E.C.2 K-Nearest Neighbors
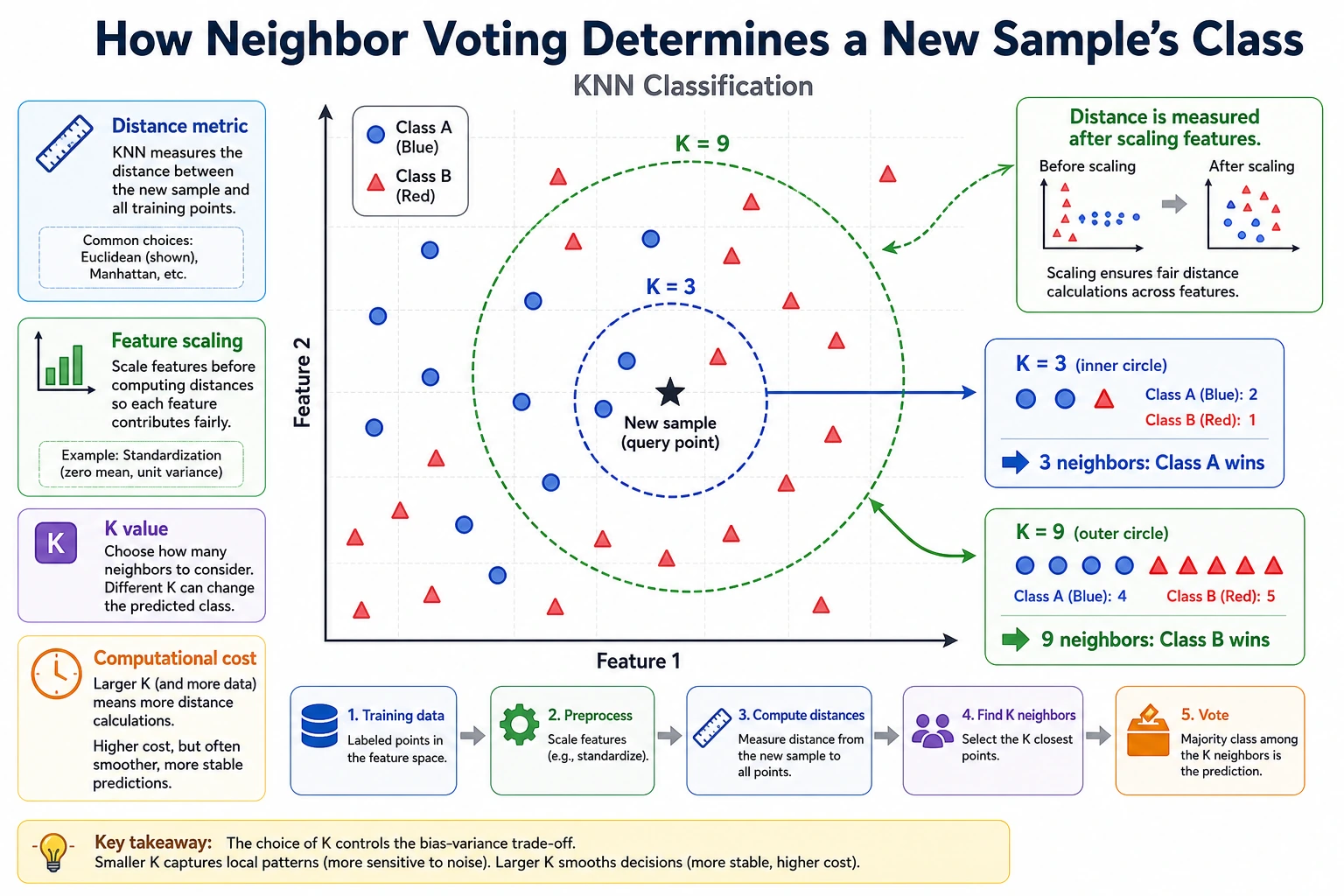
KNN makes a prediction by looking at the nearest labeled samples and letting them vote. It has almost no training cost, but prediction can become expensive because it must compare distances.
What You Need
- Python 3.10+
- Current stable
scikit-learnandnumpy
python -m pip install -U scikit-learn numpy
Key Terms
- K: how many neighbors vote.
- Distance metric: how “near” is calculated.
- Lazy learning: little work during training, more work during prediction.
- Scaling: required when feature ranges differ.
Run A Neighbor Vote
Create knn_vote.py:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X = np.array([
[1, 1],
[2, 2],
[2, 1],
[8, 8],
[9, 9],
[8, 9],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline(
StandardScaler(),
KNeighborsClassifier(n_neighbors=3),
)
model.fit(X, y)
pred = model.predict([[3, 3], [8.5, 8.2]])
print("predictions:", pred.tolist())
Run it:
python knn_vote.py
Expected output:
predictions: [0, 1]
The model did not learn a complex formula. It stored examples, scaled features, measured distance, and voted.
Change K
Change n_neighbors=3 to 1 and 5. Small K reacts strongly to local points; large K smooths the decision.
Practical Rule
Try KNN when:
- The dataset is small.
- Feature distances are meaningful.
- You want an interpretable baseline quickly.
- Prediction latency is not strict.
Avoid it as a default for huge datasets or real-time high-QPS services.
Common Mistakes
- Forgetting to scale features.
- Treating KNN as “trained” when most cost happens at prediction time.
- Tuning K before checking whether the features actually express similarity.
Practice
Add a third feature with values around 10000, remove StandardScaler(), and observe how distance voting becomes distorted.