E.C.1 支持向量机
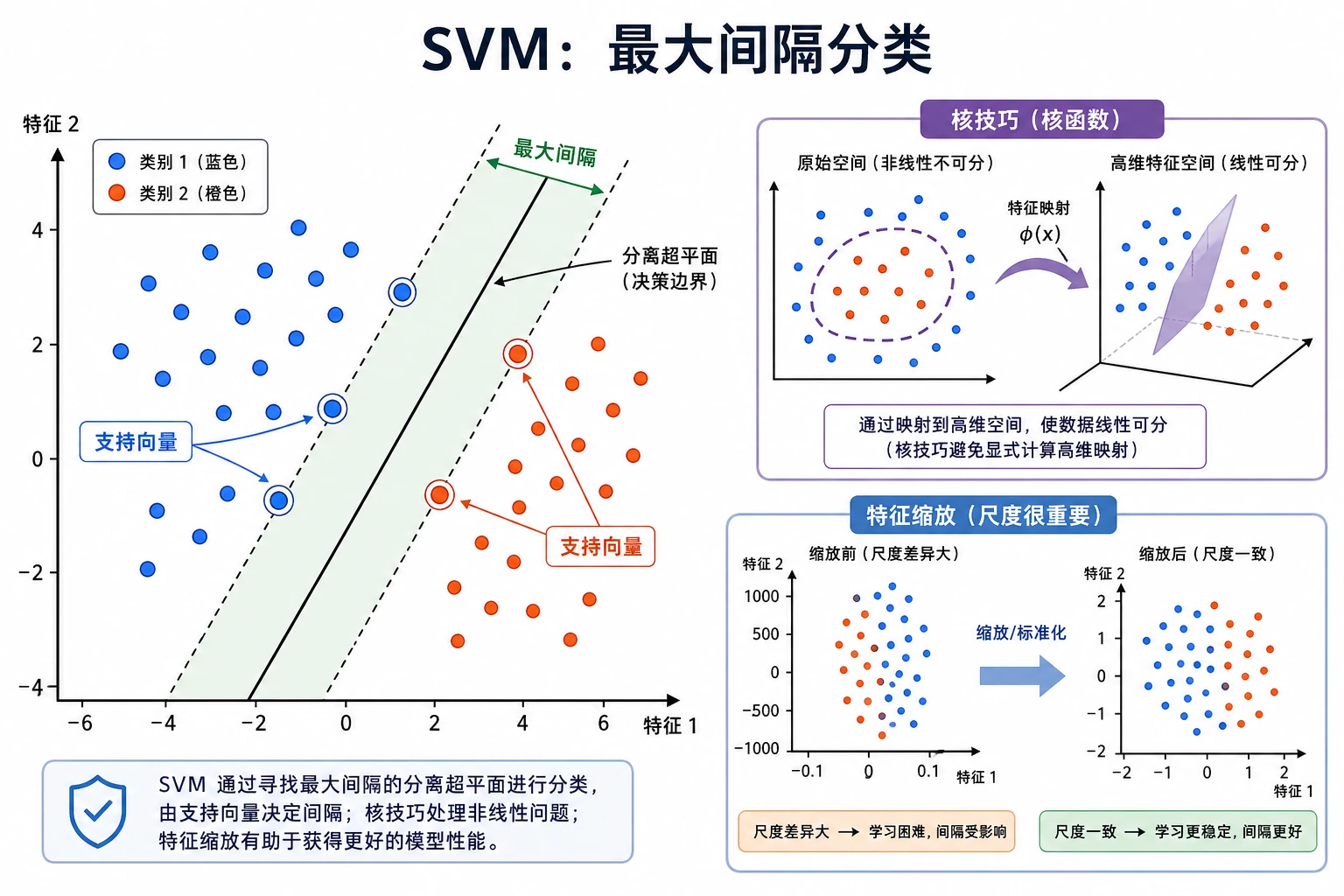
SVM 会寻找一个间隔尽量大的决策边界。离边界最近的点叫支持向量,它们是最影响边界位置的关键样本。
准备内容
- Python 3.10+
- 当前稳定版
scikit-learn和numpy
python -m pip install -U scikit-learn numpy
关键术语
- Margin(间隔):边界到最近样本的距离。
- Support vector(支持向量):靠近边界的关键样本。
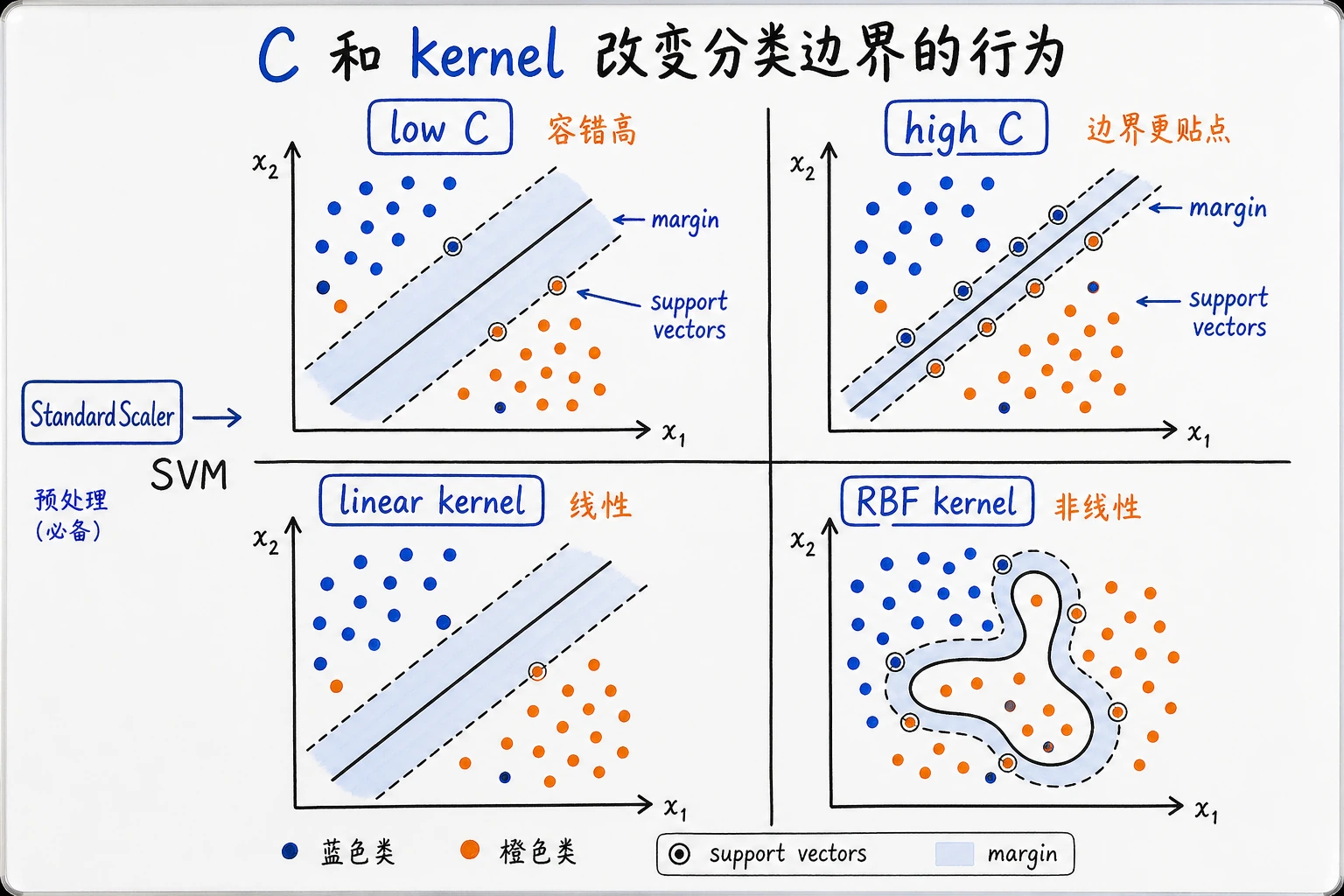
C:控制对错误的容忍度。C越大,通常越贴合训练集。- Kernel(核函数):控制边界是线性的,还是非线性的。
- Scaling(缩放):SVM 通常需要把特征范围标准化。
运行线性 SVM baseline
创建 svm_baseline.py:
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
X = np.array([
[1.0, 1.2],
[1.3, 0.9],
[1.1, 1.0],
[4.0, 4.2],
[4.3, 3.8],
[3.9, 4.1],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline(
StandardScaler(),
SVC(kernel="linear", C=1.0),
)
model.fit(X, y)
pred = model.predict([[1.2, 1.1], [4.2, 4.0]])
svc = model.named_steps["svc"]
print("predictions:", pred.tolist())
print("support_per_class:", svc.n_support_.tolist())
运行:
python svm_baseline.py
预期输出:
predictions: [0, 1]
support_per_class: [2, 1]
这是最小可用 SVM 习惯:缩放特征、训练模型、预测、检查支持向量。
改变边界
运行这个独立对比:
from sklearn.svm import SVC
for kernel in ["linear", "rbf"]:
if kernel == "linear":
model = SVC(kernel="linear", C=1.0)
else:
model = SVC(kernel="rbf", C=1.0, gamma="scale")
print(model)
预期输出开头类似:
SVC(kernel='linear')
SVC()
边界简单时先用 linear。如果线性 SVM 明显欠拟合,或者边界看起来是弯曲的,再尝试 rbf。
实用判断
适合尝试 SVM:
- 数据量中小。
- 特征已经有意义。
- 类别边界比较清楚。
- 想在重模型之前做一个强 baseline。
如果数据很大,或者预测延迟要求极低,就要谨慎。
常见错误
- 忘记
StandardScaler()。 - 还没试线性就直接上复杂 kernel。
- 没检查特征质量,就先调
C和 kernel。
练习
在边界附近加两个噪声点,对比 C=0.1、C=1.0、C=10.0。记录每个版本用了多少支持向量。