7.6.6 データラベリングとデータフライホイール
モデルの性能上限は、学習テクニックではなくデータによって決まることがよくあります。
特に大規模モデルの微調整では、よくある問題は次のようなものではありません。
- 手法が新しくない
むしろ、次のような点です。
- ラベリング基準が不一致
- 正例と負例の境界があいまい
- オンラインで失敗したサンプルが戻ってこない
この節で解決したいのは、より根本的な問題です。
「データがどんどん良くなる」ことを、継続的に回るフライホイールにするにはどうするか。
学習目標
- ラベリングは単に「タグを付ける」ことではなく、タスクの境界を定義することだと理解する
- ラベル体系、ラベリング規約、品質チェックの流れをどう設計するかを知る
- 一致率指標と難例の選別を使ってデータ品質を確認する方法を学ぶ
- データフライホイールが、オンラインの失敗サンプルを次の学習資産に変える仕組みを理解する
一、なぜ「データラベリング」は本質的にタスク定義なのか?
ラベルは事務作業ではなく、プロダクト判断
たとえば、あなたのタスクが「カスタマーサポート返信品質の分類」だとします。
ラベラーにラベル名だけを渡したとします。
- 良い返信
- 悪い返信
この場合、各人の中の基準はばらばらです。
- 丁寧さを見る人
- 問題を解決できているかを見る人
- ポリシーに合っているかを見る人
最後にモデルが学ぶのは、混ざった基準の寄せ集めになってしまいます。
だから、ラベルが本当に答えるべきなのは次のことです。
- 何を正解とするか
- 何を誤りとするか
- 境界ケースをどう判定するか
たとえ話:モデルはラベル名を学ぶのではなく、その背後のルールを学ぶ
各ラベル付きデータは、次のように考えられます。
- 人間が裁定した1つのケース
モデルが見ているのは「safe/unsafe」という文字そのものではなく、
大量のケースを通して暗黙的に表現された判断基準です。
そのため、ルール自体があいまいなら、
モデルもはっきり学ぶことはできません。
なぜ多くの微調整プロジェクトがここで詰まるのか?
チームはしばしば「ラベル名」の明確さを過大評価し、
「ラベリング規約」の重要性を過小評価するからです。
本当にデータ品質を安定して上げるものは、ラベリングツールそのものではなく、むしろ次のようなものです。
- ラベル定義
- 正例と反例
- 境界例
- レビューの仕組み
二、まずラベル体系をきちんと設計する
ラベルはできるだけ業務アクションに対応させる
良いラベル体系は、後続のアクションに自然につながるのが理想です。
たとえば、カスタマーサポートの審査タスクでは、
単に次のように分けるよりも、
- 良い
- 悪い
次のようなラベルのほうが実用的です。
correct_and_politecorrect_but_too_briefpolicy_violationhallucinated_promise
このようなラベルは、次のような用途に役立ちます。
- エラー分析
- データ追加
- ターゲットを絞った微調整
境界サンプルは必ず個別にルールを書く
初心者が見落としやすいのは次のようなケースです。
- 明らかな正例
- 明らかな負例
これらは通常、ラベル付けが難しくありません。
本当に難しいのは次のようなケースです。
- 一部は正しい
- 丁寧な言い回しだが事実が間違っている
- 拒否の方向性は正しいが、表現がぶっきらぼう
こうした境界例をはっきり書かないと、
一貫性は必ず下がります。
いつ分類ラベルにするべきか、いつペア比較にするべきか?
タスクの重点が次のような場合は、
- 明確なカテゴリ
- 違反かどうかが明確
分類ラベルのほうが自然です。
タスクの重点が次のような場合は、
- 2つの回答のどちらが良いか
- どちらのスタイルが期待に合うか
ペア比較のほうが安定しやすいです。
つまり、
- 分類は「絶対基準」に向いている
- 比較は「相対的な優劣」に向いている
三、まず本当に役立つデータ品質チェックのスクリプトを動かす
以下のコードは、実務でよく行う3つのことをします。
- 2人のラベラーの一致率を計算する
- Cohen's kappa を計算する
- 次のレビューや追加ラベル付けに回すべきサンプルを見つける
from collections import Counter
records = [
{
"id": 1,
"text": "パスワードをリセットしてから、もう一度ログインしてみてください。",
"label_a": "good",
"label_b": "good",
"model_confidence": 0.93,
},
{
"id": 2,
"text": "自分で調べてください。",
"label_a": "bad",
"label_b": "bad",
"model_confidence": 0.91,
},
{
"id": 3,
"text": "すでに発送済みでも必ず即時返金できます。",
"label_a": "bad",
"label_b": "good",
"model_confidence": 0.52,
},
{
"id": 4,
"text": "注文完了後は請求書センターで請求書発行を申請できます。",
"label_a": "good",
"label_b": "good",
"model_confidence": 0.51,
},
{
"id": 5,
"text": "住所変更に対応しているかは不明です。有人カスタマーサポートに確認することをおすすめします。",
"label_a": "good",
"label_b": "bad",
"model_confidence": 0.47,
},
]
def agreement_rate(labels_a, labels_b):
matches = sum(a == b for a, b in zip(labels_a, labels_b))
return matches / len(labels_a)
def cohens_kappa(labels_a, labels_b):
n = len(labels_a)
observed = agreement_rate(labels_a, labels_b)
counter_a = Counter(labels_a)
counter_b = Counter(labels_b)
all_labels = sorted(set(labels_a) | set(labels_b))
expected = sum(
(counter_a[label] / n) * (counter_b[label] / n)
for label in all_labels
)
if expected == 1:
return 1.0
return (observed - expected) / (1 - expected)
labels_a = [row["label_a"] for row in records]
labels_b = [row["label_b"] for row in records]
print("agreement =", round(agreement_rate(labels_a, labels_b), 3))
print("kappa =", round(cohens_kappa(labels_a, labels_b), 3))
needs_review = [
row for row in records
if row["label_a"] != row["label_b"] or row["model_confidence"] < 0.6
]
needs_review = sorted(needs_review, key=lambda row: row["model_confidence"])
print("\nreview queue:")
for row in needs_review:
print(
f"id={row['id']} confidence={row['model_confidence']:.2f} "
f"labels=({row['label_a']}, {row['label_b']}) text={row['text']}"
)
期待される出力:
agreement = 0.6
kappa = 0.167
review queue:
id=5 confidence=0.47 labels=(good, bad) text=住所変更に対応しているかは不明です。有人カスタマーサポートに確認することをおすすめします。
id=4 confidence=0.51 labels=(good, good) text=注文完了後は請求書センターで請求書発行を申請できます。
id=3 confidence=0.52 labels=(bad, good) text=すでに発送済みでも必ず即時返金できます。
なぜこのコードは「無駄な例」ではないのか?
それは、データチームが毎日やっている3つの作業に対応しているからです。
- ラベラーが一致しているかを見る
- モデルがどのサンプルで最も不確実かを見る
- 争いのあるサンプルを取り出して重点的に再確認する
総サンプル数だけを見て、これらを見なければ、
データ品質は表面的なままになりやすいです。
なぜ agreement だけでは不十分なのか?
カテゴリが非常に不均衡なことがあるからです。
たとえば、サンプルの90%が good だとすると、
2人のラベラーがかなり手を抜いていても、一見かなり高い一致率になります。
そのため、多くのチームは次も確認します。
- Cohen's kappa
これは「たまたま一致した分」を差し引こうとする指標です。
なぜ低信頼度のサンプルをレビューキューに入れるのか?
こうしたサンプルは、次のいずれかを意味していることが多いからです。
- モデルが自信を持てない
- ルール境界があいまい
- あるいはサンプル自体が汚れている
こうしたものこそ、次のラウンドで最もデータ価値が高い部分です。
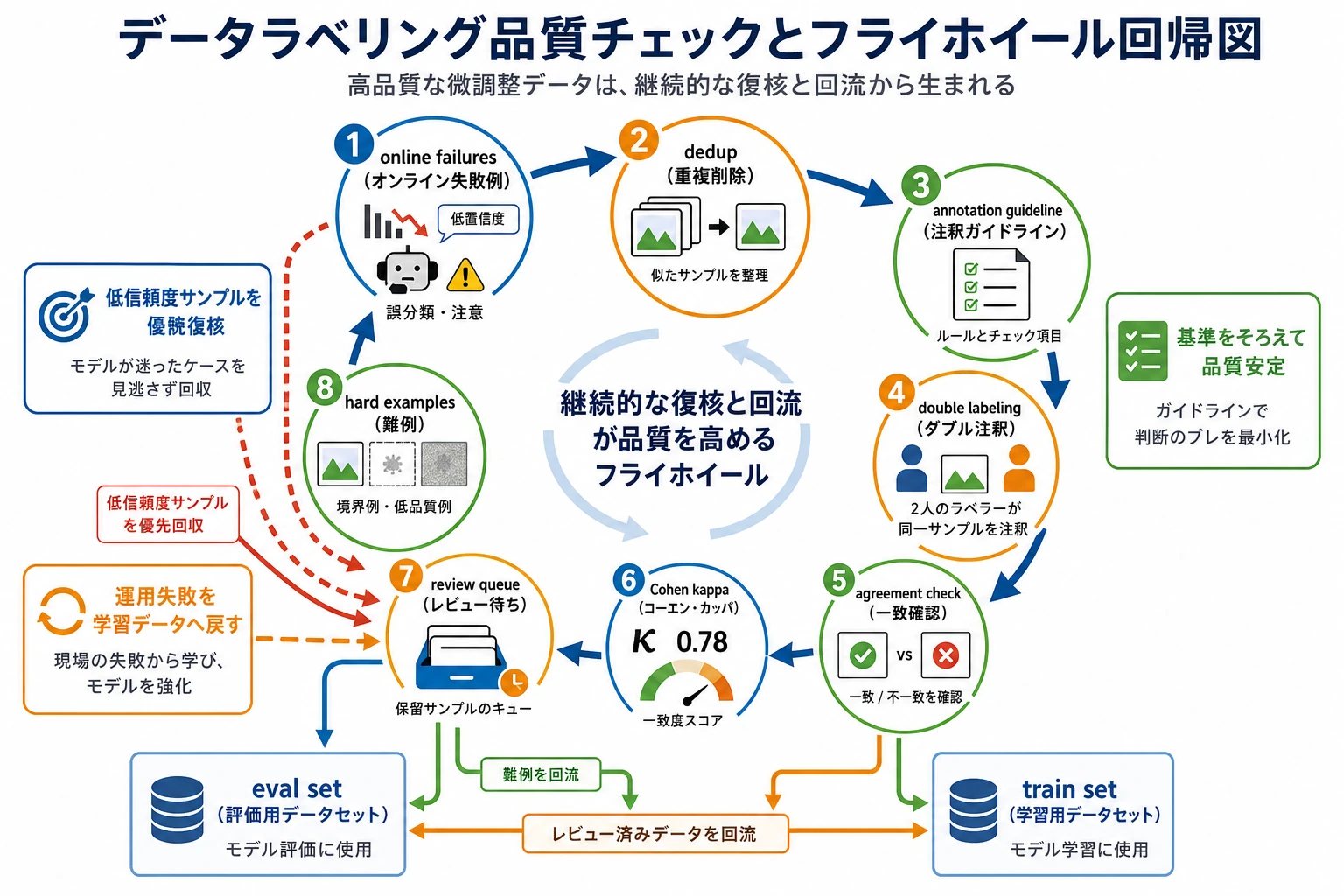
この図はまず review queue を見るのがおすすめです。ラベラーの不一致、モデルの低信頼度、オンライン失敗サンプルはいずれもレビューに回し、その後、次のラウンドで価値の高い学習データに変えるべきです。データフライホイールは「サンプルをたくさん集める」ことではなく、境界を最もよくあぶり出す問題を継続的に戻すことです。
四、「データフライホイール」とは何か?
最小の閉ループはどんな形か?
典型的なデータフライホイールは、通常次の流れです。
- モデルを本番に出す
- 失敗サンプルを集める
- クリーニングと重複排除をする
- 再ラベル付け、または追加ラベル付けをする
- 次の学習データセットに入れる
- 再評価して、再度本番に出す
フライホイールのポイントは「循環」そのものではなく、
毎回戻ってくるデータがより実際の問題に近づくことです。
なぜオンラインの失敗サンプルは特に価値が高いのか?
それらには、次の2つの特徴があることが多いからです。
- 実際のユーザー由来である
- 現在のシステムの最も弱い部分をちょうど突いている
人が何となく作ったサンプルと比べると、
こちらのほうがはるかに狙いが明確です。
フライホイールで一番怖いのは何か?
次の3つが特に怖いです。
- 失敗サンプルを集められない
- 集めても原因分類しない
- 原因分類しても次の学習や評価に入らない
集めるだけで戻さないなら、
それはフライホイールではなく、ただの滞留です。
五、どうすればフライホイールをより安定させられるか?
まず失敗タイプごとに分ける
オンライン問題をいくつかに分けるだけでも、単にサンプルを積み上げるより効果的なことがよくあります。
たとえば、次のように分けます。
- フォーマットエラー
- 幻覚
- ポリシー違反
- 過剰な拒否
- 必須フィールドの欠落
こうすると、次のラウンドでどの種類のデータを補うべきかがわかります。
次に重複排除と代表サンプリングを行う
実際のオンラインデータは、重複しやすいです。
ユーザーが同じ種類の質問を何度もするなら、すべてのサンプルを機械的に学習データへ戻すべきではありません。
より良い方法は、通常次のとおりです。
- ほぼ重複するものを除く
- 代表的なサンプルを残す
- レアだが高リスクな問題を優先する
バージョン管理も忘れない
各ラウンドのデータについて、次をきちんと記録しておくのが理想です。
- どこから来たか
- なぜ追加したか
- どの種類のエラーか
- すでに人手で確認したか
そうしないと、あとで次のような質問に答えにくくなります。
今回の改善は、手法が変わったからなのか、それともデータが変わったからなのか?
六、ラベリング規約はどこまで詳しく書くべきか?
少なくとも正例、反例、境界例が必要
良い規約には、少なくとも次が含まれます。
- ラベル定義
- 適用条件
- 明確な正例
- 明確な反例
- 混同しやすい境界例
できれば「なぜ」も答えられるようにする
規約に次のようにしか書かれていないとします。
- この場合は
badを付ける
でも理由が書かれていないと、
ラベラーは似ているが完全には同じでないケースに出会ったときに迷います。
規約そのものも改善していく
プロジェクトが進むにつれて、必ず次のようなことが見えてきます。
- 古いルールではカバーできない新しいケース
- 元のラベルが粗すぎる
- 2つのラベルが混同されやすい
このときに更新すべきなのは、データだけではありません。
規約そのものも更新する必要があります。
七、特に陥りやすい誤解
誤解1:先に大量にラベル付けして、ルールは後で考える
ルールが固まっていないのに大規模にラベル付けを始めると、
やり直しが非常に多くなりがちです。
誤解2:一致率だけを見て、争いの原因を見ない
一致率が低いのは表面上の結果です。
本当に重要なのは次のどれかを知ることです。
- 規約があいまい
- サンプルが汚れている
- そもそもラベル体系が不合理
誤解3:フライホイールを「もっとデータを増やし続けること」だと思う
フライホイールは、単純に量を積むことではありません。
最も価値の高い失敗サンプルを、質の高い学習資産に変え続けることです。
まとめ
この節で最も重要な結論は次のとおりです。
データラベリングは微調整前の雑務ではなく、タスク定義、品質管理、継続改善能力の中核である。
本当に生命力のあるデータ体系には、通常次の3つがそろっています。
- ルールが明確
- 品質チェックが行き届いている
- 失敗サンプルが安定して戻ってくる
この3つがすべて成り立つとき、
はじめてモデル品質は継続的に、しかも説明可能な形で向上します。
練習
- 自分がよく知っているタスクについて、3〜5個のラベルを設計し、それぞれの正例と反例を書いてください。
- この節のコードを参考にして、2人分のラベルデータを自分で作り、一致率と kappa を計算してみてください。
- あなたのプロジェクトで、どのオンライン失敗サンプルを優先して学習データに戻すべきか考えてみてください。
- 2人のラベラーがいつも同じ種類のサンプルで争うなら、まず規約を直すべきか、ラベル体系を直すべきか、それともすぐ投票で決めるべきか。なぜですか?