12.4.4 AI 法规与合规
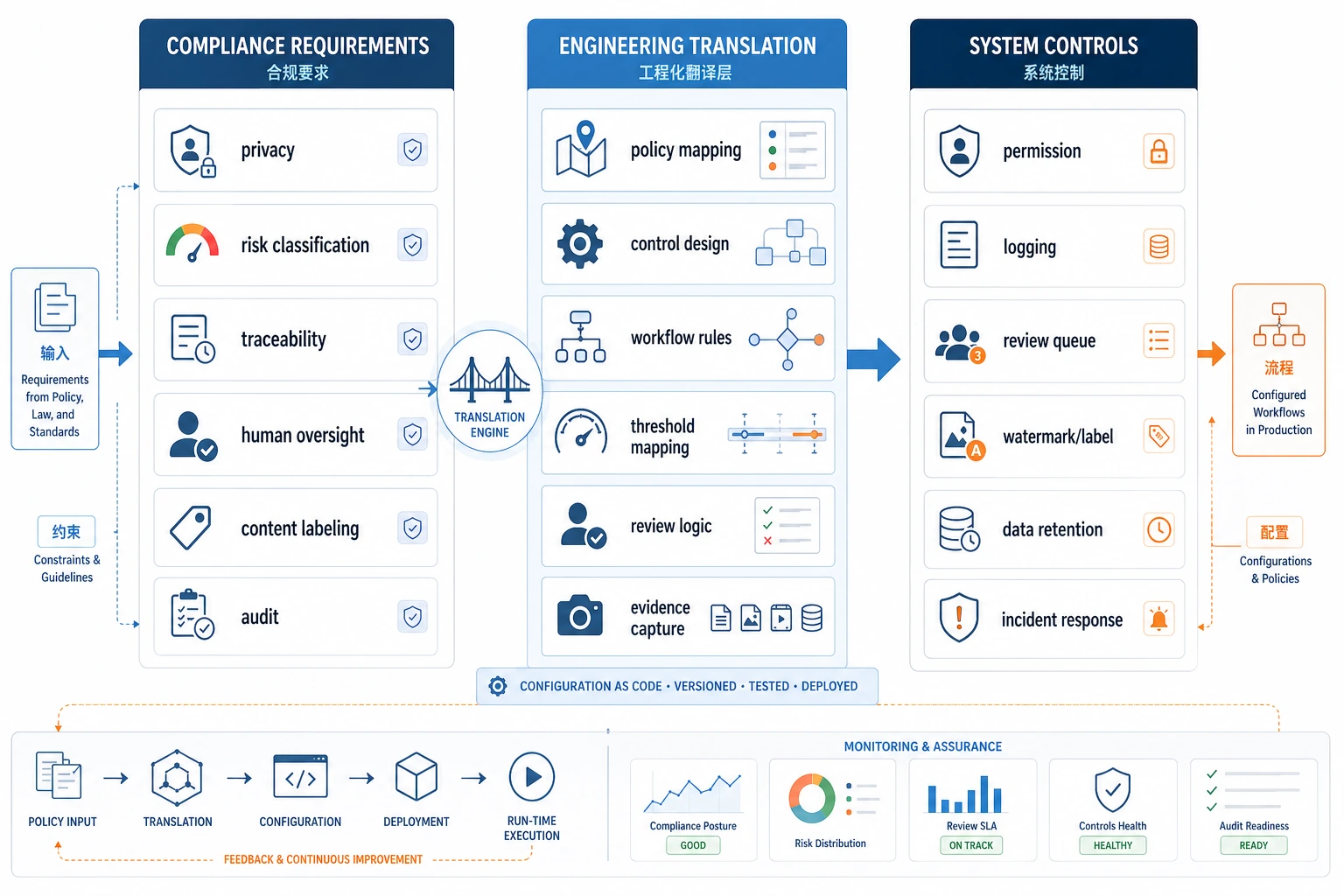
合规要求最终会变成系统设计要求:数据权限、日志审计、风险分级、人工监督、内容标记和可追溯性。读图时重点看“法规语言”如何被翻译成“工程配置”。
讲法规最容易让人觉得离技术很远。 但一旦系统真的进入:
- 企业环境
- 商业产品
- 高风险行业
你会很快发现:
合规不是最后才补的一层,而是会反过来影响系统结构。
这节课就是想把这个关系讲清楚。
学习目标
- 理解为什么 AI 合规问题会直接影响产品设计
- 理解风险分级、审计、可追溯性这些关键词为什么重要
- 学会把法规要求转译成系统要求
- 建立“法规问题不是法务单独处理,而是技术也必须参与设计”的视角
先建立一张地图
AI 法规与合规更适合按“法律要求 -> 系统能力 -> 工程落实”来理解:
所以这节真正想解决的是:
- 为什么法规问题会直接长进系统结构里
- 为什么技术团队必须参与“合规翻译”
一、为什么法规问题离工程师并不远?
一个常见误解
很多技术同学会下意识觉得:
- 法规是法务的事
- 模型是工程的事
但实际项目里,这两者经常会直接相遇。
为什么会相遇?
因为很多法规要求本质上最后都会变成这些问题:
- 你有没有日志
- 你能不能追溯来源
- 你有没有权限控制
- 你能不能人工接管
也就是说:
法规要求最终经常会落成系统能力要求。
所以合规不是后置检查,而经常是架构输入。
一个更适合新人的总类比
你可以把合规理解成:
- 产品上线前必须满足的一组“建筑规范”
建筑规范不会直接告诉你砖怎么摆, 但它会规定:
- 哪里必须留消防通道
- 哪些地方必须加安全出口
AI 合规也很像这样:
- 它不是直接替你写代码
- 但它会反过来限制你系统必须长成什么样
二、最常见的合规关注点有哪些?
数据与隐私
系统是否处理了:
- 个人信息
- 敏感信息
- 企业内部数据
可追溯性
系统是否能解释:
- 这条答案从哪来
- 哪些数据被用过
- 哪一步做了什么
风险分级
不同系统风险等级不同。 并不是所有生成系统都要同样强的管控。
人工监督与申诉机制
在高风险场景里,系统通常不能完全自动闭环。
三、一个很实用的工程翻译思路
把法规要求翻成系统要求,通常可以这样看:
| 法规 / 合规问题 | 工程上会变成什么要求 |
|---|---|
| 数据保护 | 脱敏、权限控制、最小化留存 |
| 可解释 / 可追溯 | 日志、trace、来源引用 |
| 高风险决策限制 | 人工确认、双重审批、拒绝自动执行 |
| 审计能力 | 操作记录、版本记录、请求留痕 |
这张表非常重要,因为它让“合规”从抽象词变成了可工程化的问题。
一个很适合初学者先记的判断表
| 合规要求 | 技术侧最先该想到什么 |
|---|---|
| 数据保护 | 脱敏、权限、留存边界 |
| 可追溯 | 日志、trace、引用来源 |
| 高风险限制 | 审批流、人工确认、拒绝自动执行 |
| 审计 | 版本记录、操作留痕、配置可回放 |
这个表很适合新人,因为它会把“法规词汇”重新翻成工程语言。
四、为什么“可追溯性”几乎成了 AI 合规里的高频词?
因为很多 AI 系统的问题不是“输出错了”这么简单,而是:
- 你不知道它为什么错
- 你不知道它用了什么数据
- 你不知道是哪个模块出了问题
所以合规上经常会非常看重:
- 来源引用
- 任务 trace
- 决策日志
你可以把它理解成:
不只是系统要跑出来,还要能回头查出来。
五、风险分级为什么对 AI 系统特别重要?
并不是所有 AI 应用都应该按同一种强度管控。
例如:
- 一个海报生成器
- 一个医疗建议助手
它们的风险显然不在一个量级。
所以一个很核心的思想是:
治理和合规通常是分级的,不是“一刀切”的。
这会影响:
- 是否需要人工确认
- 是否允许自动决策
- 是否要求更强审计
六、一个最小“合规要求 -> 系统配置”示意
compliance_config = {
"data_traceable": True,
"human_override": True,
"audit_log_enabled": True,
"sensitive_action_requires_approval": True
}
print(compliance_config)
预期输出:
{'data_traceable': True, 'human_override': True, 'audit_log_enabled': True, 'sensitive_action_requires_approval': True}
这不是法律意见,而是一次“合规语言 -> 工程能力”的翻译练习。每个 True 都代表工程侧可以实现、测试和审计的一项能力。
这个例子虽然简单,但在表达一个很重要的思路:
合规要求最后经常会变成系统开关、策略和流程。
七、在 AIGC / Agent 场景里,哪些地方最容易碰到合规问题?
检索和知识库
如果系统会查内部文档,那就一定会涉及:
- 权限边界
- 来源范围
工具调用
如果系统会:
- 发邮件
- 改数据库
- 调企业系统
那自动执行风险会很快出现。
生成内容
如果系统会生成:
- 面向用户的建议
- 营销文案
- 合同草稿
那内容责任和误导风险就会上来。
八、为什么“人类在环(human-in-the-loop)”会越来越重要?
因为很多场景里,法规和合规最关心的不是:
- 模型能不能输出
而是:
- 最终关键动作是不是仍然有人能管住
例如:
- 高风险审批
- 对外正式发布
- 涉及法律和财务的决定
这意味着:
很多系统设计上需要预留“人工接管点”。
这既是合规要求,也是工程要求。
一个很适合初学者先记的分级思路
可以先把系统想成三类:
- 低风险:更多自动化
- 中风险:更强日志和审计
- 高风险:保留人工确认和接管点
这个分级思路很重要,因为它能帮助你避免“一刀切治理”。
九、一个很重要的工程习惯
如果你在做高风险 AI 应用,建议养成这种思路:
- 先问系统属于什么风险等级
- 再问需要哪些日志和追踪
- 再问哪些动作必须人工确认
- 最后再谈模型和工作流怎么实现
这会比“先把系统做完再补合规”稳得多。
如果把它做成系统设计或治理文档,最值得展示什么
最值得展示的通常不是:
- “我们满足合规”
而是:
- 风险等级怎么划
- 哪些能力是为了满足合规要求而加的
- 哪些动作必须人工确认
- 哪些日志和 trace 能支持审计
这样别人会更容易看出:
- 你理解的是合规到工程的翻译过程
- 不只是停留在政策层面
小结
这一节最重要的不是背法规条文,而是理解:
AI 法规与合规真正会落到技术侧的地方,通常是数据边界、日志追踪、权限控制和人工确认机制。
只要你开始这样看问题,合规就不再是“离工程很远的词”,而会变成你设计系统时必须正面考虑的一层。
练习
- 选一个你熟悉的 AI 系统,试着列出它在“数据、日志、权限、人工确认”四方面的要求。
- 想一想:为什么“可追溯性”会成为很多 AI 合规讨论里的核心词?
- 用自己的话解释:为什么说风险分级会直接影响系统设计?
- 试着把“合规”翻译成三个你能落到系统里的具体技术要求。