E.C.2 K 近邻
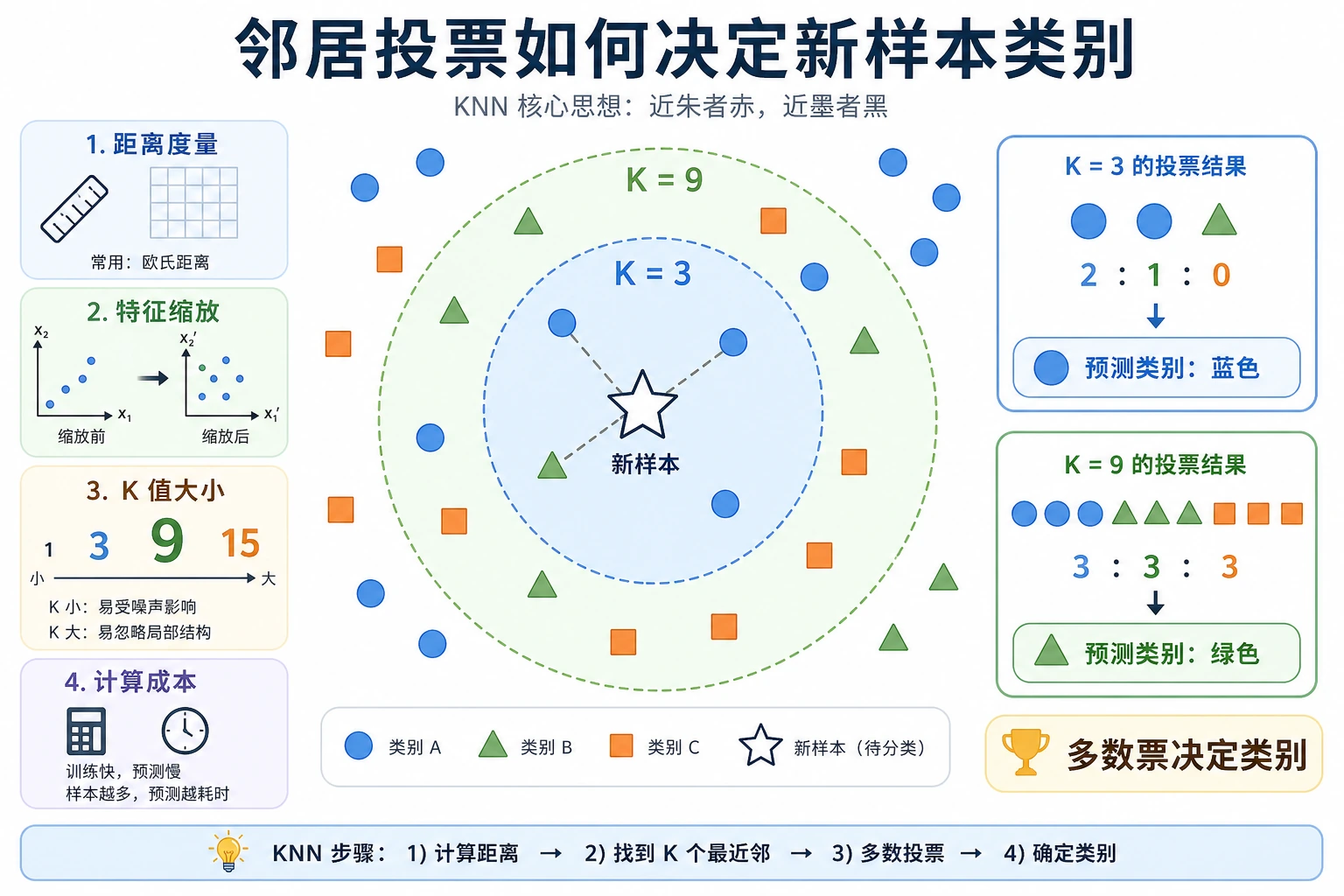
KNN 会看离新样本最近的已标注样本,再让它们投票。它几乎没有训练成本,但预测时要比较距离,所以数据大时会变慢。
准备内容
- Python 3.10+
- 当前稳定版
scikit-learn和numpy
python -m pip install -U scikit-learn numpy
关键术语
- K:参与投票的邻居数量。
- 距离度量:如何计算“近”。
- Lazy learning(惰性学习):训练时做得少,预测时做得多。
- Scaling(缩放):特征范围不一致时必须做。
运行邻居投票
创建 knn_vote.py:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X = np.array([
[1, 1],
[2, 2],
[2, 1],
[8, 8],
[9, 9],
[8, 9],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline(
StandardScaler(),
KNeighborsClassifier(n_neighbors=3),
)
model.fit(X, y)
pred = model.predict([[3, 3], [8.5, 8.2]])
print("predictions:", pred.tolist())
运行:
python knn_vote.py
预期输出:
predictions: [0, 1]
这个模型没有学复杂公式。它保存样本、缩放特征、计算距离,然后投票。
改变 K
把 n_neighbors=3 改成 1 和 5。K 小时更敏感,K 大时决策更平滑。
实用判断
适合尝试 KNN:
- 数据集较小。
- 特征距离有实际意义。
- 想快速做一个可解释 baseline。
- 预测延迟要求不严格。
如果数据量巨大,或者服务是高 QPS 实时预测,就不要默认用它。
常见错误
- 忘记缩放特征。
- 以为 KNN 已经“训练好了”,忽略预测时才是主要成本。
- 没检查特征是否表达相似性,就先调 K。
练习
添加第三个特征,数值范围在 10000 左右。移除 StandardScaler(),观察距离投票如何被扭曲。