5.4.3 クロスバリデーション
この節の概要
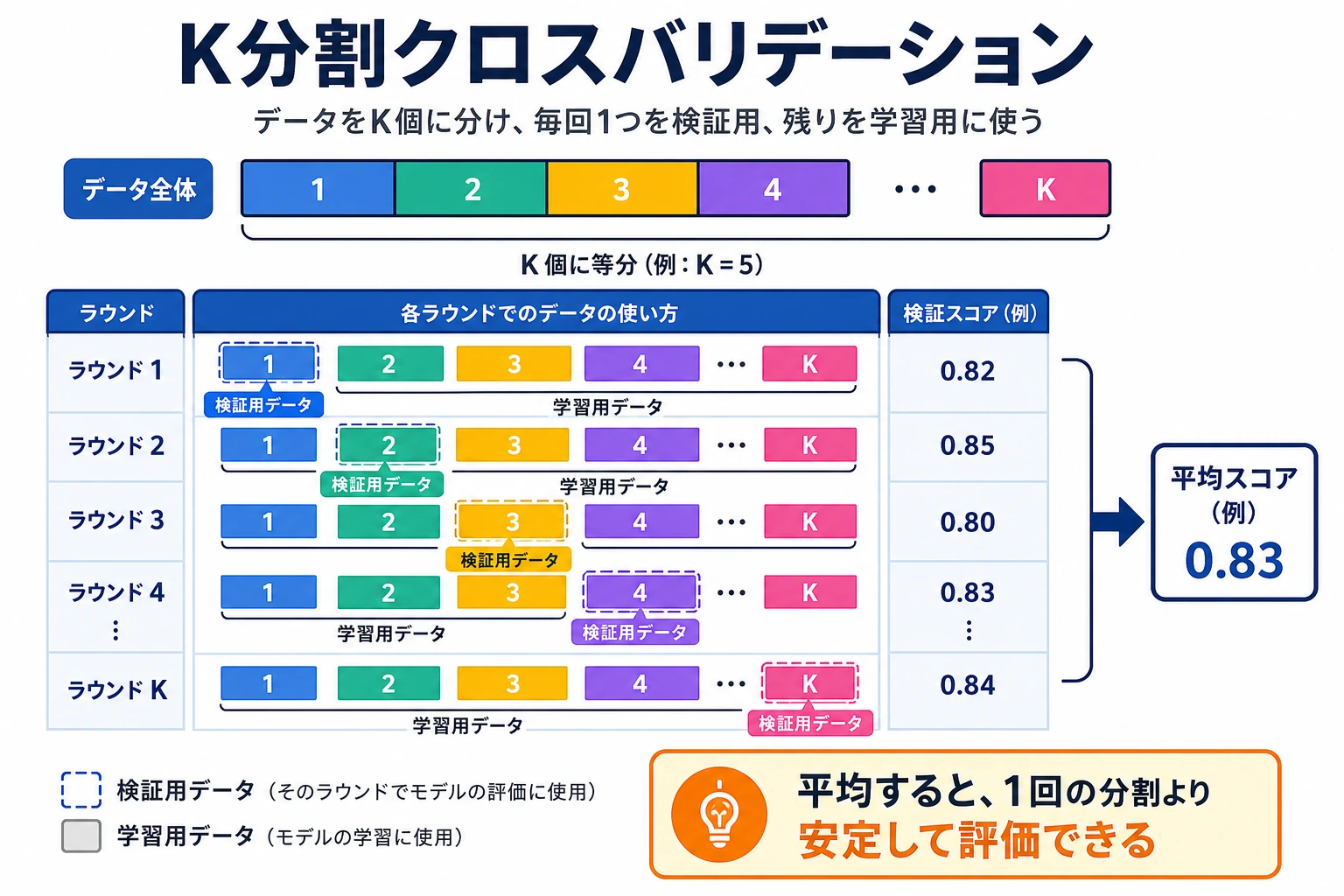
1 回の train-test 分割は 1 枚のスナップショットです。クロスバリデーションは、複数の検証 fold でモデルを試すことで、より安定した推定を得ます。
作るもの
この節では次を確認します。
- 1 回の train-test 分割がなぜ不安定になり得るか;
- 分類で
StratifiedKFoldを使う方法; cross_validateで複数指標を同時に評価する方法;- 前処理を
Pipelineに入れる理由; - 時系列など、ランダム K-Fold が間違いになる場面。
セットアップ
python -m pip install -U scikit-learn numpy
完全な実験を実行する
cv_lab.py を作成します。
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold, cross_validate, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)
print("single_split_variance")
for seed in [1, 2, 3, 4, 5]:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=seed, stratify=y
)
model = Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, random_state=42)),
])
model.fit(X_train, y_train)
print(f"seed={seed} accuracy={accuracy_score(y_test, model.predict(X_test)):.3f}")
print("cross_validation_lab")
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
model = Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, random_state=42)),
])
result = cross_validate(
model,
X,
y,
cv=cv,
scoring=["accuracy", "precision", "recall", "f1"],
)
for i, score in enumerate(result["test_accuracy"], start=1):
print(f"fold={i} accuracy={score:.3f}")
print(
"summary "
f"accuracy={np.mean(result['test_accuracy']):.3f}+/-{np.std(result['test_accuracy']):.3f} "
f"precision={np.mean(result['test_precision']):.3f} "
f"recall={np.mean(result['test_recall']):.3f} "
f"f1={np.mean(result['test_f1']):.3f}"
)
実行します。
python cv_lab.py
期待される出力:
single_split_variance
seed=1 accuracy=0.965
seed=2 accuracy=0.972
seed=3 accuracy=0.986
seed=4 accuracy=0.972
seed=5 accuracy=0.979
cross_validation_lab
fold=1 accuracy=0.974
fold=2 accuracy=0.947
fold=3 accuracy=0.965
fold=4 accuracy=0.991
fold=5 accuracy=0.991
summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979

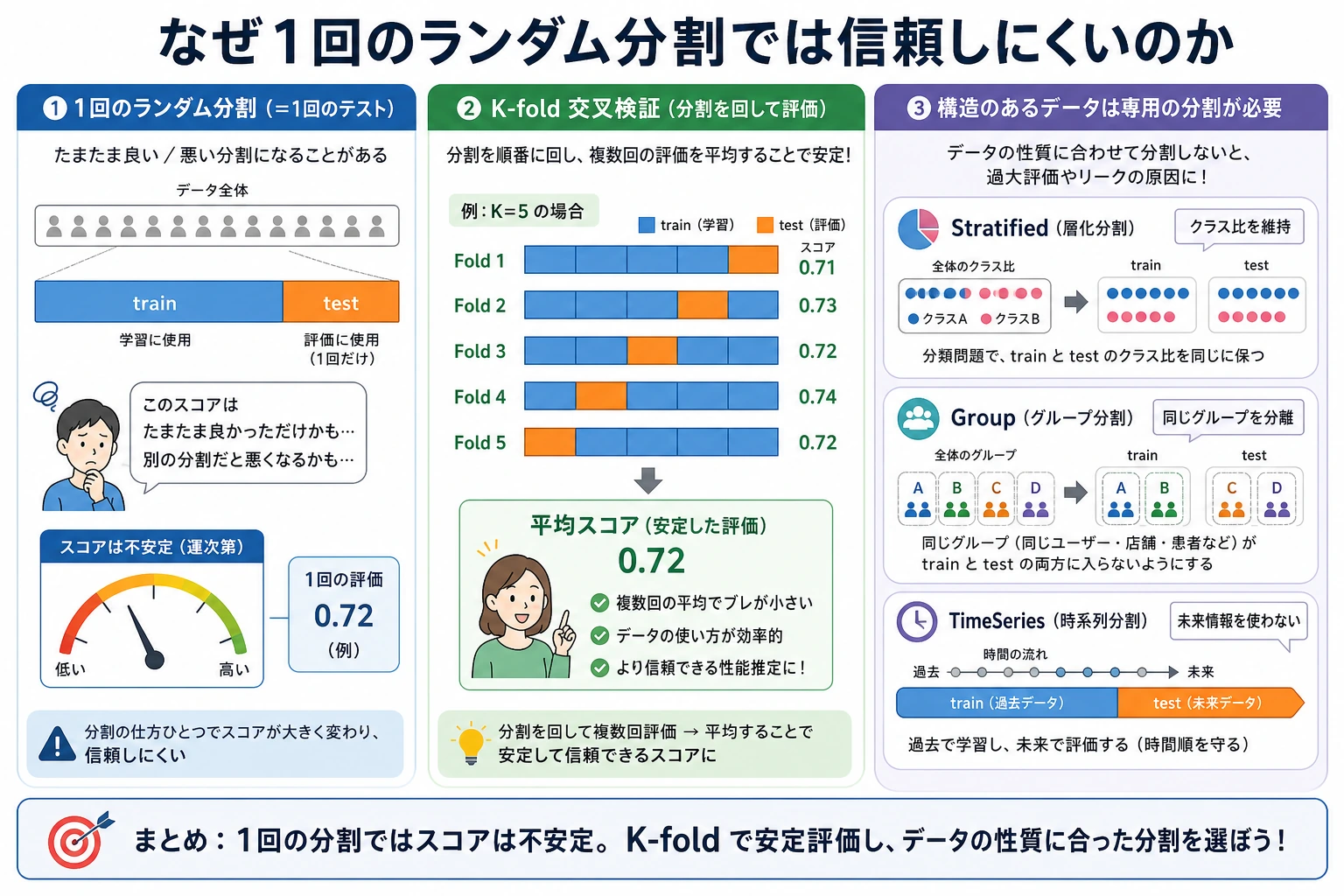
1 回の分割だけでは足りない理由
同じモデルでも、ランダム分割が違うとスコアが変わります。
seed=1 accuracy=0.965
seed=3 accuracy=0.986
どちらも嘘ではありません。違うスナップショットを見ているだけです。クロスバリデーションは、「複数のスナップショットで、平均性能はいくらか、どれくらい揺れるか」を見ます。
Stratified K-Fold
分類では、まず StratifiedKFold を使います。各 fold のクラス比率を全体に近づけるため、不均衡データで特に重要です。
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
K=5 は実用的な既定値です。
- 1 回の分割より安定する;
- 大きなデータで 10-fold より安い;
- チームに説明しやすい。
漏洩を防ぐ Pipeline
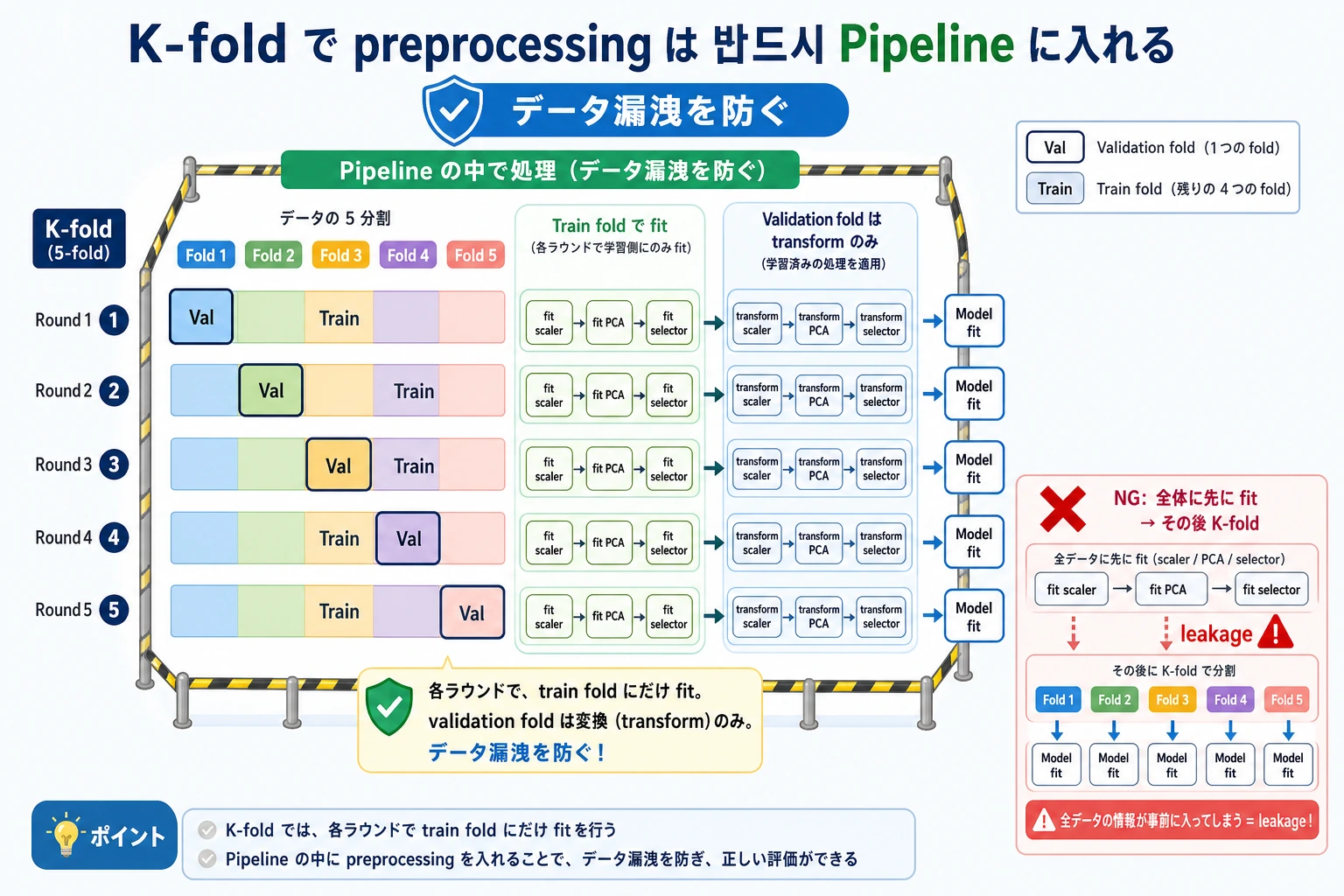
安全な形は次です。
Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, random_state=42)),
])
クロスバリデーションでは、各 fold の scaler はその fold の訓練部分だけで fit される必要があります。CV の前に全データをスケーリングすると、検証 fold の情報が訓練へ漏れます。
平均とばらつきを読む
summary は単一 fold より有用です。
summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979
こう読みます。
- 平均 accuracy は約
0.974; - fold 間のばらつきは約
0.017; - recall が非常に高く、正例の見逃しが高コストなら重要。
標準偏差が大きい場合、モデルが不安定、データが少ない、または特定 fold が難しい可能性があります。
K-Fold が間違いになる場面
次の場合はランダムに shuffle しないでください。
- 時系列データ;
- 同じユーザー、セッション、デバイスの行が train と validation の両方に入り得る;
- サンプルが患者、顧客、文書、実験などでグループ化されている;
- 未来情報が過去へ漏れる。
実際のデプロイ状況に合う分割を使います。TimeSeriesSplit、group split、または時系列の最後を holdout にします。
実用的な選び方
| 状況 | 使うもの |
|---|---|
| 基本的な分類 | StratifiedKFold(n_splits=5, shuffle=True) |
| 回帰 | KFold(n_splits=5, shuffle=True) |
| 時系列 | TimeSeriesSplit または時系列検証 |
| 同じエンティティが複数回出る | group-aware splitting |
| ハイパーパラメータ調整 | nested CV または最後まで触らない test set |
経験者向け:モデル選択が終わった後、調整に使っていない最終 holdout または本番に近い backtest を残してください。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| CV スコアが test よりかなり高い | 漏洩または過度な調整 | 前処理を pipeline に入れ、最終 holdout を残す |
| fold スコアが大きく揺れる | データが少ない、または難しいセグメントがある | fold 構成とセグメント別指標を見る |
| 分類 fold に正例がない | stratify していない | StratifiedKFold を使う |
| 時系列モデルが良すぎる | 未来データが漏れた | 時系列順に検証する |
| CV が遅すぎる | fold が多すぎる、モデルが重い | fold を減らすか、速い基線を先に使う |
練習
n_splitsを3と10に変えてください。平均と標準偏差はどう変わりますか?- 単一分割から
stratify=yを外してください。スコアは不安定になりますか? - scoring リストに
roc_aucを追加してください。 - わざと
StandardScaler()を pipeline の外に出し、なぜ危険か説明してください。 - 1 ユーザーに複数行のイベントがあるデータに対して、検証分割を設計してください。
合格チェック
次を説明できれば、この節はクリアです。
- 1 回の train-test 分割は 1 つのスナップショットにすぎない;
- K-Fold は平均性能とばらつきを推定する;
- 分類では通常 stratified folds を使う;
- 前処理は pipeline の中に入れる;
- 検証戦略はデプロイ時のデータの流れに合わせる。