10.4.4 分割実戦
分割プロジェクトで最大の難しさは、モデル名そのものではなく、
むしろ次の点です。
- mask アノテーションの品質
- クラスの不均衡
- 評価方法が妥当かどうか
そのため、この節では最小限の分割プロジェクトの骨組みを分かりやすく整理することを重視します。
学習目標
- 最小限の分割プロジェクトを定義できるようになる
- mask データと指標の基本的な整理方法を理解する
- 実行可能な例を通して、プロジェクト評価の感覚をつかむ
- 分割プロジェクトで最も重要な結果の見せ方を学ぶ
まず全体の地図を作ろう
もし語義分割とインスタンス分割を学び終えたばかりなら、この節は自然な続きです。
- これまでに、mask や IoU といった要素が何をしているかは分かっている
- ここからは、「これを本当のプロジェクトにしたとき、どの工程で最初に問題が起きやすいか」を考える
つまり、この節で本当に大事なのは新しいネットワークではなく、次の点です。
- mask アノテーション
- クラス定義
- 評価方法
- 失敗サンプルの確認
分割実戦を学ぶとき、新人にとって一番分かりやすい流れは「いきなりモデルを学習する」ことではなく、まずプロジェクト全体の閉ループを把握することです。
この節で本当に解決したいのは、次のことです。
- 分割プロジェクトはどう進めるべきか
- モデル以外で、どこに問題が起きやすいのか
新人向けの、より分かりやすい全体比喩
分割プロジェクトは、次のように考えると理解しやすいです。
- たくさんの地図を、細かく色分けしていく作業
難しいのは「色を塗れるか」だけではありません。
- それぞれの境界が正確か
- 小さな領域が抜けていないか
- 全員が同じ基準で塗っているか
こう考えると、分割プロジェクトが特に次の要素に依存する理由が自然に見えてきます。
- mask の品質
- 境界の基準
- 失敗サンプルの分析
一、プロジェクト課題をどう決める?
練習用としてとても向いている分割プロジェクトは次のようなものです。
- 道路シーン分割
または
- 医療領域分割
共通する特徴は次の通りです。
- mask ラベルが明確
- 領域の境界が重要
- IoU 指標に意味がある
新人が最初に分割プロジェクトをやるとき、どんな題材を選ぶと安定しやすい?
より安定しやすい題材には、次のような特徴があります。
- クラス数が多すぎない
- 領域の境界が比較的はっきりしている
- 失敗サンプルを目で見て理解しやすい
そのため、最初のプロジェクトでは、
「クラスが少ない・境界が明確・説明しやすい」ことのほうが、「見た目が派手」であることより重要です。
なぜ「境界がはっきりしている」ことがそんなに重要なの?
分割タスクの多くの難しさは、次の部分に集中するからです。
- 境界
- 小さな領域
- クラスが混ざる部分
最初から境界がとても曖昧で、アノテーション基準も安定しないタスクを選ぶと、次の判断が難しくなります。
- モデルが弱いのか
- それともラベル自体が不安定なのか
二、まずは最小限の分割プロジェクト評価例を動かしてみよう
pred_masks = [
[[0, 0, 1], [0, 1, 1], [0, 0, 1]],
[[1, 1, 0], [1, 0, 0], [1, 0, 0]],
]
gt_masks = [
[[0, 0, 1], [0, 1, 1], [0, 1, 1]],
[[1, 1, 0], [1, 1, 0], [1, 0, 0]],
]
def iou(mask_a, mask_b, target=1):
inter = 0
union = 0
for row_a, row_b in zip(mask_a, mask_b):
for a, b in zip(row_a, row_b):
if a == target and b == target:
inter += 1
if a == target or b == target:
union += 1
return inter / union if union else 0.0
ious = [iou(pred, gt) for pred, gt in zip(pred_masks, gt_masks)]
mean_iou = sum(ious) / len(ious)
print("ious:", [round(x, 4) for x in ious])
print("mean_iou:", round(mean_iou, 4))
実行結果の例:
ious: [0.8, 0.8]
mean_iou: 0.8
この小さなデータでは、2つのサンプルがほぼ同じ性能です。実際のレポートでは、平均だけでなくサンプルごとの値も残してください。平均値だけでは悪いケースが隠れやすいからです。
この例で一番伝えたいことは何?
分割プロジェクトで最終的に重要なのは、たいてい次のような「1枚の見た目」ではありません。
- ある1枚の画像がそこそこ良く見えること
むしろ重要なのは、次のことです。
- 複数サンプル全体としてどうか
そのため、プロジェクトでは通常、次のような値をまとめて見ます。
- サンプルごとの IoU
- mean IoU
なぜ分割プロジェクトでは「サンプルごとに見直す」ことが特に大切なの?
平均値は、問題を隠してしまいやすいからです。
たとえば、
- 大きい領域のクラスはうまく分けられている
- 小さい領域の対象はすべて間違っている
この場合、平均スコアはそこそこ良く見えても、実際のプロジェクトとしては安定していません。
初めて分割プロジェクトをやるとき、どの失敗を先に分けて考えるとよい?
実用的な分け方は、次の3つです。
-
境界ミス
輪郭の大まかな位置は合っているが、端が粗い。 -
小さいクラスの見落とし
大きい背景はうまく分けられているのに、小さな対象がよく抜ける。 -
クラスの混同
2つの領域が互いにくっついてしまう。
この3つを分けると、次のどれを優先して改善するか決めやすくなります。
- データを追加するべきか
- 損失関数を変えるべきか
- それとも入力解像度を変えるべきか
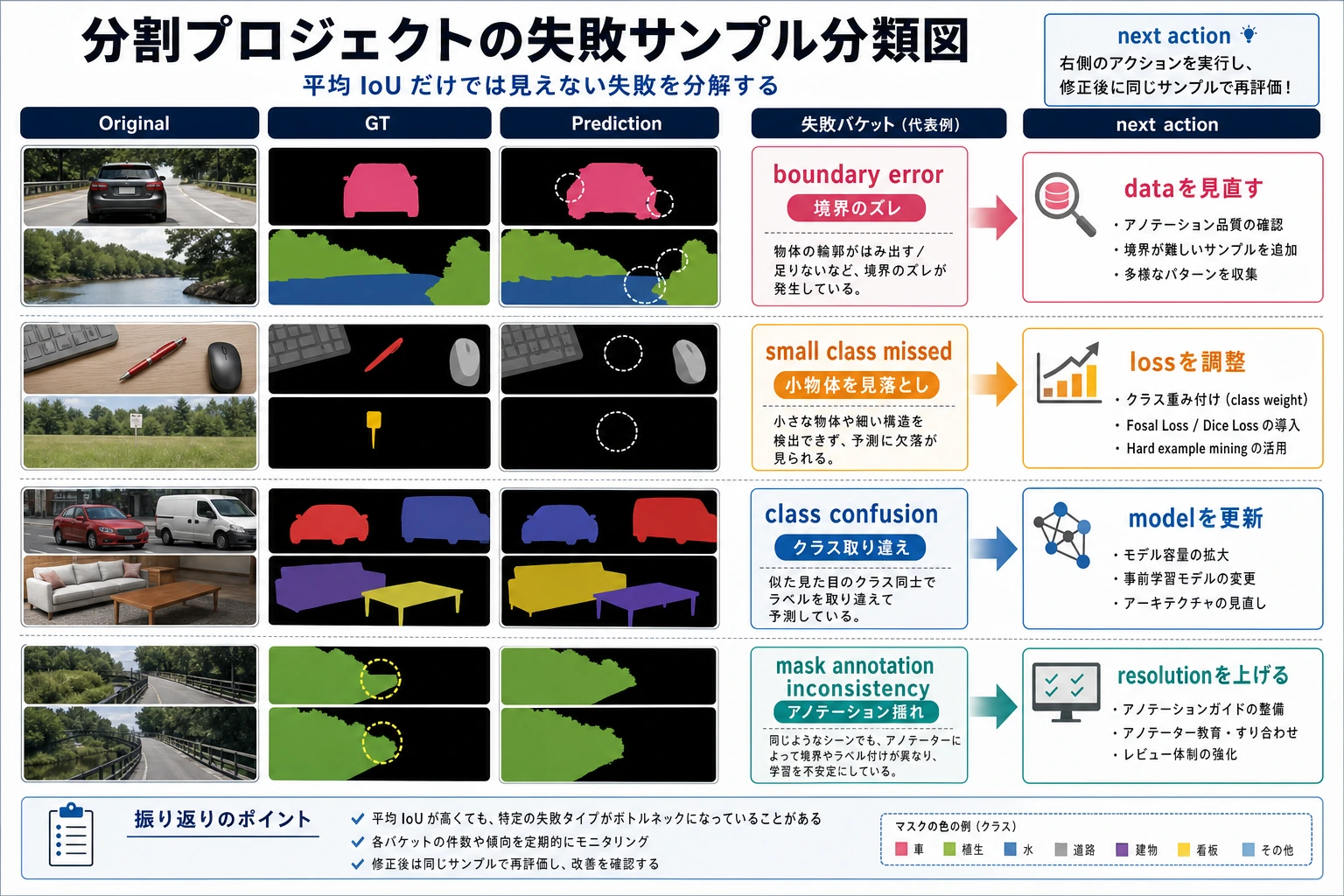
分割プロジェクトでは、平均スコアだけを見るのが最も危険です。この図では、失敗サンプルを境界ミス・小さいクラスの見落とし・クラス混同に分けているので、次にどの改善をすべきかを具体的な問題に結びつけられます。
もう1つ、最小限の「プロジェクト確認表」の例を見てみよう
checklist = {
"classes_defined": True,
"mask_quality_checked": True,
"baseline_ready": True,
"failure_buckets_defined": False,
}
def next_step(checklist):
if not checklist["classes_defined"]:
return "まずクラス定義を絞り込んでください。"
if not checklist["mask_quality_checked"]:
return "まず mask アノテーションの品質をサンプル確認してください。"
if not checklist["baseline_ready"]:
return "まず最小限の baseline を作ってください。"
if not checklist["failure_buckets_defined"]:
return "まず失敗サンプルを分類してください。"
return "ここから先は、個別の改善に進めます。"
print(next_step(checklist))
実行結果の例:
まず失敗サンプルを分類してください。
baseline と mask の確認は済んでいるので、次にやるべきことは「より大きいモデルを試す」ではありません。失敗サンプルを分類し、次の改善対象をはっきりさせることです。
この例はとても小さいですが、新人が次のことを理解するのに役立ちます。
- プロジェクトは、モデル学習が動くかどうかだけではない
- プロジェクト全体の骨組みが整っているかも大事
三、分割プロジェクトで起きやすい落とし穴
mask アノテーションの境界がそろっていない
これがあると、学習も評価もまとめて汚れてしまいます。
クラスの不均衡が大きすぎる
小さい領域のクラスは、よく大きな背景に埋もれてしまいます。
平均値だけ見て、失敗サンプルを見ない
平均値では、ひどいケースが見えなくなることがあります。
成功サンプルだけを見せて、境界の失敗を見せない
分割プロジェクトは、見た目が「良さそう」に見えやすいです。
色つきの mask 画像は、それだけで視覚的なインパクトが強いからです。
しかし、次のような失敗を見せないと、
- 境界の失敗
- 小さい対象の見落とし
- クラスの混同
そのプロジェクトが本当にどこまで安定しているのか判断しにくくなります。
四、新人がそのまま真似しやすい進め方
おすすめの順番は次の通りです。
- まずクラス定義を明確にする
- 次に mask アノテーションを抽出して確認する
- まず最小限の baseline を作る
- その後で IoU を統一して評価する
- 最後に失敗サンプルだけを個別に分析する
この順番のほうが、最初からモデルを次々変えるよりずっと効果的です。
ポートフォリオとして見せるなら、何を出すべき?
色つきの mask 画像を1枚貼るだけより、次のものを見せるほうが価値があります。
- 元画像 / GT / 予測の3枚並べ
- クラスごとの IoU
- 典型的な失敗サンプル
- その失敗をどう説明するか
- 次にどこを直すか
初めてこうしたプロジェクトに取り組むときの、いちばん安定した目標
初回で目指すべきなのは、次のようなことです。
- クラス定義が明確である
- mask の品質を説明できる
- baseline が安定して動く
- IoU と失敗サンプルを分かりやすく説明できる
この4つができれば、そのプロジェクトはもうかなり「本物のプロジェクト」に近いです。
まとめ
この節で最も大事なのは、プロジェクトとしての見方を身につけることです。
分割プロジェクトの核心は、モデル学習だけではなく、mask ラベルの品質、IoU 評価、そして失敗サンプル分析にあります。
この節で必ず持ち帰りたいこと
- 分割プロジェクトは、まずデータと評価のプロジェクトであり、モデルのプロジェクトはその次
- mask アノテーションの品質は、そのまま上限を決める
- 失敗サンプルの分析は、分割プロジェクトで特に重要
一文でまとめるなら、こうです。
分割プロジェクトの本当の難しさは、モデルに mask を描かせることだけではなく、各クラス領域の境界・カバー率・誤りをきちんと説明できるようにすることです。
練習
- もう一組
pred_masksとgt_masksを作って、mean_iouがどう変わるか観察してください。 - 分割プロジェクトで mask アノテーションの基準が特に重要なのはなぜですか?
- あるクラスの対象領域がとても小さいとき、なぜ IoU は特に敏感になるのでしょうか?
- 分割プロジェクトをポートフォリオページとして見せるなら、どのように構成しますか?