]
model = make_pipeline(
CountVectorizer(),
MultinomialNB(alpha=1.0),
)
model.fit(texts, labels)
pred = model.predict([
"How do I handle a refund?",
"When can I issue an e-invoice?",
])
print("predictions:", pred.tolist())
実行します。
python naive_bayes_text.py
期待される出力:
predictions: ['refund', 'invoice']
これは完全なベースラインです。テキストを単語数に変え、単語数を確率に変え、確率をラベルに変えます。
平滑化を変える
alpha=1.0 を 0.1 と 2.0 に変更します。小さなデータセットでは、平滑化が希少語への信頼度に大きく影響することがあります。
実用的な判断
ナイーブベイズを試す場面:
- タスクがテキスト分類。
- すぐにベースラインが必要。
- データが少ない、またはラベルが単純。
- ある程度の説明しやすさが必要。
意味、文脈、語順が非常に重要な場合は、より強いモデルに進みます。
よくある間違い
- 「ナイーブ」だから役に立たないと思い込む。
- 特徴表現が重要であることを忘れる。
- 大きなモデルとの比較だけをし、安いベースラインとして使わない。
練習
certificate クラスと例文を2つ追加します。その後、新しい証明書関連の質問が新ラベルに分類されるか確認してください。