7.6.4 その他の PEFT 手法【選択】
前の節では、LoRA と QLoRA の主な流れを見ました。
つまり、巨大モデル全体を再学習するのではなく、少量の増分パラメータだけを学習するという考え方です。
でも、PEFT は LoRA だけではありません。実は本当に考えるべきなのは次の点です。
「学習可能な能力」をモデルのどこに置きたいのか?
- 入力側に置けば、Prompt Tuning になる
- 各層の文脈プレフィックスに置けば、Prefix Tuning になる
- 層と層の間の小さなモジュールに置けば、Adapter になる
- 中間活性のスケーリング係数に置けば、IA3 になる
この節では、これらの分岐を、実際に選択に使える地図として整理します。
学習目標
- Prompt Tuning、Prefix Tuning、Adapter、IA3 がそれぞれどこを変えるのかを理解する
- これらの手法と LoRA の本質的な違いを知る
- PEFT に関連する Adapter の最小トレーニング例を実行できるようにする
- マルチタスク、低メモリ、素早い切り替えが必要な場面での選択の感覚を身につける
一、なぜ LoRA だけが答えではないのか?
PEFT が本当に解決したいのは「略語を発明すること」ではない
PEFT の問題は、とてもシンプルです。
大きなモデル本体を凍結したまま、ごく少数のパラメータだけを学習して、モデルを新しいタスクに近づけられるか?
この目的が変わらない限り、「どの少数のパラメータを学習するか」から、自然にさまざまな変種が生まれます。
したがって、これらの手法の最大の違いは名前ではなく、次の点です。
- 学習可能なパラメータをどこに置くか
- モデルのどの情報の流れに影響するか
- 学習コスト、推論コスト、再利用性がどう違うか
たとえば、同じパソコンを軽く改造するなら?
基盤モデルを、すでにセットアップ済みのパソコンだと考えてみましょう。
- Prompt Tuning は、起動後のデスクトップに「見えない付箋」を何枚か置くようなもの
- Prefix Tuning は、各ソフトを起動する前に、あらかじめ少し文脈を差し込むようなもの
- Adapter は、マザーボードに小さな拡張カードを差し込むようなもの
- IA3 は、いくつかの重要なつまみに調整可能なゲインを追加するようなもの
どれもパソコンを丸ごと作り直すわけではなく、
異なる場所に調整可能な仕組みを足しているのです。
実際のプロジェクトで、なぜこれらの分岐が必要なのか?
というのも、工程上の制約は完全には同じではないからです。
- メモリが最重要のチームもある
- マルチタスクの素早い切り替えが最重要のチームもある
- 推論時に余計な遅さを入れたくないチームもある
- 同じ土台モデルに、たくさんの分野別アダプタを載せたいチームもある
同じ PEFT でも、最適な方法は同じとは限りません。
二、まず PEFT ファミリーの全体図を整理しよう
Prompt Tuning:学習可能な部分を入力の前に置く
Prompt Tuning の直感は次の通りです。
モデル内部の層構造は変えず、入力 embedding の前に、少しだけ学習可能な「ソフトプロンプト」をつなげる。
ここでの prompt は、自分で書く自然言語ではありません。
学習可能なベクトルの集まりです。
利点は次の通りです。
- パラメータが非常に少ない
- 実装の考え方がわかりやすい
- タスク数が多く、各タスクごとの適応をとても軽くしたい場合に向く
制限としては:
- 複雑なタスクへの変化量は大きくない
- 主に入力側に作用するため、層内の改造ほど深くはない
Prefix Tuning:各層に「プレフィックス文脈」を加える
Prefix Tuning は、Prompt Tuning をさらに一歩進めたものです。
入力の最初にベクトルを足すだけではなく、次のように考えます。
Transformer の各層の注意機構に、学習可能な key/value の前置き部分を追加する。
イメージとしては、
- Prompt Tuning は、冒頭に「タスク説明」を一文入れるようなもの
- Prefix Tuning は、各層が注意を計算するたびに、追加の文脈ヒントを見られるようにするもの
そのため、一般に Prompt Tuning より表現力が高いです。
Adapter:層と層の間に小さなモジュールを入れる
Adapter は、新規学習者にも理解しやすい手法です。
なぜなら、はっきりと「プラグインを追加する」感じに近いからです。
よくある構造は次の通りです。
- 元の隠れ状態をいったん低次元に落とす
- 中間で非線形変換を行う
- もとの次元に戻す
- 残差接続で本体に足し戻す
つまり、
本体は凍結したまま、横にとても小さな学習可能なバイパスを追加する。
工程上の利点はとても明確です。
- 元のモデル本体を大きく変更しなくてよい
- タスクごとに別の adapter を載せられる
- マルチタスクの切り替え時には、小さなモジュールだけ差し替えればよい
IA3:大きな行列は学ばず、「スケーリング係数」だけを学ぶ
IA3 の考え方は、さらに控えめです。
小さなネットワークを挿入するのではなく、チャネルごとの少数のスケーリングベクトルだけを学習する。
たとえば、注意出力やフィードフォワード層の活性に対して、
- ある次元を大きくする
- ある次元を小さくする
といった操作を行います。
つまり、
- パラメータはさらに少ない
- 学習は軽い
- ただし表現力も比較的控えめ
ということです。
4つの手法を並べて見る
| 手法 | 学習可能な部分を置く場所 | 直感 | よくある利点 | よくある制限 |
|---|---|---|---|---|
| Prompt Tuning | 入力 embedding の前 | ソフトプロンプトを入れる | パラメータが非常に少ない | 改造の強さは限られる |
| Prefix Tuning | 各層の注意機構の KV プレフィックス | 各層が追加文脈を見る | ソフトプロンプトより表現力が強い | 実装がやや複雑 |
| Adapter | 層間の小さなボトルネックモジュール | 軽量プラグインを挿す | マルチタスク切り替えがしやすい | 推論時に少し計算が増える |
| IA3 | 活性のスケーリングベクトル | 重要チャネルのゲインを調整する | パラメータが非常に少なく、実装も軽い | 複雑な変化への表現は弱め |
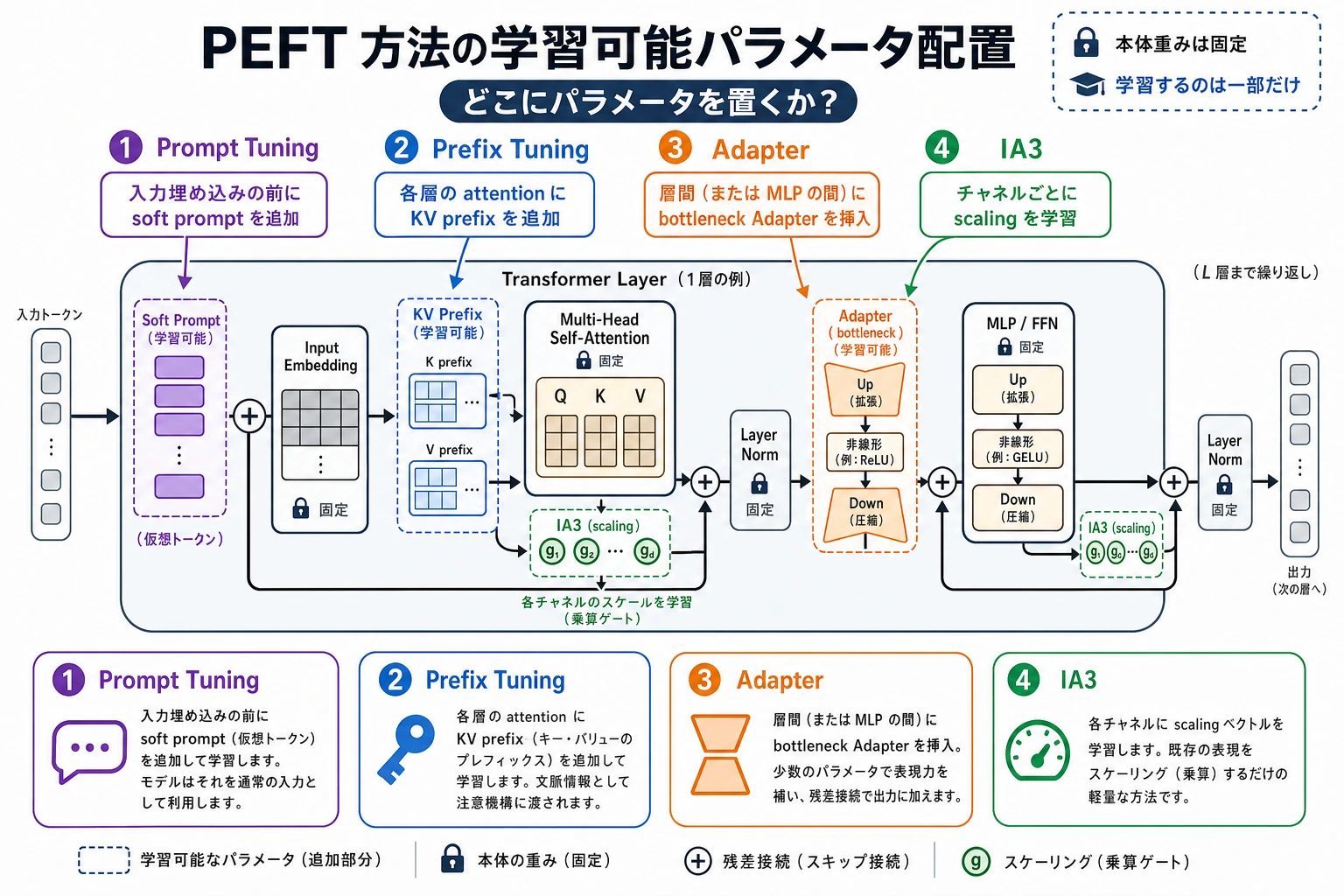
この図は、手法名で覚えるのではなく、「学習可能な部分がどこにあるか」を見るのが大切です。Prompt Tuning は入力前、Prefix Tuning は各層の注意機構の KV プレフィックス、Adapter は層間の小モジュール、IA3 はチャネルのスケーリングを調整します。場所が違えば、コスト、表現力、切り替え方も変わります。
PEFT ファミリーの小さな用語集
| 用語 | 初学者向けの説明 |
|---|---|
| PEFT | Parameter-Efficient Fine-Tuning。少数のパラメータだけを学習してモデルを適応させる方法 |
| Soft prompt | 人間が読む自然言語ではなく、学習可能なベクトル |
| KV prefix | attention が参照できる、追加の学習可能な key/value ベクトル |
| Bottleneck | パラメータ数を抑えるために、いったん低次元に落としてから戻す小さなモジュール |
| Residual connection | 小さな適応結果を元の hidden state に足し戻す接続 |
| Activation scaling | 一部の hidden dimension を、学習可能な係数で強めたり弱めたりすること |
三、まずは PEFT に本当に関係する Adapter の例を動かしてみよう
次の例でやることは、とても具体的です。
- とても小さなテキスト分類タスクを作る
- 基礎エンコーダを凍結する
- Adapter と分類ヘッドだけを学習する
これによって、次のことが直接わかります。
- 主モデルは動かしていない
- 少量のパラメータでもタスクを学習できる
pip install torch
import torch
import torch.nn as nn
torch.manual_seed(42)
samples = [
("refund my order", 0),
("need a refund", 0),
("cancel and refund", 0),
("login failed again", 1),
("cannot login account", 1),
("password login problem", 1),
]
label_names = ["refund", "login"]
vocab = {"<pad>": 0}
for text, _ in samples:
for token in text.split():
if token not in vocab:
vocab[token] = len(vocab)
max_len = max(len(text.split()) for text, _ in samples)
def encode(text):
ids = [vocab[token] for token in text.split()]
ids += [0] * (max_len - len(ids))
return ids
x = torch.tensor([encode(text) for text, _ in samples], dtype=torch.long)
y = torch.tensor([label for _, label in samples], dtype=torch.long)
class FrozenBaseEncoder(nn.Module):
def __init__(self, vocab_size, hidden_dim=16):
super().__init__()
self.embedding = nn.Embedding(vocab_size, hidden_dim)
self.proj = nn.Linear(hidden_dim, hidden_dim)
for param in self.parameters():
param.requires_grad = False
def forward(self, token_ids):
emb = self.embedding(token_ids)
mask = (token_ids != 0).unsqueeze(-1)
pooled = (emb * mask).sum(dim=1) / mask.sum(dim=1).clamp(min=1)
hidden = torch.tanh(self.proj(pooled))
return hidden
class AdapterClassifier(nn.Module):
def __init__(self, vocab_size, hidden_dim=16, bottleneck_dim=4, num_labels=2):
super().__init__()
self.base = FrozenBaseEncoder(vocab_size, hidden_dim)
self.adapter_down = nn.Linear(hidden_dim, bottleneck_dim)
self.adapter_up = nn.Linear(bottleneck_dim, hidden_dim)
self.classifier = nn.Linear(hidden_dim, num_labels)
def forward(self, token_ids):
hidden = self.base(token_ids)
adapted = hidden + self.adapter_up(torch.tanh(self.adapter_down(hidden)))
logits = self.classifier(adapted)
return logits
model = AdapterClassifier(vocab_size=len(vocab))
optimizer = torch.optim.Adam(
[p for p in model.parameters() if p.requires_grad],
lr=0.05,
)
criterion = nn.CrossEntropyLoss()
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("総パラメータ数 =", total_params)
print("学習可能パラメータ数 =", trainable_params)
for step in range(201):
logits = model(x)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
preds = logits.argmax(dim=-1)
acc = (preds == y).float().mean().item()
print(f"step={step:03d} loss={loss.item():.4f} acc={acc:.2f}")
with torch.no_grad():
preds = model(x).argmax(dim=-1)
for text, pred in zip([text for text, _ in samples], preds.tolist()):
print(f"{text:22s} -> {label_names[pred]}")
期待される出力:
総パラメータ数 = 694
学習可能パラメータ数 = 182
step=000 loss=0.7183 acc=0.50
step=050 loss=0.0000 acc=1.00
step=100 loss=0.0000 acc=1.00
step=150 loss=0.0000 acc=1.00
step=200 loss=0.0000 acc=1.00
refund my order -> refund
need a refund -> refund
cancel and refund -> refund
login failed again -> login
cannot login account -> login
password login problem -> login
このコードは何を教えているのか?
これは「本番の完全な微調整をどう作るか」を教えるものではありません。
あえて焦点を Adapter そのものに絞っています。
FrozenBaseEncoderはすべて凍結adapter_downとadapter_upが追加の小モジュールclassifierは適応後の表現をラベルに写像する
本当に大事なのはこの行です。
adapted = hidden + self.adapter_up(torch.tanh(self.adapter_down(hidden)))
これは典型的な Adapter の考え方です。
- まず主干の表現をそのまま保持する
- 横に小さなボトルネック分岐を通す
- 最後に残差として足し戻す
なぜ「手法名を表示するだけ」よりずっと良いのか?
なぜなら、次の 3 点を実際に観察できるからです。
- 学習可能パラメータがかなり少ない
- 主モデルを動かさなくてもタスクに合わせられる
- 新しい能力は、全体を再学習したのではなく、小モジュールの追加から来ている
この 3 つこそが Adapter の本質です。
四、さらに 3 つの短い構造例を見る
Prompt Tuning:入力の前にソフトプロンプトを連結する
import torch
token_embeddings = torch.randn(1, 5, 8)
soft_prompt = torch.randn(1, 3, 8, requires_grad=True)
combined = torch.cat([soft_prompt, token_embeddings], dim=1)
print("元の長さ:", token_embeddings.shape[1])
print("連結後の長さ:", combined.shape[1])
期待される出力:
元の長さ: 5
連結後の長さ: 8
ここで一番覚えてほしいのは次の点です。
- soft prompt は人間が読めるテキストではない
- それは学習されたベクトルの集合
- モデルには「追加の入力 token の embedding」として見える
Prefix Tuning:入力長ではなく、各層の注意文脈を変える
import torch
layer_keys = torch.randn(1, 4, 8)
prefix_keys = torch.randn(1, 2, 8, requires_grad=True)
all_keys = torch.cat([prefix_keys, layer_keys], dim=1)
print("注意機構の元の key 数:", layer_keys.shape[1])
print("prefix 追加後の key 数:", all_keys.shape[1])
期待される出力:
注意機構の元の key 数: 4
prefix 追加後の key 数: 6
この例の直感は次の通りです。
- 通常の注意機構は元の系列だけを見る
- Prefix Tuning では、各層の注意が学習可能な前置き文脈も見る
IA3:モジュールを足すのではなく、重要チャネルにスケールを掛ける
import torch
hidden = torch.tensor([[1.0, 2.0, 3.0, 4.0]])
gate = torch.tensor([0.5, 1.0, 1.5, 2.0], requires_grad=True)
scaled = hidden * gate
print("before:", hidden)
print("after :", scaled)
期待される出力:
before: tensor([[1., 2., 3., 4.]])
after : tensor([[0.5000, 2.0000, 4.5000, 8.0000]], grad_fn=<MulBackward0>)
IA3 の本質は「複雑にすること」ではなく、
「最も重要な場所だけを軽く調整すること」です。
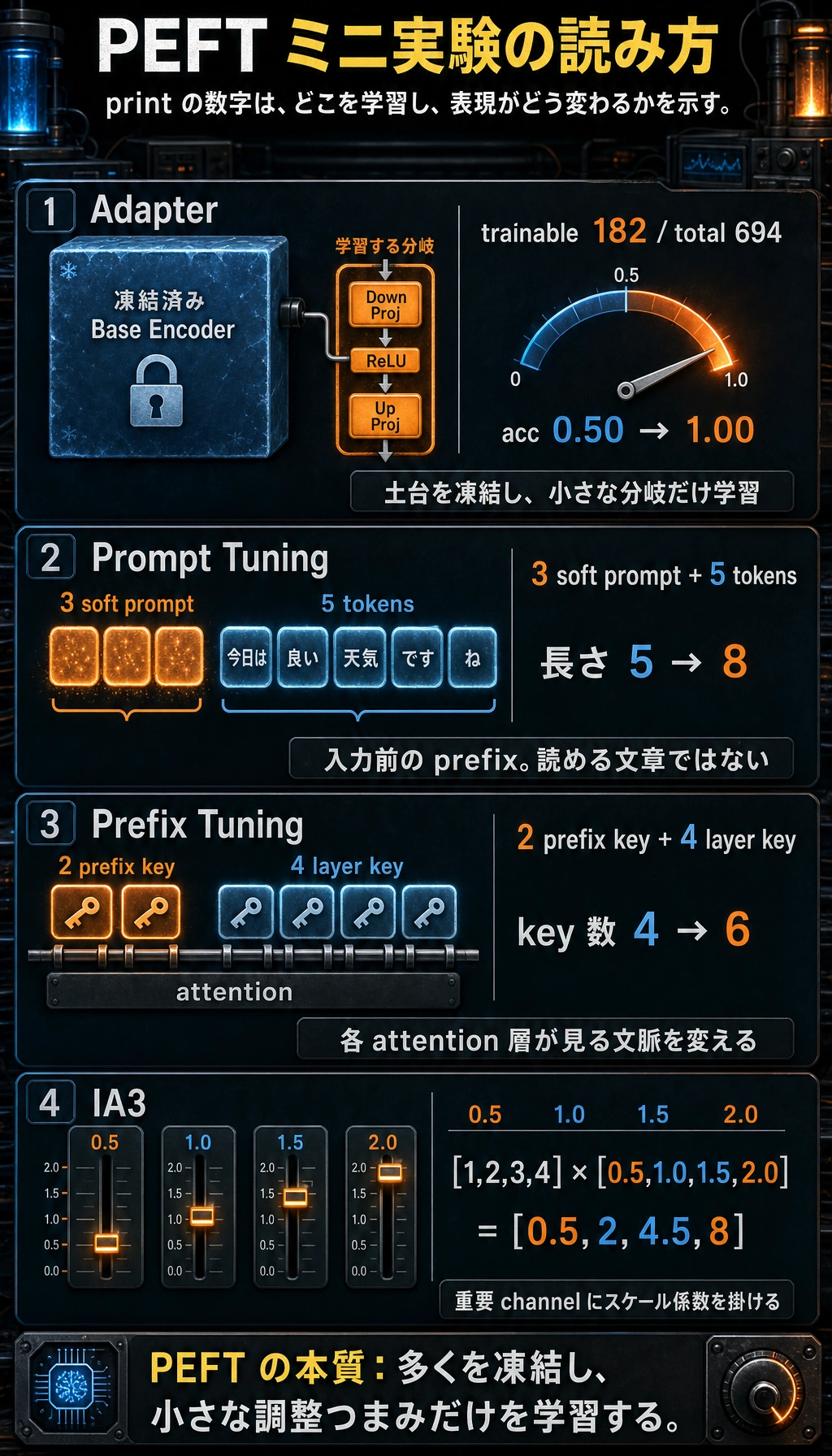
これらの短い出力は、ただの数字ではありません。Adapter は動くパラメータの少なさ、Prompt Tuning は入力長の変化、Prefix Tuning は attention key の変化、IA3 は乗算による channel 強度の変化を示します。
五、どう選べばよいのか?
タスク切り替えとモジュール性を最重視するなら
まず候補に入るのは:
- Adapter
なぜなら、自然に次のような使い方に向いているからです。
- 1 つの土台モデル
- たくさんの小さなアダプタを載せる
- タスクごとに読み込んで切り替える
パラメータをさらに少なくしたいなら
まず注目したいのは:
- Prompt Tuning
- IA3
これらはとても軽量ですが、注意点もあります。
- パラメータが少ないからといって、必ずしも性能がよいとは限らない
- タスクが複雑だと、表現力が不足することがある
もう少し深く介入したいなら
次に見るべきなのは:
- Prefix Tuning
これは入力の最初だけでなく、各層の注意が文脈を読むやり方そのものに影響するからです。
工業的に「まず試す」なら
実際には、多くのチームがまず試すのは:
- LoRA / QLoRA
その理由は単純です。
- エコシステムが成熟している
- ツールが豊富
- コミュニティの知見が多い
つまり、この節の目的は LoRA を捨てることではなく、
次のことを理解してもらうことです。
LoRA は PEFT の地図の中で最もよく使われる一部にすぎず、全部ではない。
六、よくある誤解
誤解 1:パラメータが少ないほど上位の手法である
そうとは限りません。
パラメータが少ないということは、
- 学習コストが安い
一方で、
- 表現力が制限されやすい
ということでもあります。
誤解 2:手法名をたくさん知っていれば理解できている
本当にできるようになるべきなのは、次の点です。
- どこを変えるのか
- どの情報の流れに影響するのか
- なぜ今のタスクに合っているのか
誤解 3:「学習可能モジュール」だけが重要だと思う
忘れてはいけないのは、タスクの成否は次の要素にも大きく左右されることです。
- データの品質
- テンプレートの形式
- 評価方法
- そもそも本当に微調整が必要かどうか
まとめ
この節で本当に持ち帰るべきなのは 4 つの名前ではなく、1 本の主線です。
PEFT の本質は、大きなモデル本体をできるだけ動かさず、適切な場所に少量の学習可能能力を置くことです。
これから新しい PEFT の変種に出会っても、同じ問いで分解できます。
- 学習可能なパラメータはどこに置かれているか?
- 入力、層内、層間のどこに影響するのか?
- 何の工程上の利点があり、何を犠牲にしているのか?
この 3 つが見えれば、手法名はもう神秘的ではありません。
練習
- Prompt Tuning、Prefix Tuning、Adapter、IA3 がそれぞれモデルのどの部分を変えているのか、自分の言葉で説明してみましょう。
- 1 つの土台モデルに 20 個の異なる業務タスクを適応させたいとき、なぜ Adapter が魅力的なのかを考えてみましょう。
- この節の Adapter コードで
bottleneck_dimを大きくしたり小さくしたりして、学習可能パラメータ数がどう変わるか観察してみましょう。 - もしハードウェアがかなり厳しい一方で、タスクは複雑だとしたら、どの PEFT 手法を最初に試しますか?その理由も考えてみましょう。