E.C.3 Naive Bayes
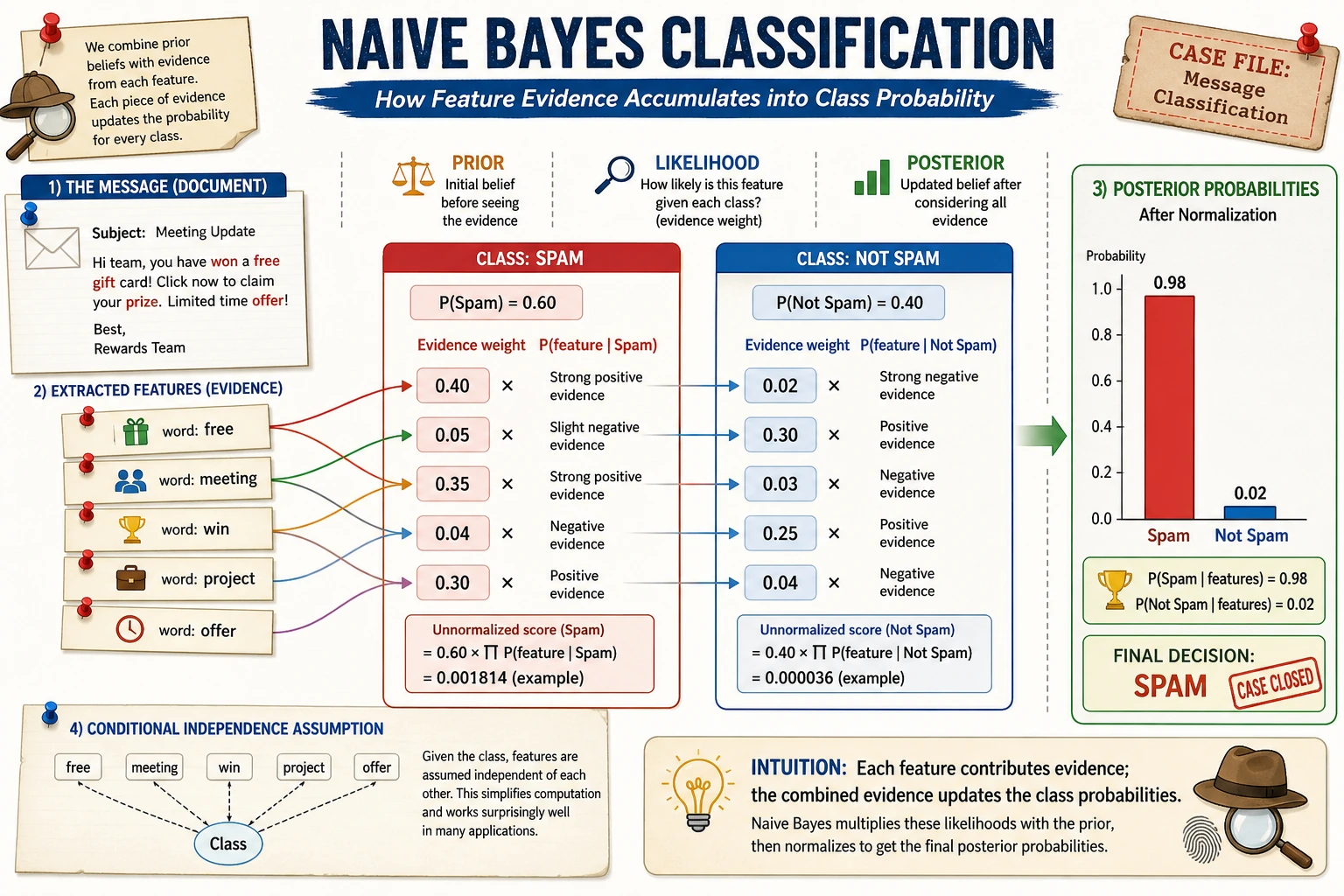
Naive Bayes compares which class is more likely to generate the observed evidence. In text tasks, word counts are often strong enough to create a cheap and useful baseline.
What You Need
- Python 3.10+
- Current stable
scikit-learn
python -m pip install -U scikit-learn
Key Terms
- Bag of words: represent text by word counts.
- Conditional probability: probability of evidence given a class.
- Naive assumption: features are treated as independent given the class.
- Smoothing: prevents unseen words from becoming impossible.
alpha: smoothing strength inMultinomialNB.
Run A Text Classifier
Create naive_bayes_text.py:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
texts = [
"How long does a refund take?",
"How do I apply for a refund?",
"When can I issue an invoice?",
"Where is the e-invoice sent?",
"What should I do if I forget my password?",
"Where is the password reset entry?",
]
labels = [
"refund",
"refund",
"invoice",
"invoice",
"password",
"password",
]
model = make_pipeline(
CountVectorizer(),
MultinomialNB(alpha=1.0),
)
model.fit(texts, labels)
pred = model.predict([
"How do I handle a refund?",
"When can I issue an e-invoice?",
])
print("predictions:", pred.tolist())
Run it:
python naive_bayes_text.py
Expected output:
predictions: ['refund', 'invoice']
This is a complete baseline: text to counts, counts to probabilities, probabilities to labels.
Change Smoothing
Change alpha=1.0 to 0.1 and 2.0. With tiny datasets, smoothing can noticeably change how strongly the model trusts rare words.
Practical Rule
Try Naive Bayes when:
- The task is text classification.
- You need a quick baseline.
- Data is small or labels are simple.
- Interpretability matters.
Move to stronger models when semantics, context, or word order matter a lot.
Common Mistakes
- Thinking “naive” means useless.
- Forgetting that feature representation still matters.
- Comparing it only with large models instead of using it as a cheap baseline.
Practice
Add a certificate class with two examples. Then test whether a new certificate question is routed to the new label.