7.6.5 微調整工程実践
多くの微調整プロジェクトは「モデルの性能が足りない」ことが原因で失敗するのではなく、もっと前の段階でつまずきます。
- タスク定義があいまい
- データ形式が乱れている
- 学習データと検証データが漏れている
- 指標が loss しか見られていない
なので、この授業では「一番派手な方法」は扱いません。代わりに、次を説明します。
微調整プロジェクトは、開始から本番投入まで、エンジニアリング上どう進めるべきか。
学習目標
- 微調整プロジェクトの全体的な工程順序を理解する
- 生の業務データを学習サンプルに整形する方法を学ぶ
- データの分割方法、batch の設計、学習ステップ数の見積もり方を知る
- 「学習前・学習中・学習後に何を見るべきか」を確認する意識を身につける
一、微調整プロジェクトの本当の出発点は「学習開始」ではない
まずはタスクを、非常に具体的な一文で書く
多くのチームは最初にこう言います。
- カスタマーサポート用のモデルを微調整したい
でも、この言い方はかなり大きすぎます。
実際に実行できるタスク定義としては、例えば次のような形のほうがよいです。
「ユーザーの質問と注文の文脈が与えられたとき、丁寧で簡潔、かつ返金ポリシーに従った返信文を生成する。」
ここには、実はたくさんの重要情報が含まれています。
- 入力は何か
- 出力は何か
- 文体はどうするか
- 業務上の境界はどこか
この段階があいまいだと、その後のデータも指標も全部ぶれてしまいます。
まず baseline を作ってから、微調整を考える
学習を始める前に、まず次のような方法で baseline を出しておくとよいです。
- 純粋な Prompt
- Prompt + 構造化出力
- RAG
- ツール呼び出し
理由はとても現実的です。
- 微調整なしで解決できるなら、システムの複雑さを無理に上げない
- baseline がすでに強いなら、微調整の効果は小さいかもしれない
- baseline が弱いなら、微調整で何が改善されたのかが見えやすい
まず「学習サンプルの基本単位」を決める
よくある学習単位は次の 3 種類です。
- 指示-回答ペア
- 多輪対話
- 形式選好の比較サンプル
この節では主に教師あり微調整(SFT)の実践を扱うので、
もっともよく使う単位は次のようになります。
messagesprompt/completion
この決定は軽く見ないでください。後のデータクリーニングやテンプレート形式に直接影響します。
学習スクリプトに触る前に理解したい用語
| 用語 | 初学者向けの意味 | ここで重要な理由 |
|---|---|---|
| SFT | Supervised Fine-Tuning。高品質な入力と出力の例で、モデルを追加学習する方法 | この節で主に扱う微調整の形です |
messages | system、user、assistant の発話で構成されるチャット形式のサンプル | 多くの対話モデルの学習・提供形式に近い |
prompt/completion | 入力 prompt と目標回答を組にした、より単純な形式 | 単一ターンのタスクや古いデータ形式で使いやすい |
| 検証セット | 学習には使わず、効果確認のために残しておくサンプル | モデルが訓練例を覚えただけでなく、汎化しているかを見る |
| データ漏洩 | 同じ、または同じ由来のサンプルが学習と検証の両方に入ること | 検証スコアが実力以上によく見えてしまう |
二、学習前に見落とされやすい 3 つのこと
目的が不明確だと、データはどんどん乱れる
もしアノテーターが次のことを知らなければ、
- 返信は短めか、詳しめか
- 理由を積極的に説明するか
- 権限外の内容にどう対応するか
最終的なデータは、必ず文体がばらつきます。
データ漏洩は、検証データを不自然に良く見せる
とてもよくある問題は次のようなものです。
- 同じ顧客の複数の問い合わせ
- 同じ FAQ の少し言い換えたバージョン
- 同じ記事を複数の近い断片に分けたもの
これらが学習と検証の両方に入ってしまうと、
モデルの汎化が良いと勘違いしてしまいます。実際には、同じ由来のデータを覚えているだけです。
loss が下がることは、業務で使えることと同義ではない
大規模モデルでは、よく次のようなことが起こります。
- loss は下がる
- でも出力の文体が正しくない
- あるいはフォーマットが時々崩れる
- あるいは長い説明のあとでようやく答えが出る
そのため、学習曲線だけを見てはいけません。
同時に次も確認する必要があります。
- 構造化フォーマットの正答率
- 重要な業務項目の命中率
- 代表サンプルの人間による読みやすさ
三、まず生の業務データを学習サンプルに整える
次の例では、特に実用的な 3 つのことを行います。
- 生のカスタマーサポート記録を
messages形式に変換する customer_idごとにまとめて、学習データと検証データに分ける- 同じ顧客が両方にまたがらないようにする
import json
import random
random.seed(42)
raw_samples = [
{
"customer_id": "C001",
"question": "注文はすでに支払いました。返金を申請できますか?",
"answer": "返金を申請できます。まず注文ステータスをご確認ください。すでに発送済みの場合は、アフターサポートの手続きが必要です。",
},
{
"customer_id": "C001",
"question": "返金はだいたいいつ届きますか?",
"answer": "元の支払い方法への返金には通常 3〜7 営業日かかります。実際の着金時期は決済チャネルによって異なります。",
},
{
"customer_id": "C002",
"question": "パスワードを忘れました。どうすれば再ログインできますか?",
"answer": "ログインページの「パスワードを忘れた」をクリックし、SMS またはメールの案内に従って再設定してください。",
},
{
"customer_id": "C003",
"question": "お届け先住所を間違えて入力しました。変更できますか?",
"answer": "注文がまだ出庫されていない場合は、注文詳細ページで住所を変更できます。すでに出庫済みの場合は、有人カスタマーサポートへご連絡ください。",
},
{
"customer_id": "C004",
"question": "請求書はいつ発行できますか?",
"answer": "注文完了後に請求書センターから発行を申請できます。電子請求書は登録済みメールアドレスに送信されます。",
},
]
def to_chat_record(row):
system_prompt = "あなたは EC サポートのアシスタントです。丁寧で正確、かつプラットフォームのポリシーに合った返信をしてください。"
return {
"customer_id": row["customer_id"],
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": row["question"]},
{"role": "assistant", "content": row["answer"]},
],
}
def split_by_customer(records, train_ratio=0.8):
customer_ids = sorted({row["customer_id"] for row in records})
random.shuffle(customer_ids)
split_point = max(1, int(len(customer_ids) * train_ratio))
train_ids = set(customer_ids[:split_point])
train_records = [row for row in records if row["customer_id"] in train_ids]
val_records = [row for row in records if row["customer_id"] not in train_ids]
return train_records, val_records
chat_records = [to_chat_record(row) for row in raw_samples]
train_records, val_records = split_by_customer(chat_records)
print("train size =", len(train_records))
print("val size =", len(val_records))
print("first train example:")
print(json.dumps(train_records[0], ensure_ascii=False, indent=2))
期待される出力:
train size = 3
val size = 2
first train example:
{
"customer_id": "C002",
"messages": [
{
"role": "system",
"content": "あなたは EC サポートのアシスタントです。丁寧で正確、かつプラットフォームのポリシーに合った返信をしてください。"
},
{
"role": "user",
"content": "パスワードを忘れました。どうすれば再ログインできますか?"
},
{
"role": "assistant",
"content": "ログインページの「パスワードを忘れた」をクリックし、SMS またはメールの案内に従って再設定してください。"
}
]
}
このコードにどんな実務上の価値があるのか?
なぜなら、これは微調整の最初の本当に現実的な一歩だからです。
- 生データは通常、学習用の形式ではない
- まずモデルが読める構造に整える必要がある
- 分割時には、同じ由来の漏れを避ける必要がある
多くのプロジェクトは、学習方法が間違っているのではなく、
この段階からすでに地雷を埋めてしまっています。
なぜランダム分割ではなく、顧客単位で分けるのか?
ランダム分割だと、同じ顧客の異なる質問が学習と検証の両方に入ってしまう可能性が高いからです。
その結果、
- 検証スコアが見た目よくなる
- でも実際には汎化性能を過大評価している
となります。
そのため、分割単位はできるだけ実際の汎化境界に近づけるのが基本です。例えば次のような単位です。
- ユーザー
- 会話
- 文書
- 問い合わせチケット
- 製品ライン
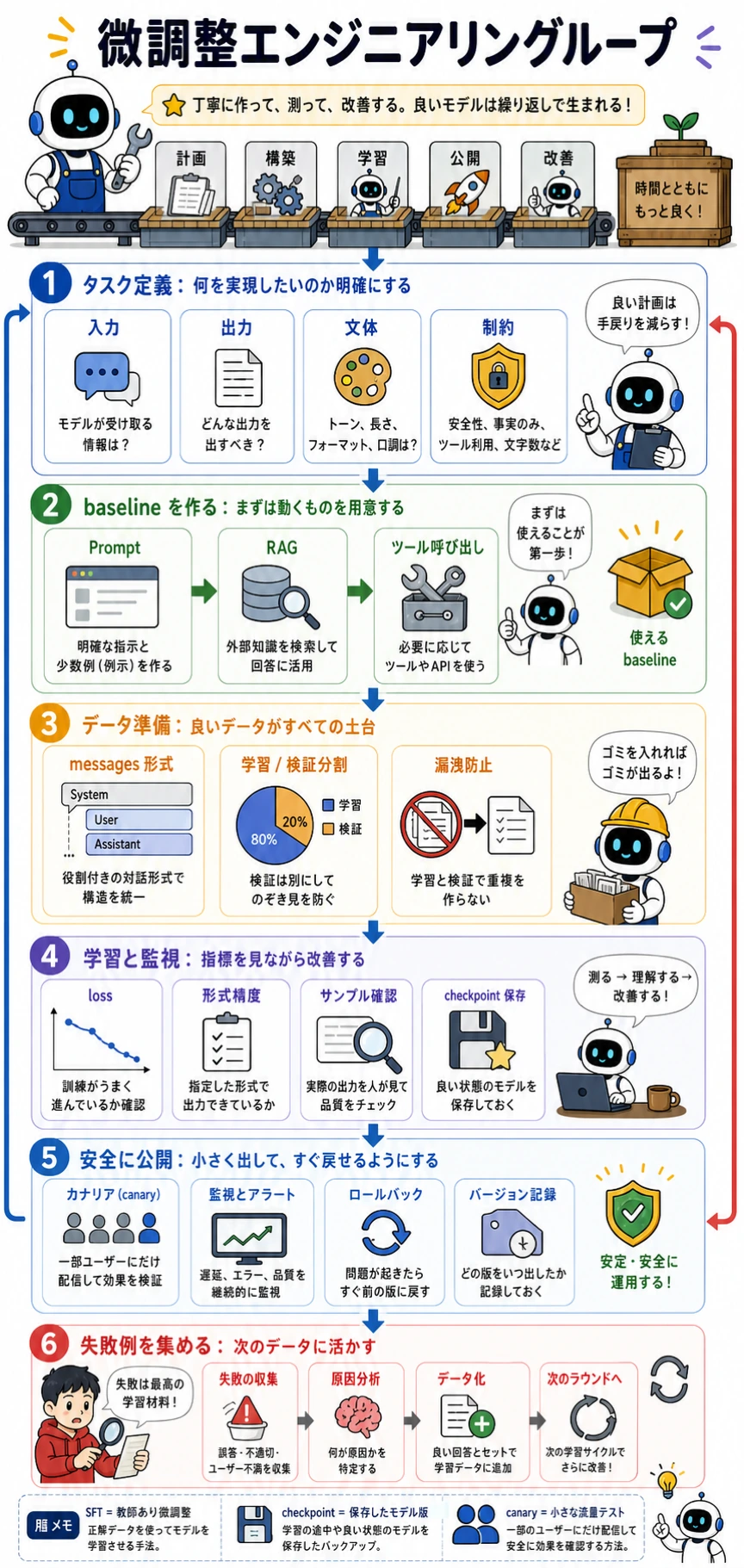
この図は「学習ボタンを押せば魔法のように良くなる」という話ではなく、工程ラインとして読んでください。健全な微調整プロジェクトは、タスク定義と baseline から始まり、漏洩のないデータを準備し、監視しながら学習し、カナリアとロールバックで安全に公開し、失敗例を次のデータに戻します。
四、学習形式は「会話っぽく見える」だけでは不十分
SFT では、通常 assistant 部分だけを学習対象にしたい
これは次のように呼ばれます。
- assistant-only loss
意味は次の通りです。
systemuser
これらは条件入力であり、学習目標として「丸暗記」させるべきではありません。
次の小さな関数は、その mask の考え方を簡単に示したものです。
messages = [
{"role": "system", "content": "あなたはカスタマーサポートのアシスタントです"},
{"role": "user", "content": "パスワードを忘れたときはどうすればいいですか"},
{"role": "assistant", "content": "「パスワードを忘れた」から再設定してください"},
]
def build_loss_mask(messages):
mask = []
for message in messages:
token_count = len(message["content"].split())
value = 1 if message["role"] == "assistant" else 0
mask.extend([value] * token_count)
return mask
print(build_loss_mask(messages))
期待される出力:
[0, 0, 1]
これは本物の tokenizer を再現しているわけではありません。
あくまで、次を理解しやすくするためのものです。
学習時は、すべての token を一緒に loss 計算するわけではない。
実際の SFT パイプラインでは、tokenizer が messages を token ID に変換し、trainer が label mask を作ることがよくあります。system と user の token は条件入力であり、モデルにタスクと文脈を伝えます。一方で assistant の token が、学習すべき目標の振る舞いです。assistant-only loss は、ユーザー質問の丸暗記ではなく「どう答えるか」を学ばせるための考え方です。
形式ルールが不安定だと、モデルは「汚いパターン」を覚える
例えば同じタスクなのに、
- あるサンプルは
messages - あるサンプルは
question/answer - あるサンプルは assistant が最初に長々と挨拶する
- あるサンプルはすぐ答えだけを返す
という状態だと、モデルは安定した振る舞いを学びにくくなります。
だから、形式の統一が非常に重要です。
- フィールドを統一する
- role の順序を統一する
- 文体を統一する
- 終了の仕方を統一する
五、学習計画は、学習開始前に計算しておく
学習を始めてから次のようなことに気づく人は多いです。
- batch が小さすぎる
- steps が少なすぎる
- warmup が変
- checkpoint の保存が細かすぎる、または粗すぎる
次のスクリプトを使えば、学習規模を先に見積もれます。
from math import ceil
def build_training_plan(
num_train_examples,
micro_batch_size,
gradient_accumulation,
epochs,
num_gpus=1,
warmup_ratio=0.03,
):
effective_batch_size = micro_batch_size * gradient_accumulation * num_gpus
steps_per_epoch = ceil(num_train_examples / effective_batch_size)
total_steps = steps_per_epoch * epochs
warmup_steps = max(1, int(total_steps * warmup_ratio))
return {
"effective_batch_size": effective_batch_size,
"steps_per_epoch": steps_per_epoch,
"total_steps": total_steps,
"warmup_steps": warmup_steps,
}
plan = build_training_plan(
num_train_examples=3200,
micro_batch_size=4,
gradient_accumulation=8,
epochs=3,
num_gpus=1,
)
print(plan)
val_history = [
{"checkpoint": 100, "val_loss": 1.82, "format_acc": 0.61},
{"checkpoint": 200, "val_loss": 1.35, "format_acc": 0.78},
{"checkpoint": 300, "val_loss": 1.31, "format_acc": 0.74},
]
best = min(val_history, key=lambda item: (item["val_loss"], -item["format_acc"]))
print("best checkpoint =", best)
期待される出力:
{'effective_batch_size': 32, 'steps_per_epoch': 100, 'total_steps': 300, 'warmup_steps': 9}
best checkpoint = {'checkpoint': 300, 'val_loss': 1.31, 'format_acc': 0.74}
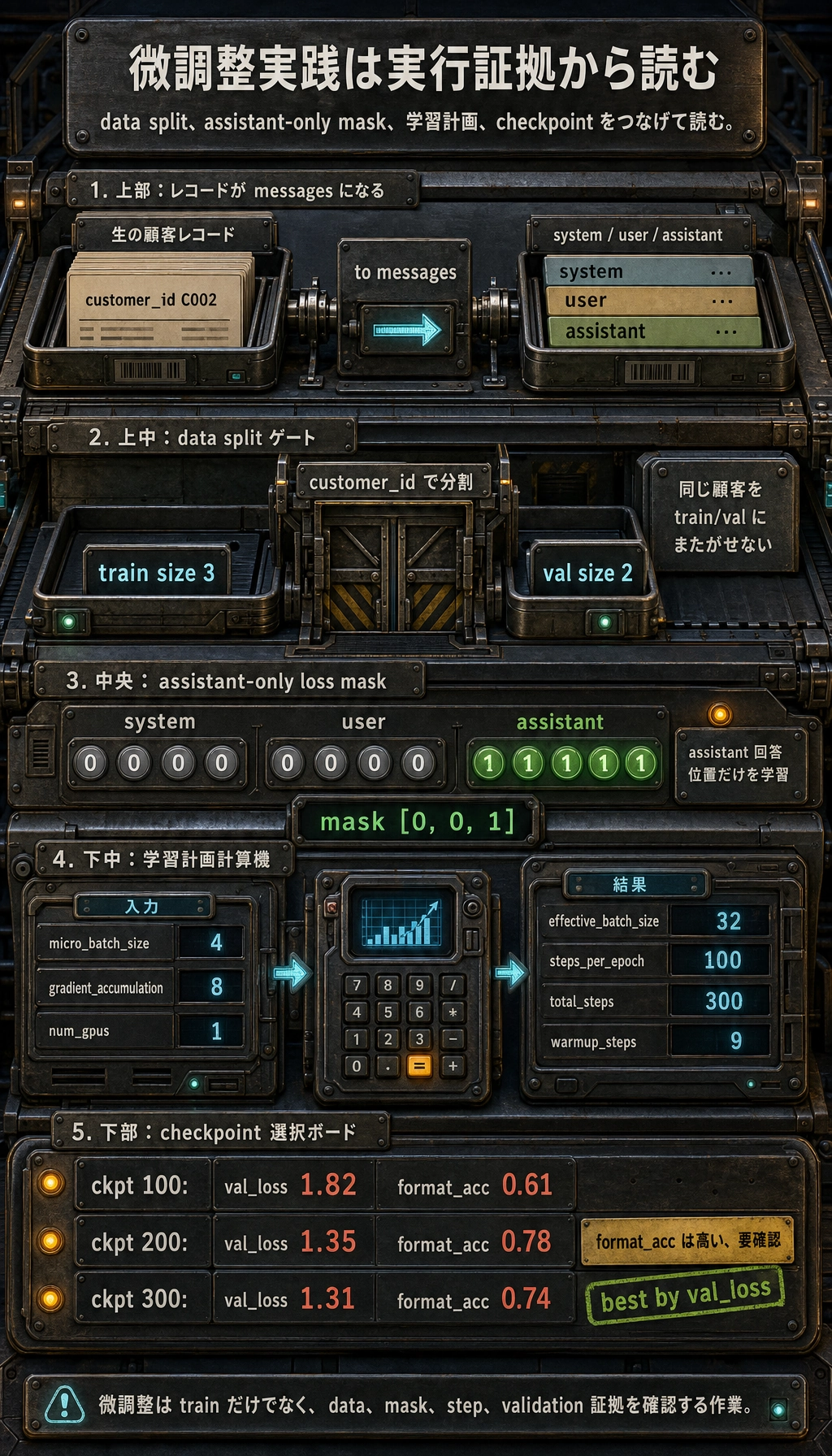
なぜ effective batch size を特に気にするのか?
実際に 1 回のパラメータ更新で見ているサンプル数は、
単なる 1 枚の GPU の batch size ではありません。
次の掛け算になります。
micro_batch_size * gradient_accumulation * GPU 数
これは直接、次の項目に影響します。
- 勾配の安定性
- 学習率の選び方
- 総学習ステップ数
なぜ検証時に val_loss だけ見てはいけないのか?
業務タスクでは、もっと重要な指標があることが多いからです。例えば、
- JSON 形式の正確さ
- 分類ラベルの正解率
- 重要情報の再現率
- 人手による満足度
そのため、ベスト checkpoint を保存するときは、
少なくとも次の両方を見るのが普通です。
- 一般的な学習指標
- 業務指標
読み間違えやすい学習計画の用語
| 用語 | 意味 | プロジェクトへの影響 |
|---|---|---|
| Micro batch size | 1 台のデバイスが 1 回の小さな forward/backward で処理するサンプル数 | 主に GPU メモリで制限される |
| Gradient accumulation | 複数の micro batch の勾配をためてから、1 回だけ optimizer を更新する方法 | メモリが限られていても、より大きな batch を疑似的に使える |
| Effective batch size | micro_batch_size * gradient_accumulation * GPU 数 | 学習率の選び方や勾配の安定性に影響する |
| Warmup steps | 学習初期に learning rate を少しずつ上げるステップ数 | 学習開始直後の不安定さを減らす |
| Checkpoint | ある学習ステップで保存したモデル状態 | バージョン比較、再開、ロールバックに使える |
| Canary traffic | 新モデルへ少量の本番トラフィックだけを先に流すこと | 全面公開前にリスクを下げられる |
六、学習中は何を監視すべきか?
第 1 層: 曲線に明らかな異常がないか
例えば次のようなものです。
- loss がまったく下がらない
- 最初から発散する
- 学習率スケジューラがおかしい
- 検証データが急に悪化する
これらは「まず火を消す」レベルの問題です。
第 2 層: モデルの出力が変な方向にずれていないか
固定した 20〜50 件のサンプルを抽出して、
各 checkpoint ごとに出力を見ます。
特に見る点は次の通りです。
- くどくなりすぎていないか
- 変な内容を作り始めていないか
- 形式が安定しているか
- 元の基本能力を忘れていないか
第 3 層: 過学習や catastrophic forgetting が起きていないか
よくあるのは次のような状況です。
- 学習データの性能はどんどん良くなる
- 検証データの改善が止まる
- もともとできていた一般能力が逆に悪くなる
これは多くの場合、次を意味します。
- データ分布が狭すぎる
- 学習回数が多すぎる
- 学習率が高すぎる
- サンプルの文体が単一すぎる
Catastrophic forgetting とは、狭い微調整タスクでは良くなった一方で、もともと持っていた広い能力の一部を失うことです。簡単な検出方法は、要約、推論、コード、安全境界などの小さな「汎用能力チェックセット」を残し、重要な checkpoint ごとにタスク検証セットと一緒に実行することです。
七、本番投入前に補うべき最後の層
オフライン評価に通っても、そのまま本番投入してはいけない
本当に本番へ出す前には、少なくとも次を準備します。
- カナリアリリース
- 人手による抜き取り確認
- ロールバック手順
- バージョン記録
本番で記録すべきなのは、リクエストログだけではない
次のことも重要です。
- どの種類の問題が改善したか
- どの種類の問題が悪化したか
- 新しいエラーはどの入力タイプに集中しているか
これらはそのまま、次回のデータ追加の元になります。
微調整プロジェクトは「1 回の学習」ではなく、継続的な反復の流れである
最も健全なループは、だいたい次の通りです。
- タスクを明確にする
- データを準備する
- baseline を回す
- 学習と検証を行う
- カナリアリリースする
- 失敗サンプルを集める
- 次の改善に進む
八、もっともよくある誤解
誤解 1: いきなり学習パラメータを決める
先にパラメータを決めるのは、もっとも重要なタスク定義とデータ整理を飛ばしてしまうことが多いです。
誤解 2: データは多ければ多いほどよい
実際には、次のほうが重要なことが多いです。
- タスクに合っているか
- 文体が一貫しているか
- 代表性があるか
誤解 3: 学習が終わったら、プロジェクトも終わり
本当の実務では、
学習完了はゴールではなく、途中の節目です。
まとめ
この節で最も大事なのは、ある設定ファイルの形を覚えることではありません。
代わりに、安定した順序を作ることです。
まずタスクをはっきり書く。次にデータを正しく整える。さらに分割と学習計画をきちんと見積もる。最後に、loss だけでなく業務指標でバージョンを判断する。
この順番が安定していれば、
あとでモデルを変えても、フレームワークを変えても、微調整方法を変えても、エンジニアリング上の判断はぶれません。
練習
- 手元にある実際の業務タスクを、「入力-出力-文体-制約」がもっと具体的に分かる一文に書き直してみましょう。
- この節のコードを参考に、手元の生の QA データを
messages形式に整えてみましょう。 - あなたのデータは、ユーザー単位、会話単位、それとも文書単位で分割すべきでしょうか? なぜですか?
- 検証データの
val_lossは低いのに、JSON 形式の正確さが悪い場合、どの checkpoint を選びますか? その理由は何ですか?