5.3.3 次元削減
この節の概要
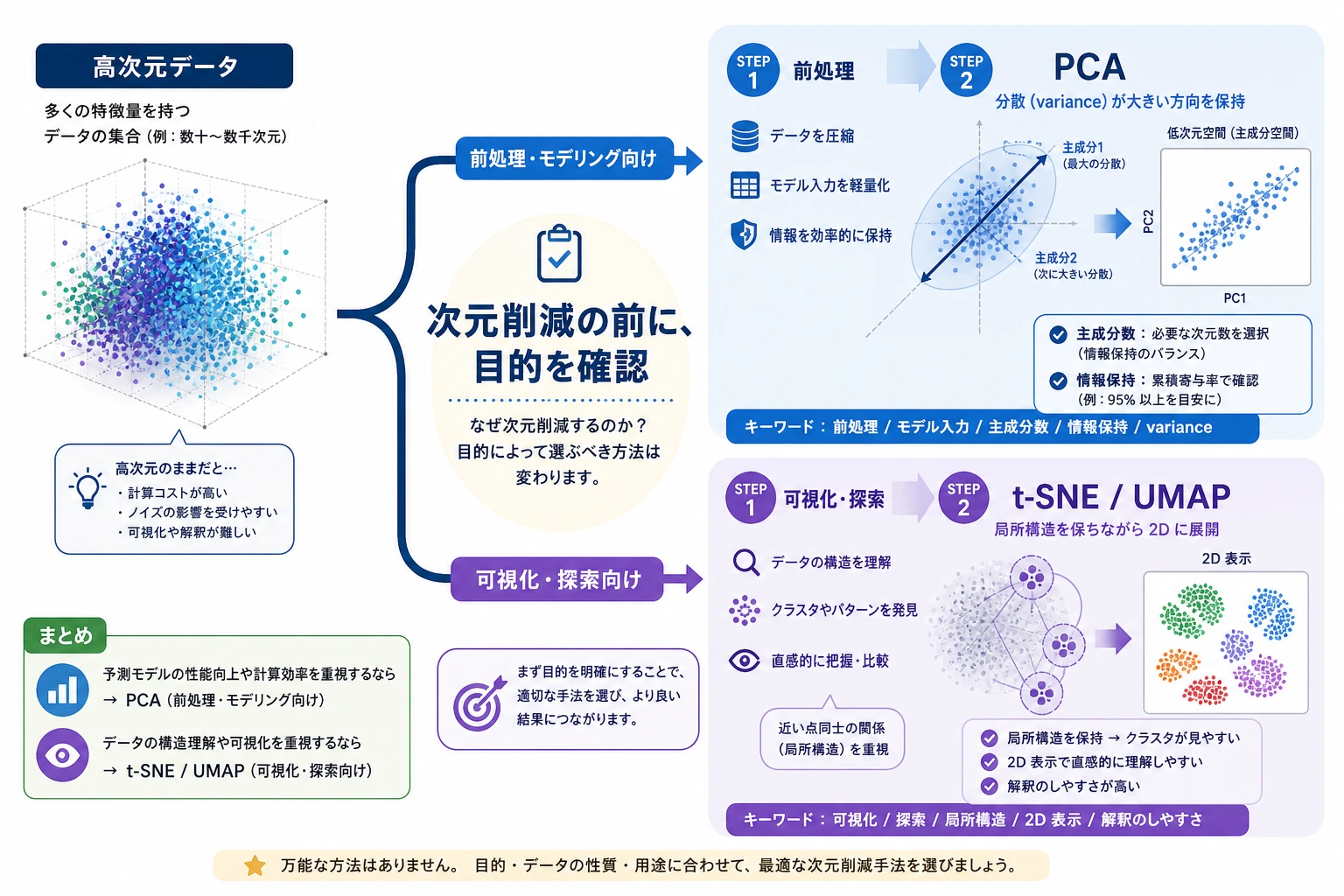
次元削減は、多数の特徴量をより少ない特徴量へ圧縮する方法です。可視化、高速化、ノイズ低減、モデリングに役立ちますが、目的ごとに確認すべきことが違います。
作るもの
この節では、手書き数字データセットを使って次を確認します。
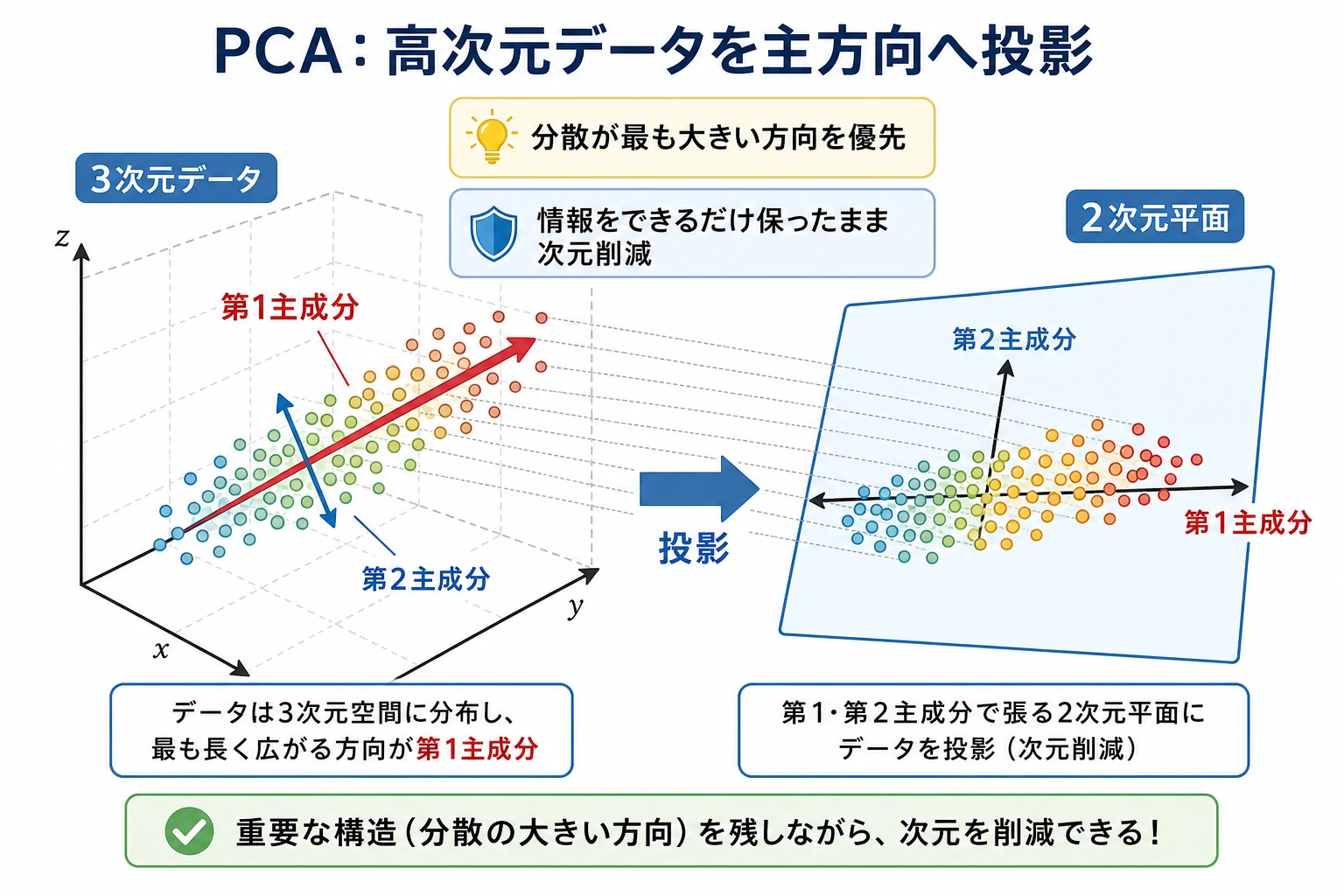
- PCA が高次元画像を 2 次元へ写す方法;
- 10、20、40 個の成分を残したとき説明分散がどう変わるか;
- PCA が分類 accuracy にどう影響するか;
- 成分を増やすと再構成誤差がどう下がるか;
- PCA、t-SNE、UMAP をどう使い分けるか。
まず図を見てください。次元削減は、1 つの道具が 1 つの目的だけを持つものではありません。
用語早見表
| 用語 | 実用上の意味 |
|---|---|
dimension | 1 つの特徴量列。たとえば 1 ピクセルや 1 つの数値項目 |
PCA | Principal Component Analysis。できるだけ多くの分散を残す方向を探す |
component | PCA が作る新しい圧縮特徴量 |
explained_variance_ratio_ | 各成分がどれだけ分散を保持しているか |
reconstruction | 圧縮成分から元データを近似的に復元すること |
t-SNE | 局所的な近傍構造を可視化する方法 |
UMAP | embedding の可視化や近傍探索によく使われる方法 |
セットアップ
python -m pip install -U scikit-learn numpy
実行するラボでは sklearn と NumPy だけを使います。UMAP は実務では便利ですが追加パッケージが必要なので、この初心者向けラボでは依存を小さく保ちます。
完全な実験を実行する
pca_lab.py を作成します。
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("pca_2d_map")
pca2 = PCA(n_components=2, random_state=42)
X_train_2d = pca2.fit_transform(X_train_scaled)
print("shape=", X_train_2d.shape)
print("explained_variance=", np.round(pca2.explained_variance_ratio_, 3).tolist())
print("total_2d_variance=", round(float(pca2.explained_variance_ratio_.sum()), 3))
print("pca_modeling_lab")
for n in [10, 20, 40]:
model = Pipeline([
("scale", StandardScaler()),
("pca", PCA(n_components=n, random_state=42)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
model.fit(X_train, y_train)
pred = model.predict(X_test)
pca = model.named_steps["pca"]
print(
f"components={n:<2} "
f"variance={pca.explained_variance_ratio_.sum():.3f} "
f"accuracy={accuracy_score(y_test, pred):.3f}"
)
print("reconstruction_lab")
for n in [10, 20, 40]:
pca = PCA(n_components=n, random_state=42)
compressed = pca.fit_transform(X_train_scaled)
restored = pca.inverse_transform(compressed)
mse = mean_squared_error(X_train_scaled, restored)
print(f"components={n:<2} reconstruction_mse={mse:.3f}")
実行します。
python pca_lab.py
期待される出力:
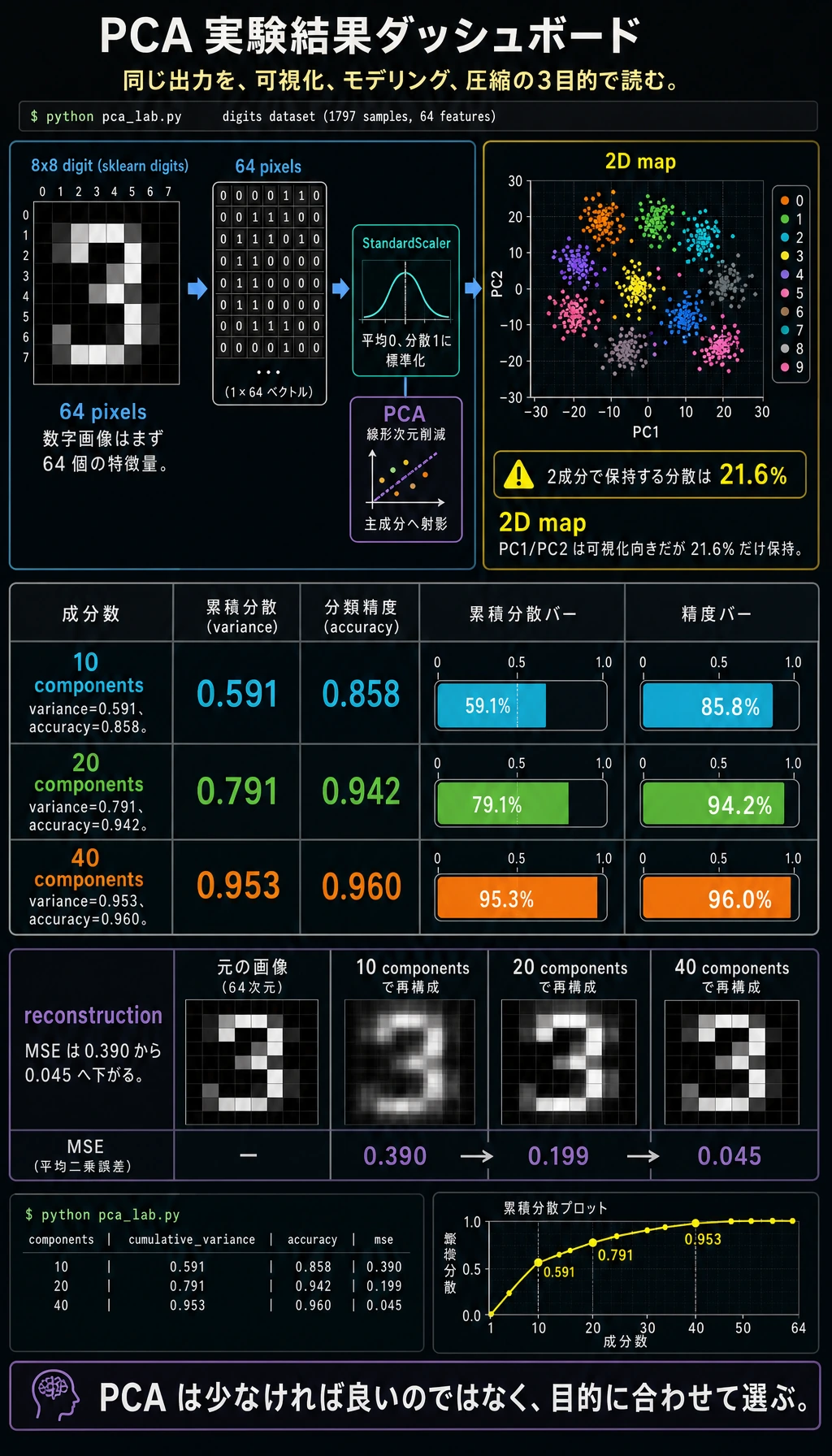
pca_2d_map
shape= (1347, 2)
explained_variance= [0.119, 0.097]
total_2d_variance= 0.216
pca_modeling_lab
components=10 variance=0.591 accuracy=0.858
components=20 variance=0.791 accuracy=0.942
components=40 variance=0.953 accuracy=0.960
reconstruction_lab
components=10 reconstruction_mse=0.390
components=20 reconstruction_mse=0.199
components=40 reconstruction_mse=0.045
2 次元結果を読む
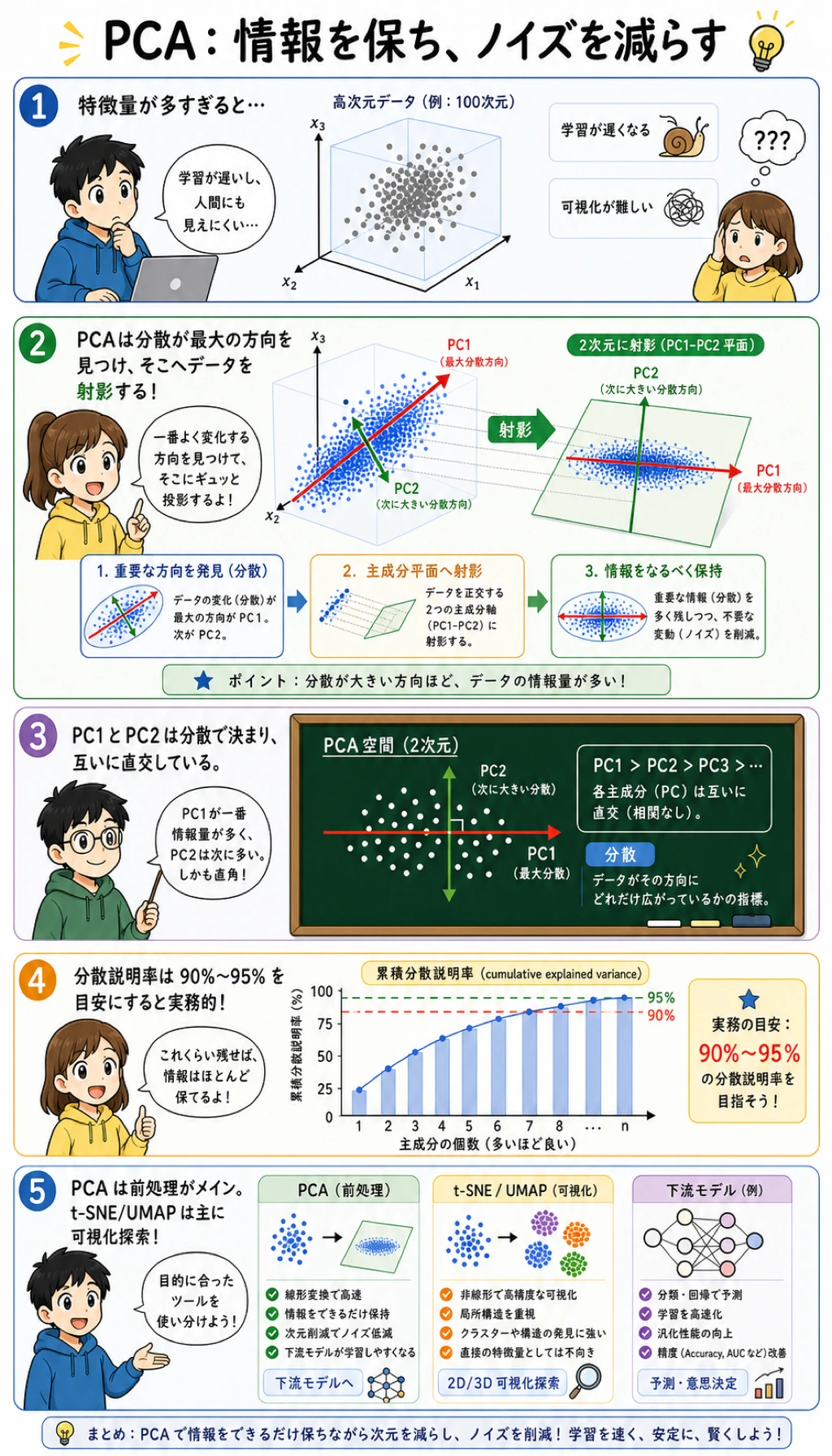
digits データセットには 64 個のピクセル特徴量があります。n_components=2 の PCA は、各画像を 2 つの数値へ圧縮します。
shape= (1347, 2)
total_2d_variance= 0.216
2 成分は可視化には便利ですが、分散の約 21.6% しか保持しません。ざっくり地図を見るには十分でも、本格的な分類器には少なすぎることがあります。
説明分散
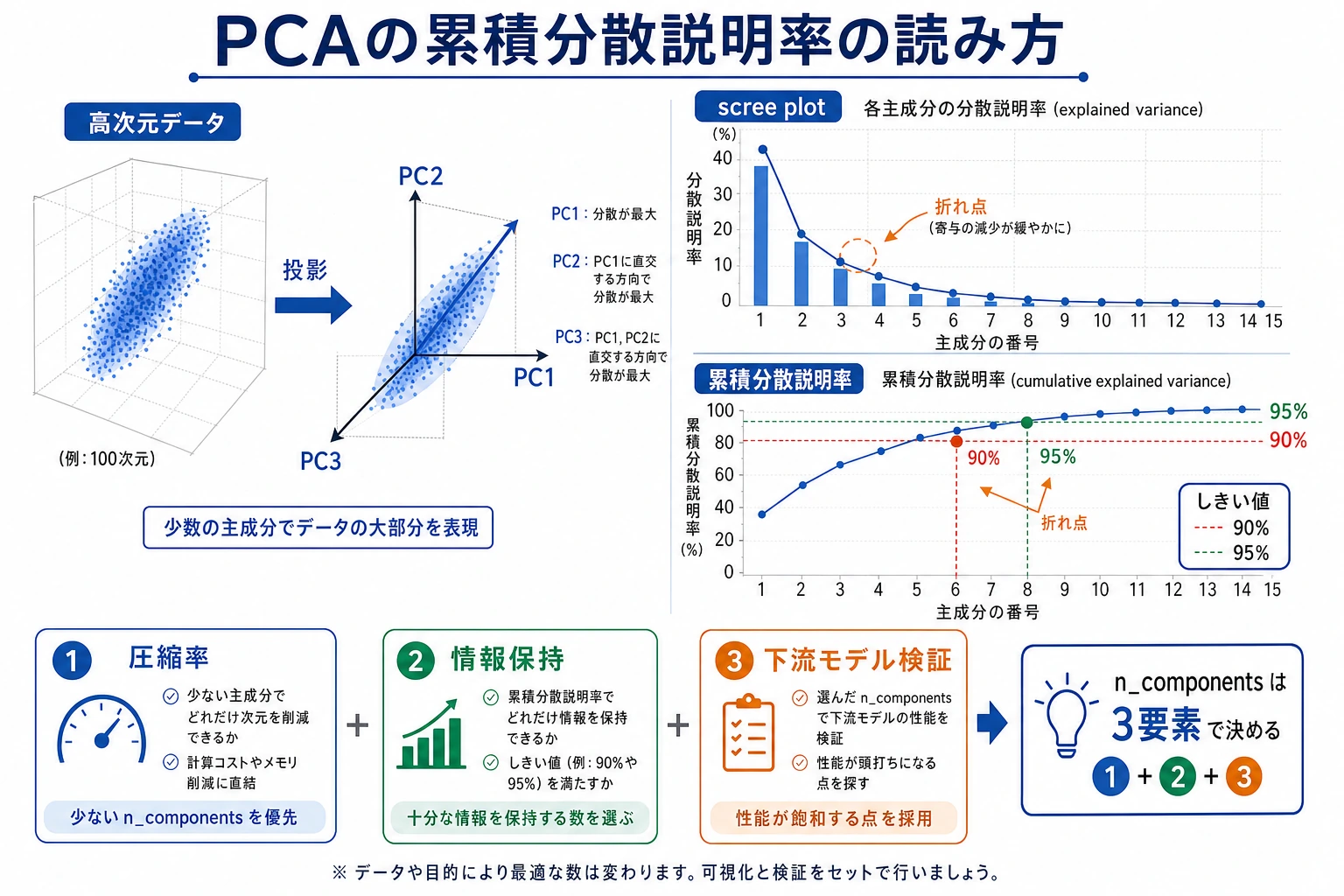
説明分散は、どれだけ情報を残すかを判断する助けになります。
components=10 variance=0.591 accuracy=0.858
components=20 variance=0.791 accuracy=0.942
components=40 variance=0.953 accuracy=0.960
大事なのは「常に 95% 残す」ことではありません。実用的には次のように考えます。
- 可視化が目的なら、
2または3成分で十分なことがある; - モデリングが目的なら、accuracy やプロジェクトで使う指標を比較する;
- 圧縮が目的なら、再構成誤差と保存コストを比較する。
再構成誤差
再構成は、圧縮後にどれだけ元データを復元できるかを見ます。
components=10 reconstruction_mse=0.390
components=40 reconstruction_mse=0.045
成分が多いほど復元は良くなりますが、次元も多く残ります。適切な数は、コンパクトさと有用な情報量のトレードオフです。
モデルパイプライン内の PCA
モデリング部分では次を使っています。
Pipeline([
("scale", StandardScaler()),
("pca", PCA(n_components=n, random_state=42)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
この順序が重要です。
- まず train/test に分ける。
- スケーリングは訓練データだけで fit する。
- PCA も訓練データだけで fit する。
- 圧縮された訓練特徴量でモデルを学習する。
- 変換されたテスト特徴量で評価する。
スケーリングと PCA を pipeline に入れると、交差検証時のデータ漏れを防ぎやすくなります。
PCA、t-SNE、UMAP
| 方法 | 向いている用途 | 重要な注意点 |
|---|---|---|
| PCA | 圧縮、前処理、高速な 2D 概観 | 線形手法なので曲がった構造を見落とすことがある |
| t-SNE | 局所近傍の可視化 | 離れたクラスタ同士の距離は誤解しやすい |
| UMAP | embedding 可視化と近傍探索 | 追加パッケージが必要。パラメータと安定性を確認する |
初心者にとって安全な順序:
- まず PCA。速くて解釈しやすい。
- t-SNE や UMAP は可視化に使い、最初から本番特徴量パイプラインにしない。
- 次元削減でモデル結果が変わるなら、交差検証で確認する。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| PCA 結果が 1 つの特徴量に支配される | 特徴量をスケーリングしていない | PCA 前に StandardScaler を使う |
| 2D 図はきれいだがモデルが弱い | 2D では分散を残しきれていない | モデリングではより多くの成分を使う |
| PCA 後に accuracy が大きく下がる | 有用な特徴を捨てすぎた | n_components を増やし、PCA なしの基線と比べる |
| 交差検証スコアが不自然に良い | 分割前に PCA を fit した | PCA を Pipeline に入れる |
| t-SNE/UMAP 図を読みすぎる | 可視化レイアウトは証明ではない | 安定性と下流での有用性を確認する |
練習
- PCA 成分を
[5, 15, 30, 50]に変えてください。accuracy はどこから伸びにくくなりますか? - PCA なしで分類器を学習してください。PCA が助けているのは速度、精度、圧縮のどれですか?
StandardScalerを外してください。説明分散はどう変わりますか?PCA(n_components=0.95)を使い、自動で選ばれた成分数を表示してください。- 2D PCA の出力を使って、数字ラベルで色分けした散布図を描いてください。
合格チェック
次を説明できれば、この節はクリアです。
- PCA は components と呼ばれる新しい圧縮特徴量を作る;
- 2D PCA は可視化に便利だが、モデリング情報を捨てすぎることがある;
- 説明分散は目安であり、自動的な目標ではない;
- PCA は訓練 pipeline の中で fit する必要がある;
- t-SNE と UMAP は主に可視化用で、厳密に検証しない限り安易に本番特徴量にしない。