5.4.2 評価指標
この節の概要
指標は、レポートを飾る点数ではありません。どのモデルを信じるか、どのしきい値を出すか、プロダクトがどのミスを負担するかを決めます。
作るもの
この節では、評価実験を 1 つ完成させます。
- 不均衡分類で accuracy の罠を見る;
- しきい値を調整し、偽陽性/偽陰性を読む;
- ROC AUC と average precision を比較する;
- MAE、RMSE、R2 で回帰を評価する;
- 習慣ではなく、プロダクト上のコストから指標を選ぶ。
まず図を見てください。
用語早見表
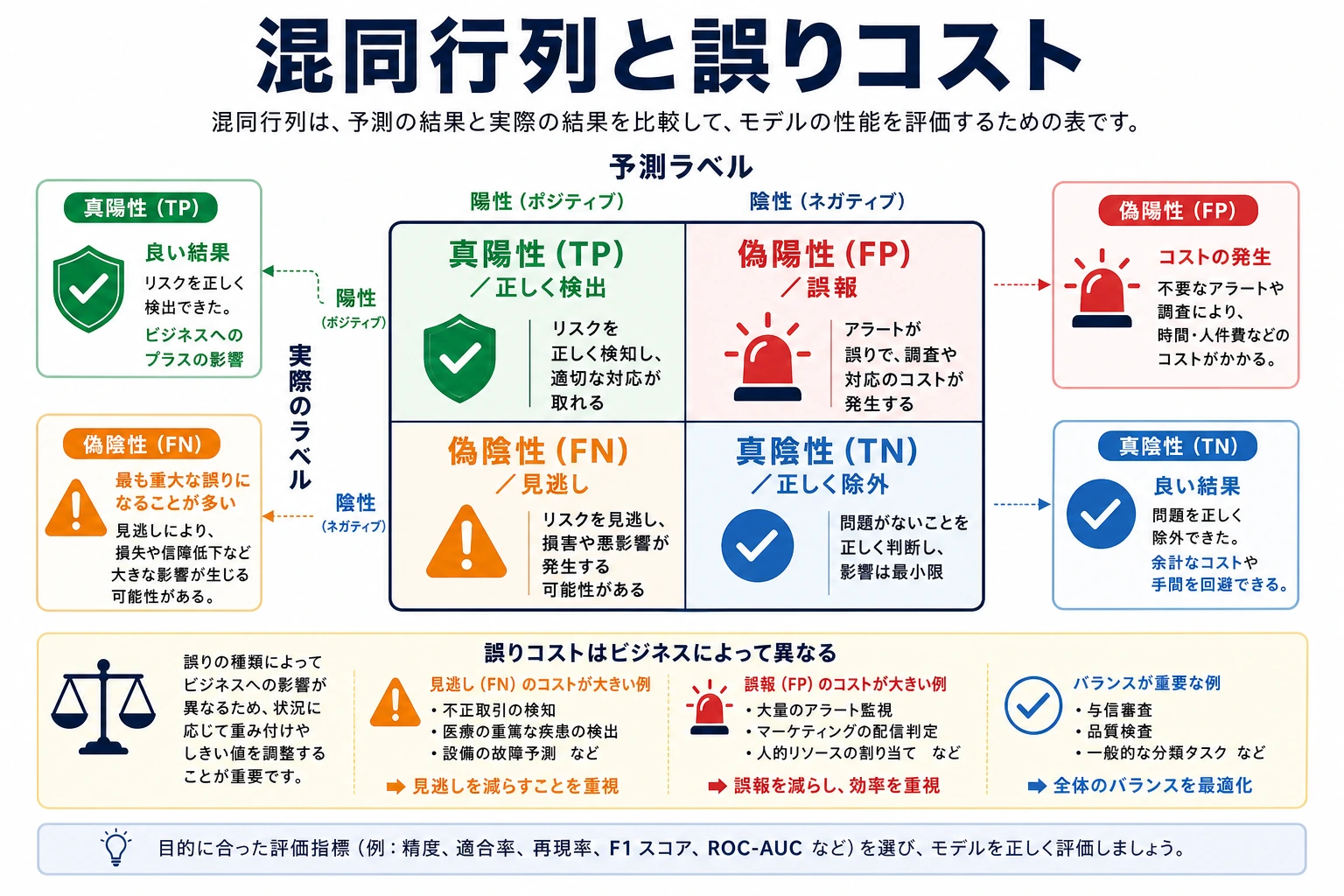
| 用語 | 実用上の意味 |
|---|---|
TP | true positive。本当に正で、正と予測した |
FP | false positive。本当は負だが、正と予測した |
FN | false negative。本当は正だが、見逃した |
precision | 正と予測した中で、本当に正だった割合 |
recall | 本当の正の中で、見つけられた割合 |
F1 | precision と recall の調和平均 |
ROC AUC | 多くのしきい値にまたがるランキング品質。正例が少ないと楽観的に見えることがある |
average_precision | precision-recall 曲線の面積。正例が少ないとき参考になりやすい |
MAE | 回帰の平均絶対誤差 |
RMSE | 平均二乗誤差の平方根。大きなミスを強く罰する |
セットアップ
python -m pip install -U scikit-learn
完全な実験を実行する
metrics_lab.py を作成します。
from sklearn.datasets import load_diabetes, make_classification
from sklearn.dummy import DummyClassifier, DummyRegressor
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.metrics import (
accuracy_score,
average_precision_score,
confusion_matrix,
f1_score,
mean_absolute_error,
mean_squared_error,
precision_score,
r2_score,
recall_score,
roc_auc_score,
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X, y = make_classification(
n_samples=1200,
n_features=12,
n_informative=5,
n_redundant=2,
weights=[0.92, 0.08],
class_sep=1.2,
random_state=42,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
baseline = DummyClassifier(strategy="most_frequent")
baseline.fit(X_train, y_train)
base_pred = baseline.predict(X_test)
print("classification_baseline")
print(f"accuracy={accuracy_score(y_test, base_pred):.3f}")
print(f"precision={precision_score(y_test, base_pred, zero_division=0):.3f}")
print(f"recall={recall_score(y_test, base_pred):.3f}")
model = Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, random_state=42)),
])
model.fit(X_train, y_train)
prob = model.predict_proba(X_test)[:, 1]
print("threshold_lab")
for threshold in [0.2, 0.5, 0.8]:
pred = (prob >= threshold).astype(int)
tn, fp, fn, tp = confusion_matrix(y_test, pred).ravel()
print(
f"threshold={threshold:.1f} "
f"accuracy={accuracy_score(y_test, pred):.3f} "
f"precision={precision_score(y_test, pred, zero_division=0):.3f} "
f"recall={recall_score(y_test, pred):.3f} "
f"f1={f1_score(y_test, pred):.3f} "
f"fp={fp} fn={fn}"
)
print(f"roc_auc={roc_auc_score(y_test, prob):.3f}")
print(f"average_precision={average_precision_score(y_test, prob):.3f}")
print("regression_lab")
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
for name, reg in [
("mean_baseline", DummyRegressor(strategy="mean")),
("linear", LinearRegression()),
]:
reg.fit(X_train, y_train)
pred = reg.predict(X_test)
rmse = mean_squared_error(y_test, pred) ** 0.5
print(
f"{name:<13} "
f"mae={mean_absolute_error(y_test, pred):.1f} "
f"rmse={rmse:.1f} "
f"r2={r2_score(y_test, pred):.3f}"
)
実行します。
python metrics_lab.py
期待される出力:
classification_baseline
accuracy=0.917
precision=0.000
recall=0.000
threshold_lab
threshold=0.2 accuracy=0.907 precision=0.462 recall=0.720 f1=0.562 fp=21 fn=7
threshold=0.5 accuracy=0.943 precision=0.833 recall=0.400 f1=0.541 fp=2 fn=15
threshold=0.8 accuracy=0.923 precision=1.000 recall=0.080 f1=0.148 fp=0 fn=23
roc_auc=0.889
average_precision=0.660
regression_lab
mean_baseline mae=65.5 rmse=74.9 r2=-0.014
linear mae=41.5 rmse=53.4 r2=0.485
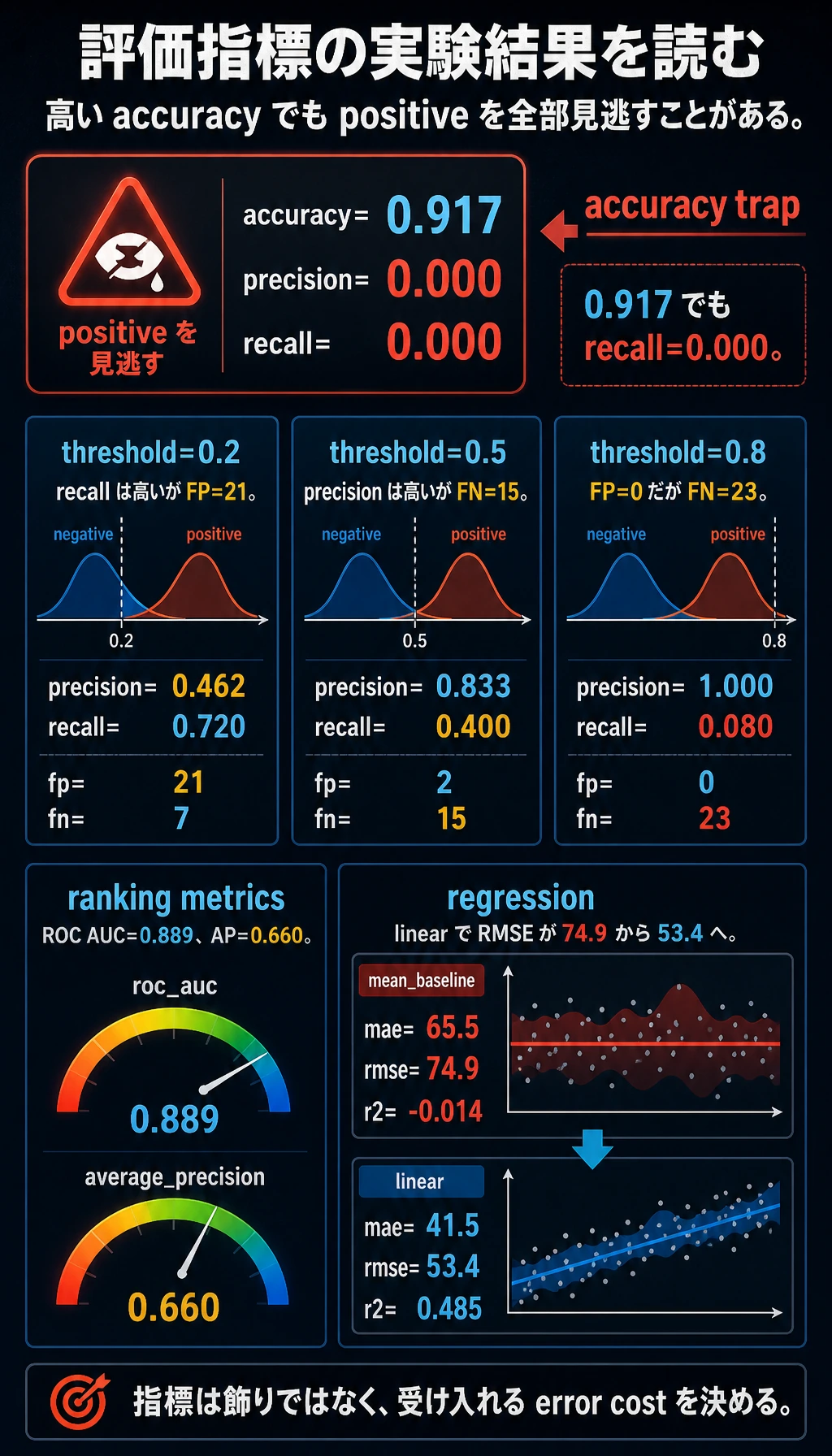
Accuracy の罠
baseline は毎回多数派クラスを予測します。
accuracy=0.917
precision=0.000
recall=0.000
accuracy は高く見えますが、正例を 1 件も見つけていません。不均衡分類では、accuracy だけを見るとかなり危険です。
まず混同行列を見る
分類指標はすべて 4 つの数から作られます。
| 数 | 意味 |
|---|---|
TP | 正例を正しく見つけた |
FP | 正常なサンプルを誤ってアラートした |
FN | 正例を見逃した |
TN | 正常なサンプルを正しく無視した |
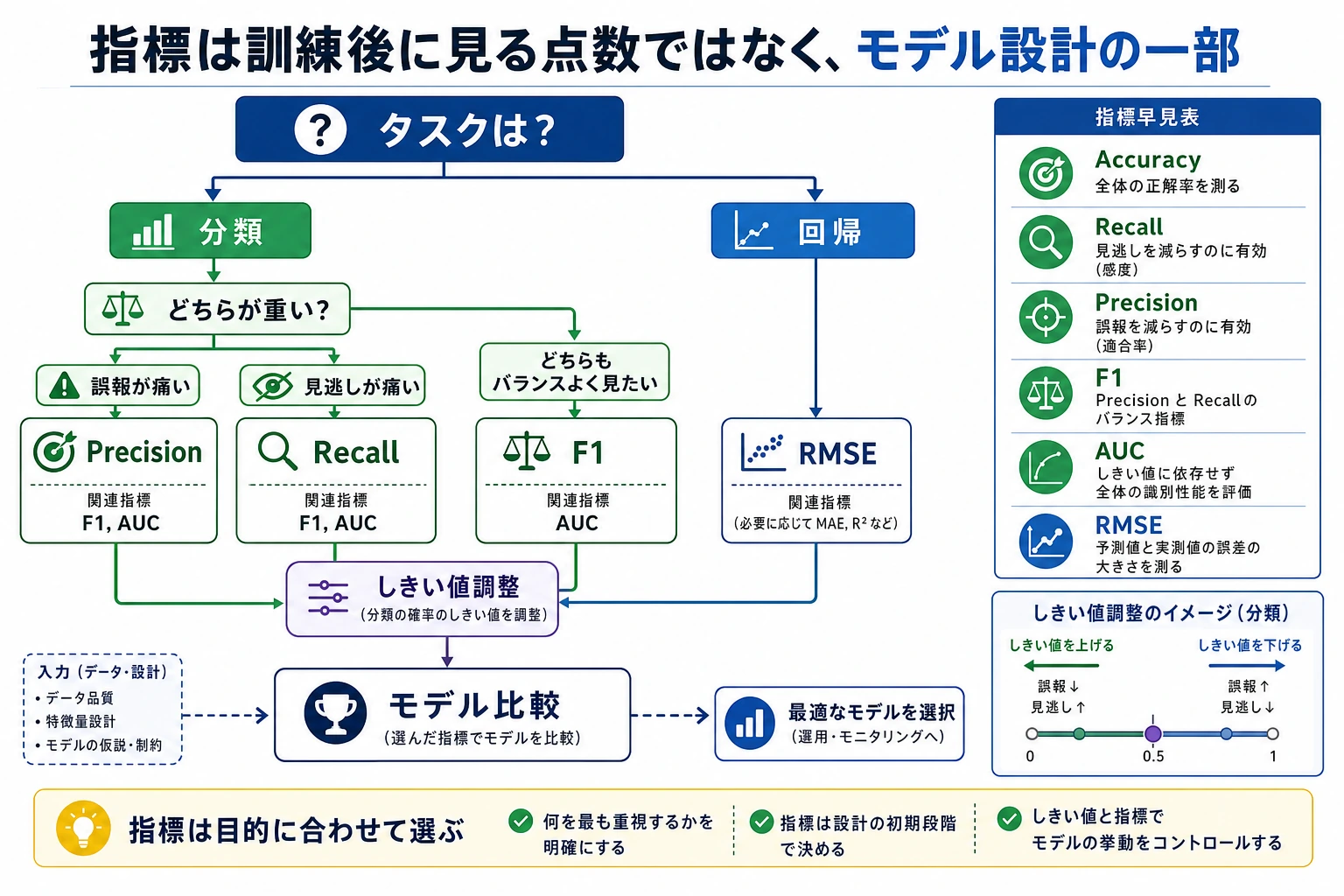
指標を選ぶ前に確認します。
FPとFNのどちらが高いか?- モデルはスクリーニング、ランキング、ブロック、最終判断のどれに使うのか?
- 人がレビューできる件数はどれくらいか?
しきい値で話が変わる
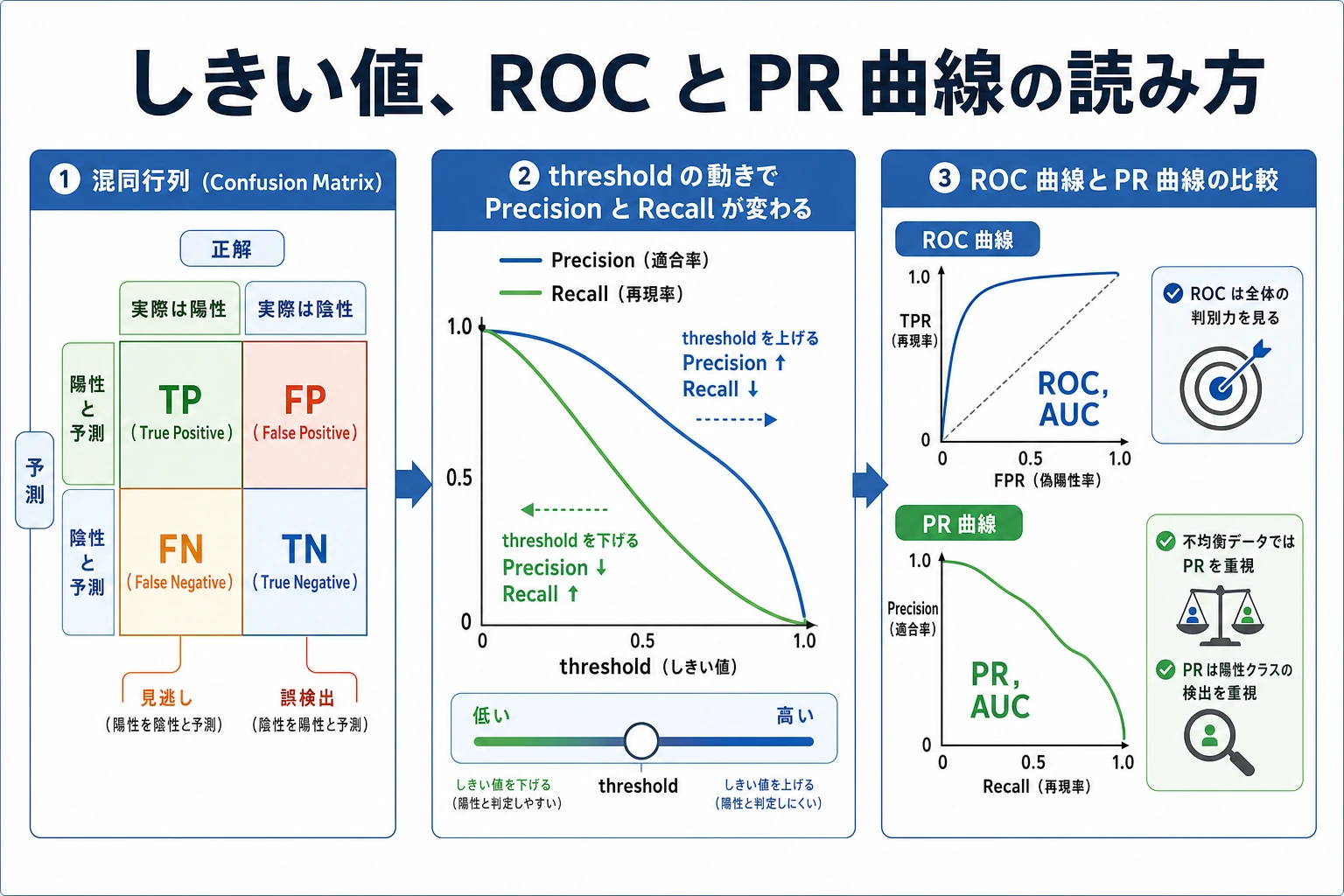
同じモデルでも、しきい値が違うと振る舞いが変わります。
threshold=0.2 precision=0.462 recall=0.720 fp=21 fn=7
threshold=0.8 precision=1.000 recall=0.080 fp=0 fn=23
しきい値を下げると、より多くの正例を拾いますが、誤アラートも増えます。しきい値を上げると、誤アラートは減りますが、見逃しが増えます。
次のように選びます。
| プロダクト目標 | 主な指標 |
|---|---|
| 正例をできるだけ拾う | recall |
| アラートの信頼性を保つ | precision |
| precision と recall のバランス | F1 |
| しきい値をまたいで候補をランキング | ROC AUC |
| 正例が少ない | average precision / PR curve |
ROC AUC と Average Precision
roc_auc=0.889 は、複数のしきい値をまたいで、正例を負例より上に並べる力があることを示します。
average_precision=0.660 は、precision-recall の振る舞いに注目するため、希少な正例に対してより厳しい指標です。詐欺、医療スクリーニング、セキュリティアラート、解約防止では、ROC AUC だけでなく precision-recall 指標を必ず見ます。
回帰指標
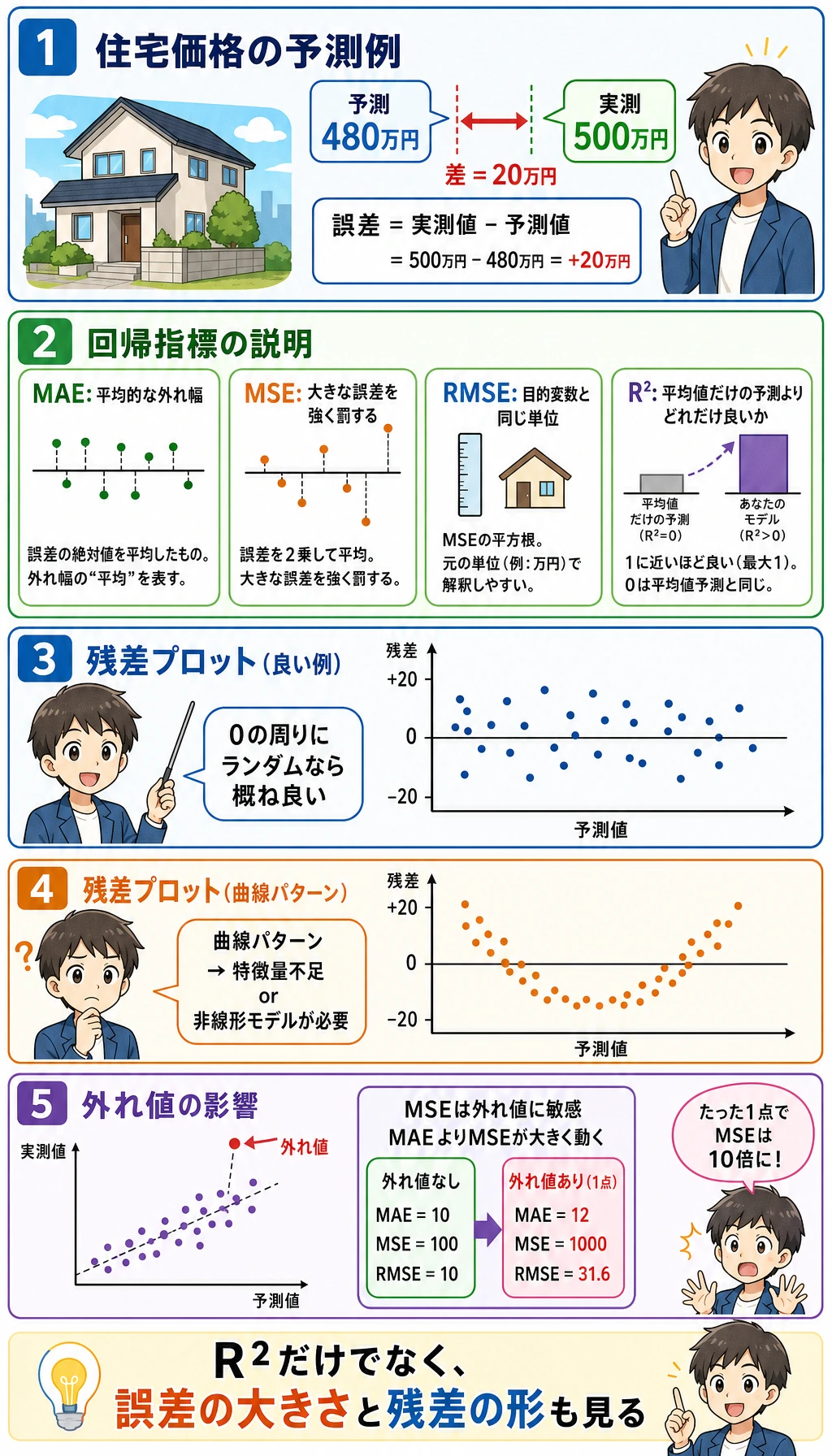
回帰実験では、平均ベースラインと線形モデルを比べます。
mean_baseline mae=65.5 rmse=74.9 r2=-0.014
linear mae=41.5 rmse=53.4 r2=0.485
読み方は次の通りです。
| 指標 | 使う場面 |
|---|---|
MAE | 元の単位で平均誤差を理解したい |
RMSE | 大きな誤差が特に痛い |
R2 | 平均ベースラインよりどれだけ良いかを知りたい |
R2 だけに頼らないでください。R2 がそこそこ良くても、重要なケースで許容できない誤差を出すことがあります。
実用的な指標選択
| タスク | 最初に見る | その後に確認 |
|---|---|---|
| バランスした分類 | accuracy、F1 | 混同行列 |
| 不均衡分類 | precision、recall、F1 | PR 曲線、しきい値表 |
| スクリーニング / 検知 | recall | アラート量と偽陽性 |
| 最終承認 / ブロック | precision | 見逃しと人手レビュー方針 |
| ランキング | ROC AUC、average precision | top-k precision |
| 回帰 | MAE、RMSE | 残差図とセグメント別誤差 |
経験者向け:セグメント別に評価してください。全体指標は、地域、顧客群、言語、デバイス種別、希少クラスでの失敗を隠すことがあります。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| accuracy は高いが recall がゼロ | クラス不均衡 | 混同行列と recall を見る |
| ROC AUC は良いがアラートが悪い | しきい値不適切、または正例が少ない | PR 曲線とアラート量を見る |
| F1 は上がったがプロダクトは悪化 | 指標が業務コストに合っていない | FP/FN コストを明確に定義する |
| 回帰の平均誤差は良い | 特定セグメントの大誤差が隠れている | セグメント別に残差を見る |
| 本番でオフライン指標が下がる | 分布シフト | データと指標のドリフトを監視する |
練習
- クラス比を
[0.98, 0.02]に変えてください。accuracy と recall はどう変わりますか? - しきい値
[0.1, 0.3, 0.7, 0.9]を追加してください。スクリーニング用途ならどれを出しますか? - 各しきい値で
tp、fp、fn、tnを表示してください。 - 木モデルを追加し、ROC AUC と average precision を比較してください。
- 回帰で絶対誤差が最大の 5 件を表示し、入力を確認してください。
合格チェック
次を説明できれば、この節はクリアです。
- 不均衡データでは accuracy が誤解を招くことがある;
- precision と recall は異なる誤りコストを表す;
- しきい値選択はプロダクト設計の一部;
- ROC AUC と PR 指標は別の問いに答える;
- 回帰指標は残差とセグメント確認と合わせて読む。