10.3.4 YOLOシリーズ
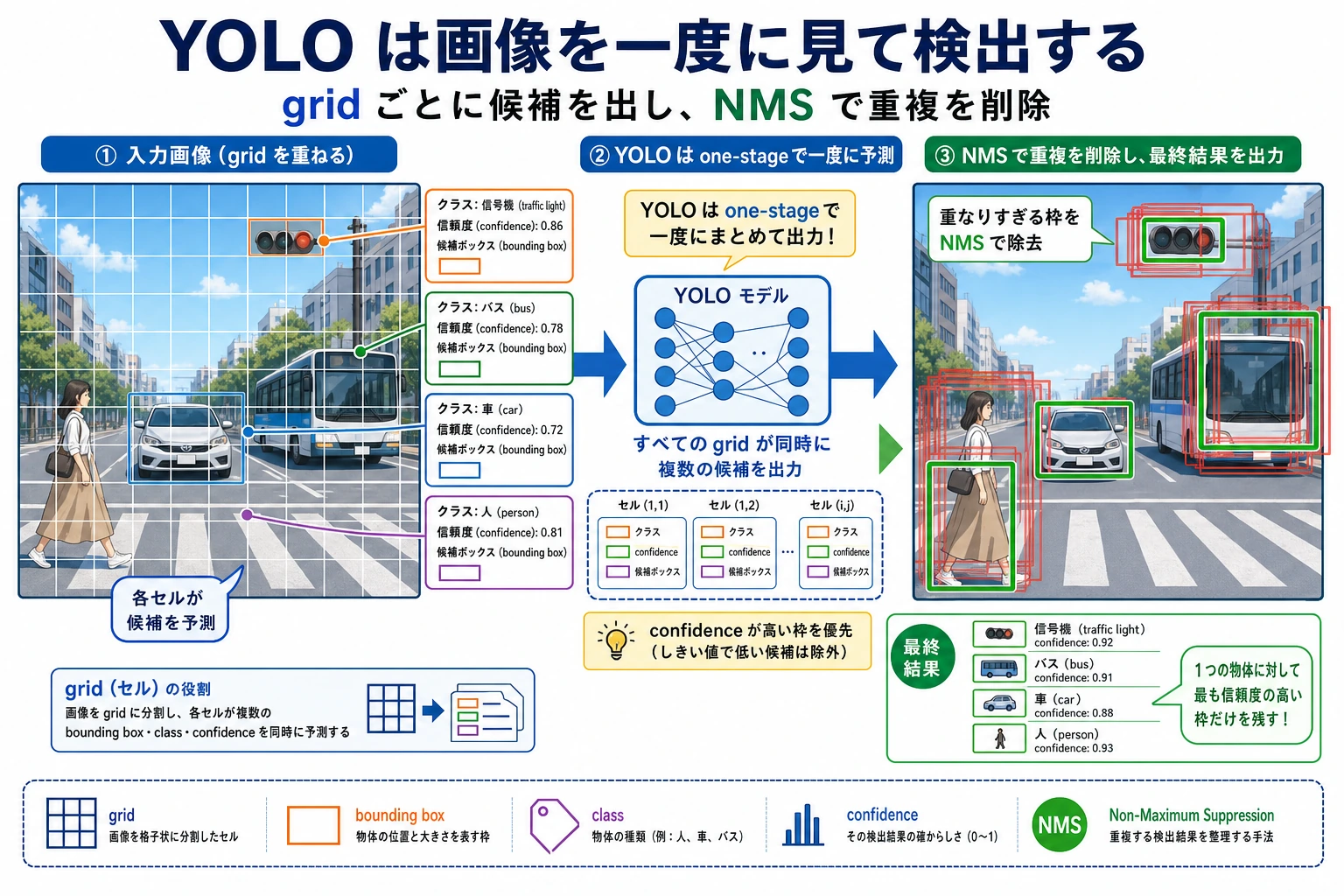
YOLO が人気なのは、物体を検出できるからだけではありません。
物体検出を、より実務で使いやすい形にしたからです。
- より速い
- より直接的
- リアルタイム場面により向いている
なので、この節で押さえるべきなのはバージョン番号ではなく、それが表しているこの流れです:
検出をできるだけ一発で終わらせる。
学習目標
- YOLO がどの種類の検出器かを理解する
- 単段階検出と二段階検出の主な違いを理解する
- 信頼度、ボックスの選別、NMS の基本的な役割を理解する
- 実務導入における YOLO の価値を判断できるようにする
一、YOLO の核心アイデアは何か?
単段階検出
YOLO がやりたいことは次の通りです:
- 2段階に分けない
- 画像から一度でクラスとボックスを直接出力する
なぜこれが魅力的なのか?
なぜなら、次のものを減らせるからです:
- 追加の proposal 段階
- より複雑な検出パイプライン
そのため、より実現しやすくなります:
- リアルタイム
たとえ話
二段階検出は、まず怪しい領域に印を付けてから、1つずつ確認するイメージです。
YOLO はもっと、一目で見渡して同時に次のことを返す感じです:
- どこに対象があるか
- それが何か
二、YOLO の出力はだいたいどんな形か?
通常は、候補ボックスの集合としてざっくり理解できます。それぞれの候補には次の情報が付きます:
- クラス
- 信頼度
- 境界ボックスの座標
その後、選別と NMS によって最終結果を得ます。
初学者向けの、もっと分かりやすいたとえ
まず YOLO を次のように考えてみましょう:
- モデルがまず画像全体を走査する
- その後、「何かありそうな場所、何っぽいか、ボックスはどこか」を一気に返す
これは二段階検出とはかなり違います。
二段階検出は次のようなイメージです:
- まずあちこちで怪しい領域を囲む
- それから各領域を細かく調べる
一方 YOLO は次のような感じです:
一通り見終わったら、候補対象をまとめて返す。
初学者が最初に覚えるとよい判断表
| 今気になっていること | まず見るとよい層 |
|---|---|
| なぜ速いのか | 単段階の流れと短い推論経路 |
| なぜたくさんボックスが出るのか | 候補ボックスの出力 |
| なぜ結果が重なるのか | NMS としきい値 |
| なぜリアルタイム案件で使われやすいのか | 実装しやすさとエコシステムの成熟度 |
この表は初心者にとても役立ちます。YOLO を「バージョン名の集合」ではなく、いくつかの具体的な問題として見られるようになるからです。
最小限の「候補ボックス出力」の例
次の例は、実際の YOLO ネットワークを再現しているわけではありません。
でも、すごく大事な感覚をつかむ助けになります:
- モデルの出力は通常「最終答え」ではない
- いくつかのスコア付き候補ボックスである
predictions = [
{"class": "person", "score": 0.93, "box": (12, 18, 80, 160)},
{"class": "person", "score": 0.87, "box": (15, 20, 82, 158)},
{"class": "dog", "score": 0.78, "box": (120, 60, 190, 150)},
]
for pred in predictions:
print(pred)
実行結果の例:
{'class': 'person', 'score': 0.93, 'box': (12, 18, 80, 160)}
{'class': 'person', 'score': 0.87, 'box': (15, 20, 82, 158)}
{'class': 'dog', 'score': 0.78, 'box': (120, 60, 190, 150)}
最初の2つのボックスはどちらも person の候補で、位置も近いです。次の NMS 例は、まさにこのような状況を処理するためのものです。
この出力でまず覚えるべきなのはフィールド名ではなく、次の点です:
- 単段階検出では、もともと候補がたくさん出やすい
- 後処理は検出フローの一部である
三、まずは最小限の NMS の直感を見てみよう
def iou(box_a, box_b):
ax1, ay1, ax2, ay2 = box_a
bx1, by1, bx2, by2 = box_b
inter_x1 = max(ax1, bx1)
inter_y1 = max(ay1, by1)
inter_x2 = min(ax2, bx2)
inter_y2 = min(ay2, by2)
inter_w = max(0, inter_x2 - inter_x1)
inter_h = max(0, inter_y2 - inter_y1)
inter_area = inter_w * inter_h
area_a = (ax2 - ax1) * (ay2 - ay1)
area_b = (bx2 - bx1) * (by2 - by1)
union = area_a + area_b - inter_area
return inter_area / union if union > 0 else 0.0
predictions = [
{"box": (10, 10, 30, 30), "score": 0.95},
{"box": (12, 12, 31, 31), "score": 0.88},
{"box": (60, 60, 90, 90), "score": 0.91},
]
def nms(preds, iou_threshold=0.5):
preds = sorted(preds, key=lambda x: x["score"], reverse=True)
kept = []
while preds:
best = preds.pop(0)
kept.append(best)
preds = [
pred for pred in preds
if iou(best["box"], pred["box"]) < iou_threshold
]
return kept
print(nms(predictions))
実行結果の例:
[{'box': (10, 10, 30, 30), 'score': 0.95}, {'box': (60, 60, 90, 90), 'score': 0.91}]
真ん中のボックスは、最高スコアの最初のボックスと大きく重なるため除外されます。3つ目のボックスは離れた場所にあるので、別の対象である可能性が高く、残されます。
この例でいちばん大事な価値は?
検出結果は、そのままではすぐに使えるとは限らない、ということです。
多くの場合、モデルは次のようなものを出します:
- 重なった候補ボックスがたくさんある
そこで NMS の役割は次の通りです:
- 代表的なものだけを残す
これはなぜ YOLO で特に重要なのか?
YOLO のような単段階の流れでは、もともと候補が多く出やすいからです。
そのため、後処理による選別は検出フローの一部になります。
最小限の「しきい値で先にふるいにかける」例
predictions = [
{"class": "person", "score": 0.93},
{"class": "person", "score": 0.48},
{"class": "dog", "score": 0.78},
]
def filter_by_score(preds, threshold=0.5):
return [pred for pred in preds if pred["score"] >= threshold]
print(filter_by_score(predictions, threshold=0.5))
実行結果の例:
[{'class': 'person', 'score': 0.93}, {'class': 'dog', 'score': 0.78}]
スコアの低い person 候補が除外されます。実際のプロジェクトでは、この閾値を変えるだけで、見逃しと誤検出のバランスが変わります。
この例は初学者にとても向いています。次のことが分かりやすいからです:
- 検出システムは、いきなり全部の候補をそのまま描画するわけではない
- まずスコアやルールで一度ふるいにかける
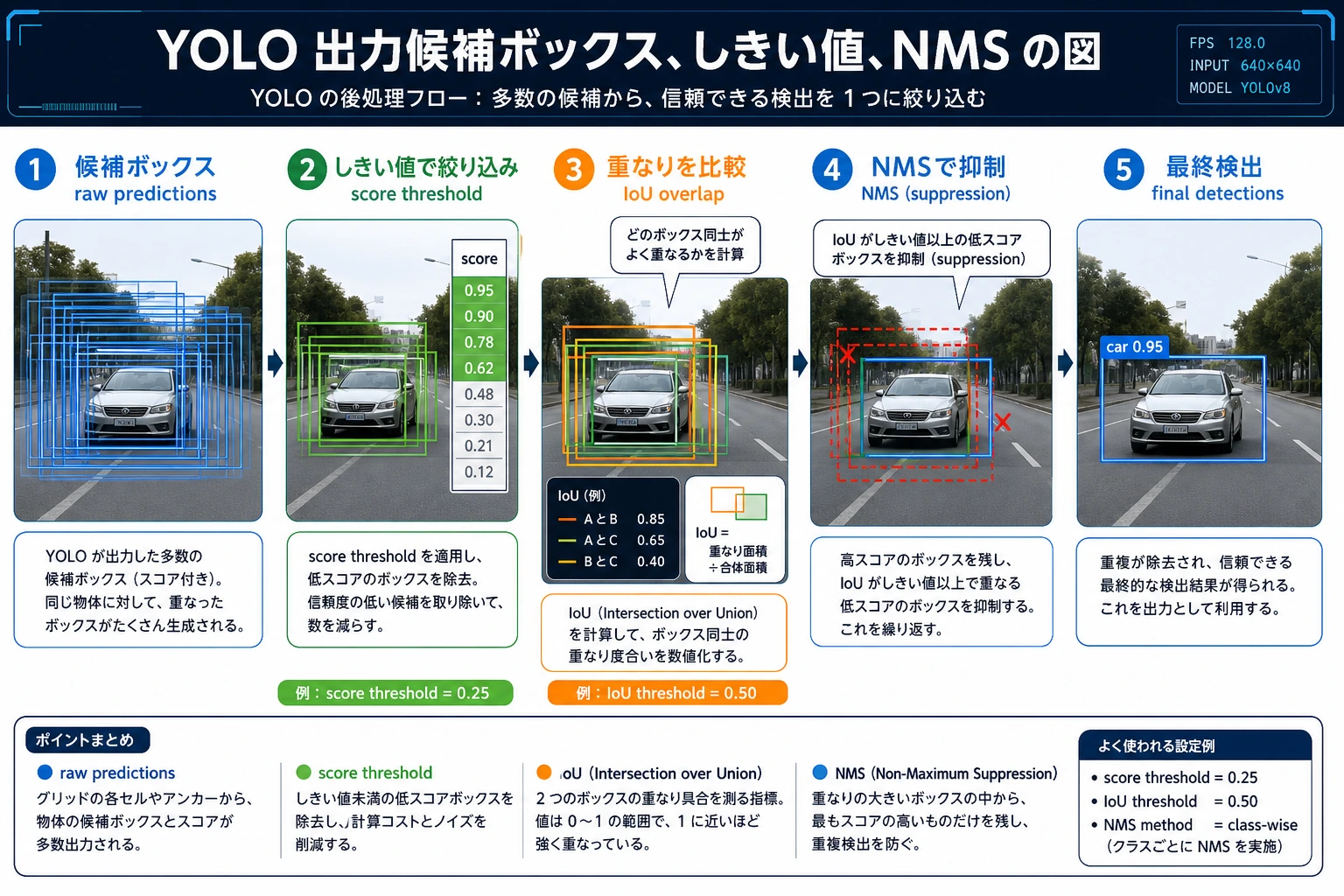
YOLO の出力は最終結果ではなく、通常は候補ボックスの集合です。図を見るときは、まず score threshold で低スコアのボックスを除外し、その後 NMS で重なったボックスをまとめ、最後に画面上で見える検出結果になります。
四、なぜ YOLO は実務でこれほど人気なのか?
リアルタイム性が高い
多くの場面では、次のような要求があります:
- カメラでリアルタイム検出したい
- エッジデバイスで素早く応答したい
YOLO のような流れは、こうしたニーズにとても向いています。
構造が比較的そろっている
多くのエンジニアにとって、複雑な多段階パイプラインよりも実装しやすいです。
コミュニティと実務エコシステムが成熟している
そのため、実際のプロジェクトで優先的に試されることが多いです。
初めてリアルタイム検出を作るとき、なぜ多くのチームが YOLO を最初に試すのか?
YOLO は、多くの場合、次の現実的な条件を同時に満たすからです:
- 始めやすい
- 推論経路が短い
- コミュニティのモデルが多い
- デプロイ資料が多い
つまり、YOLO の魅力は精度だけではなく、
次の点にあります:
実務で「まず動くもの」を早く作りやすい。
YOLO をプロジェクトに入れるなら、まず何を見せるべきか
まず見せるべきなのは、単に:
- 検出結果の画像を1枚貼ること
ではなく、次のようなものです:
- baseline の検出結果
- しきい値調整の前後比較
- NMS 前後のボックス変化
- 誤検出、見逃し、小さな対象の例
こうすると、相手に伝わりやすくなります:
- 現場の検出フローを理解している
- ただ既存モデルを呼び出しただけではない
五、よくある落とし穴
誤解1:YOLO = 物体検出
YOLO は重要な路線ですが、物体検出のすべてではありません。
誤解2:速ければ必ず最適
次の点も見る必要があります:
- 小さな対象への強さ
- ボックス位置の精度
- デプロイ上の制約
誤解3:後処理は重要ではない
NMS やしきい値設定などの後処理は、最終的な体験に直接影響します。
六、初めて YOLO プロジェクトを作るときの、いちばん安定した順番
初めて YOLO をプロジェクトに入れるなら、だいたい次の順番が安定です:
- まずクラスの境界とアノテーション規則をはっきり決める
- まずデフォルトモデルとデフォルトしきい値で baseline を出す
- まず誤検出、見逃し、小さな対象の結果を見る
- それからしきい値と NMS を調整する
- 最後に、より大きなモデルやより複雑なデータ拡張を検討する
この順番はとても重要です。初学者がやりがちなミスは次の通りだからです:
- いきなりモデルを変える
- でも baseline のどこが間違っているのかを見ていない
初学者がそのまま使える確認順
YOLO プロジェクトの結果が思わしくないとき、安定した確認順は次の通りです:
- まずクラスの境界とアノテーション規則を見る
- 次に score threshold と NMS を見る
- 次に誤検出 / 見逃しがどの対象に多いかを見る
- 最後に、より大きなモデルやより複雑な拡張を検討する
この順番のほうが、バージョン番号を直接変えるより効果的なことが多いです。
まとめ
この節でいちばん大切なのは、実務的な見方を持つことです:
YOLO は、単段階でリアルタイムに向いた検出路線を代表するものです。広く使われている理由は「検出できる」からだけではなく、「実務で素早く検出結果を出しやすい」からです。
この節で持ち帰るべきこと
- YOLO で最も重要なのはバージョン番号ではなく、単段階でリアルタイム志向の路線であること
- 出力は通常、候補ボックスの集合であり、後処理は検出フローの一部
- 初めてプロジェクトを作るときは、まず baseline の誤検出と見逃しを確認してから、モデルの更新を考える
練習
- 例の
iou_thresholdを変えて、残るボックス数がどう変わるか見てみましょう。 - 自分の言葉で説明してみましょう:なぜ単段階検出はリアルタイムにしやすいのか?
- なぜ NMS は検出タスクで重要なのか?
- 考えてみましょう:どんなときに YOLO を優先して選ばないかもしれませんか?