E.C.4 线性判别分析
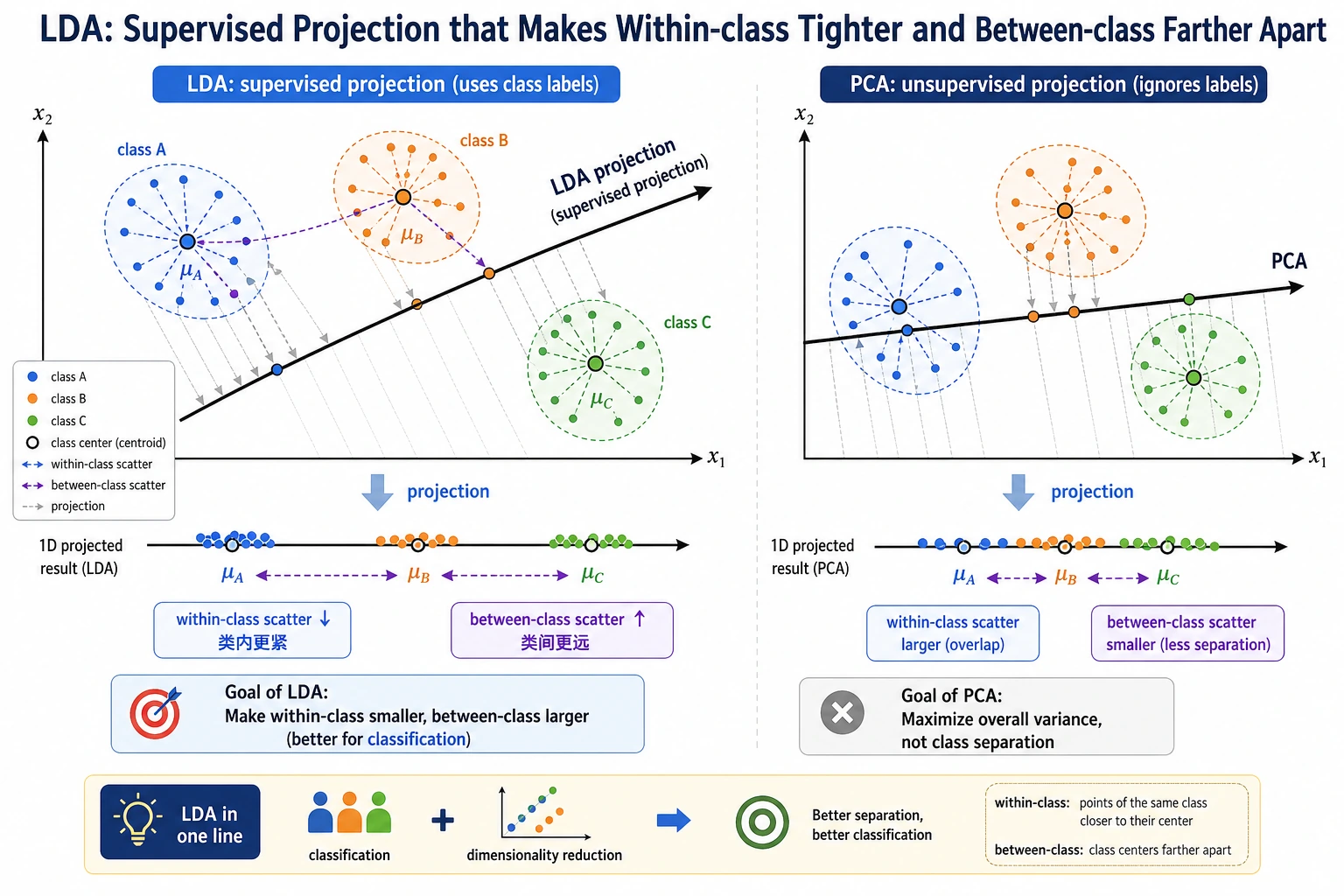
LDA 会寻找一个投影方向,让同类样本更靠近、不同类样本更分开。它既可以做分类,也可以做有监督降维。
准备内容
- Python 3.10+
- 当前稳定版
scikit-learn和numpy
python -m pip install -U scikit-learn numpy
关键术语
- 类内方差:同一个类别内部有多分散。
- 类间分离:不同类别中心之间有多远。
- 投影:把特征映射到更低维空间。
- 有监督降维:降维时使用标签信息。
- 这里的 LDA:Linear Discriminant Analysis,不是 Latent Dirichlet Allocation。
运行 LDA 分类和投影
创建 lda_projection.py:
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([
[1.0, 2.0],
[1.5, 1.8],
[2.0, 1.5],
[4.0, 5.0],
[4.5, 4.8],
[5.0, 4.5],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = LinearDiscriminantAnalysis(n_components=1)
model.fit(X, y)
pred = model.predict([[1.4, 1.9], [4.8, 4.6]])
projection = model.transform(X)
print("predictions:", pred.tolist())
print("projection_shape:", projection.shape)
运行:
python lda_projection.py
预期输出:
predictions: [0, 1]
projection_shape: (6, 1)
同一个模型既完成了新点分类,也把训练数据投影到一个有判别力的一维方向。
和 PCA 对比
PCA 寻找整体方差大的方向,不看标签。LDA 使用标签,寻找最能分开类别的方向。当类别分离比通用压缩更重要时,LDA 更有意义。
实用判断
适合尝试 LDA:
- 已有标签。
- 类别内部比较紧凑。
- 想做轻量线性 baseline。
- 想为可视化或下游模型得到低维表示。
如果类别边界明显高度非线性,就不要优先用它。
常见错误
- 把这里的 LDA 和主题模型 LDA 混淆。
- 以为 LDA 用标签,所以一定比 PCA 好。
- 忘记两个类别时,LDA 最多只能投影到一个分量。
练习
添加第三个类别,并设置 n_components=2。打印新的投影形状,并解释为什么最大分量数变了。