5.3.3 降维
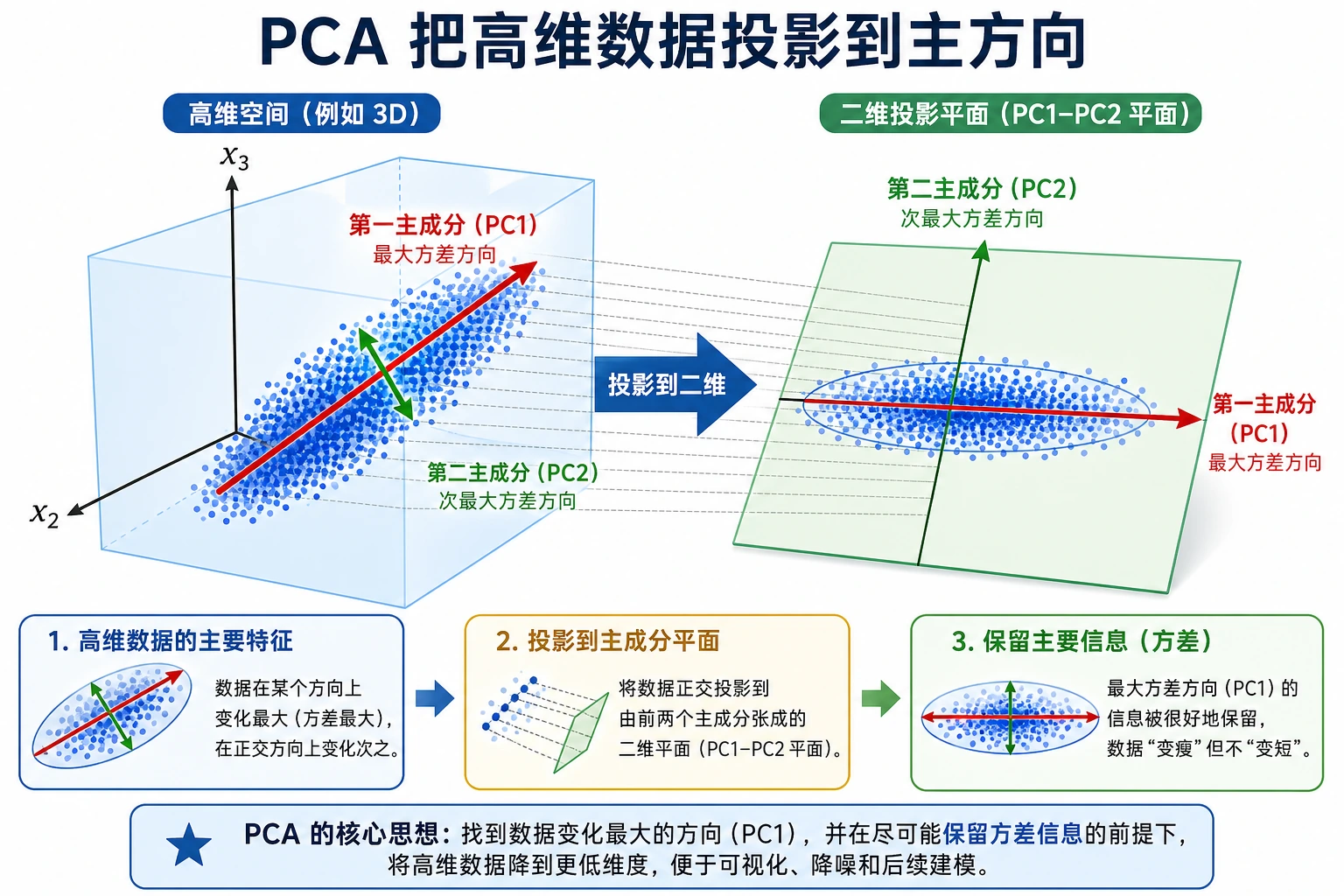
本节概览
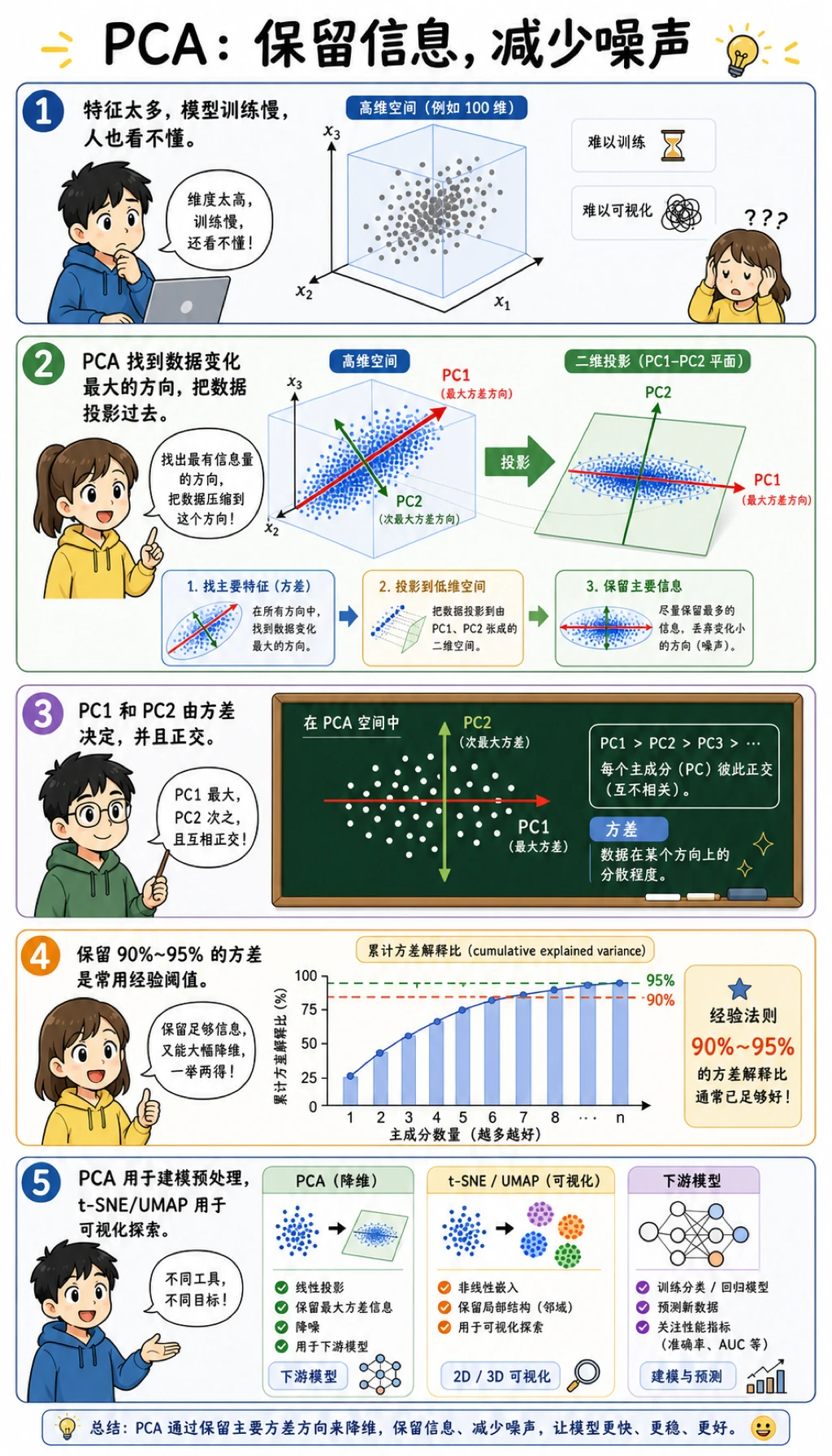
降维是把很多特征压缩成更少特征。它可以用于可视化、提速、降噪和建模,但不同目标需要不同检查方式。
你会做出什么
本节用手写数字数据集演示:
- PCA 如何把高维图片压到 2 维;
- 保留 10、20、40 个成分时解释方差如何变化;
- PCA 如何影响分类准确率;
- 保留更多成分时重建误差如何下降;
- PCA、t-SNE、UMAP 应该如何分工。
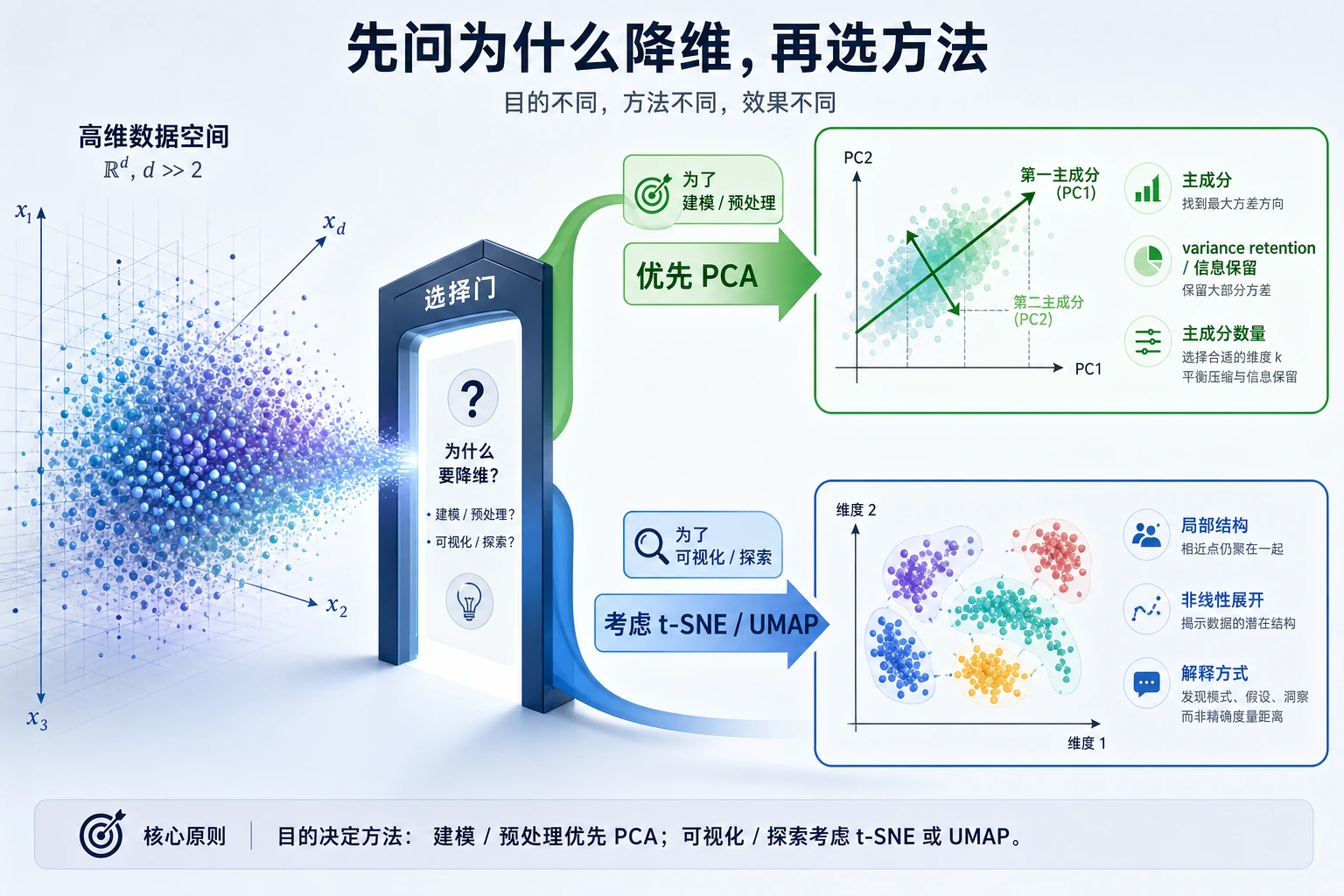
先看图。降维不是一个工具对应一个目的。
术语速查
| 术语 | 实用含义 |
|---|---|
dimension | 一个特征列,例如一个像素或一个数值字段 |
PCA | Principal Component Analysis,主成分分析,寻找能保留最多方差的方向 |
component | PCA 生成的新压缩特征 |
explained_variance_ratio_ | 每个成分保留了多少类似信息量的方差 |
reconstruction | 用压缩成分近似还原原始数据 |
t-SNE | 用于局部邻域结构可视化的方法 |
UMAP | 常用于 embedding 可视化和流形探索的方法 |
环境准备
python -m pip install -U scikit-learn numpy
可运行实验只使用 sklearn 和 NumPy。UMAP 在真实项目中很有用,但需要额外包,所以本节核心实验先保持依赖简单。
运行完整实验
新建 pca_lab.py:
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("pca_2d_map")
pca2 = PCA(n_components=2, random_state=42)
X_train_2d = pca2.fit_transform(X_train_scaled)
print("shape=", X_train_2d.shape)
print("explained_variance=", np.round(pca2.explained_variance_ratio_, 3).tolist())
print("total_2d_variance=", round(float(pca2.explained_variance_ratio_.sum()), 3))
print("pca_modeling_lab")
for n in [10, 20, 40]:
model = Pipeline([
("scale", StandardScaler()),
("pca", PCA(n_components=n, random_state=42)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
model.fit(X_train, y_train)
pred = model.predict(X_test)
pca = model.named_steps["pca"]
print(
f"components={n:<2} "
f"variance={pca.explained_variance_ratio_.sum():.3f} "
f"accuracy={accuracy_score(y_test, pred):.3f}"
)
print("reconstruction_lab")
for n in [10, 20, 40]:
pca = PCA(n_components=n, random_state=42)
compressed = pca.fit_transform(X_train_scaled)
restored = pca.inverse_transform(compressed)
mse = mean_squared_error(X_train_scaled, restored)
print(f"components={n:<2} reconstruction_mse={mse:.3f}")
运行:
python pca_lab.py
预期输出:
pca_2d_map
shape= (1347, 2)
explained_variance= [0.119, 0.097]
total_2d_variance= 0.216
pca_modeling_lab
components=10 variance=0.591 accuracy=0.858
components=20 variance=0.791 accuracy=0.942
components=40 variance=0.953 accuracy=0.960
reconstruction_lab
components=10 reconstruction_mse=0.390
components=20 reconstruction_mse=0.199
components=40 reconstruction_mse=0.045

读懂 2 维结果
digits 数据集有 64 个像素特征。n_components=2 的 PCA 会把每张图片压成两个数字:
shape= (1347, 2)
total_2d_variance= 0.216
两个成分适合快速画图,但只保留约 21.6% 方差。用来看地图可以,直接给严肃分类器可能不够。
解释方差
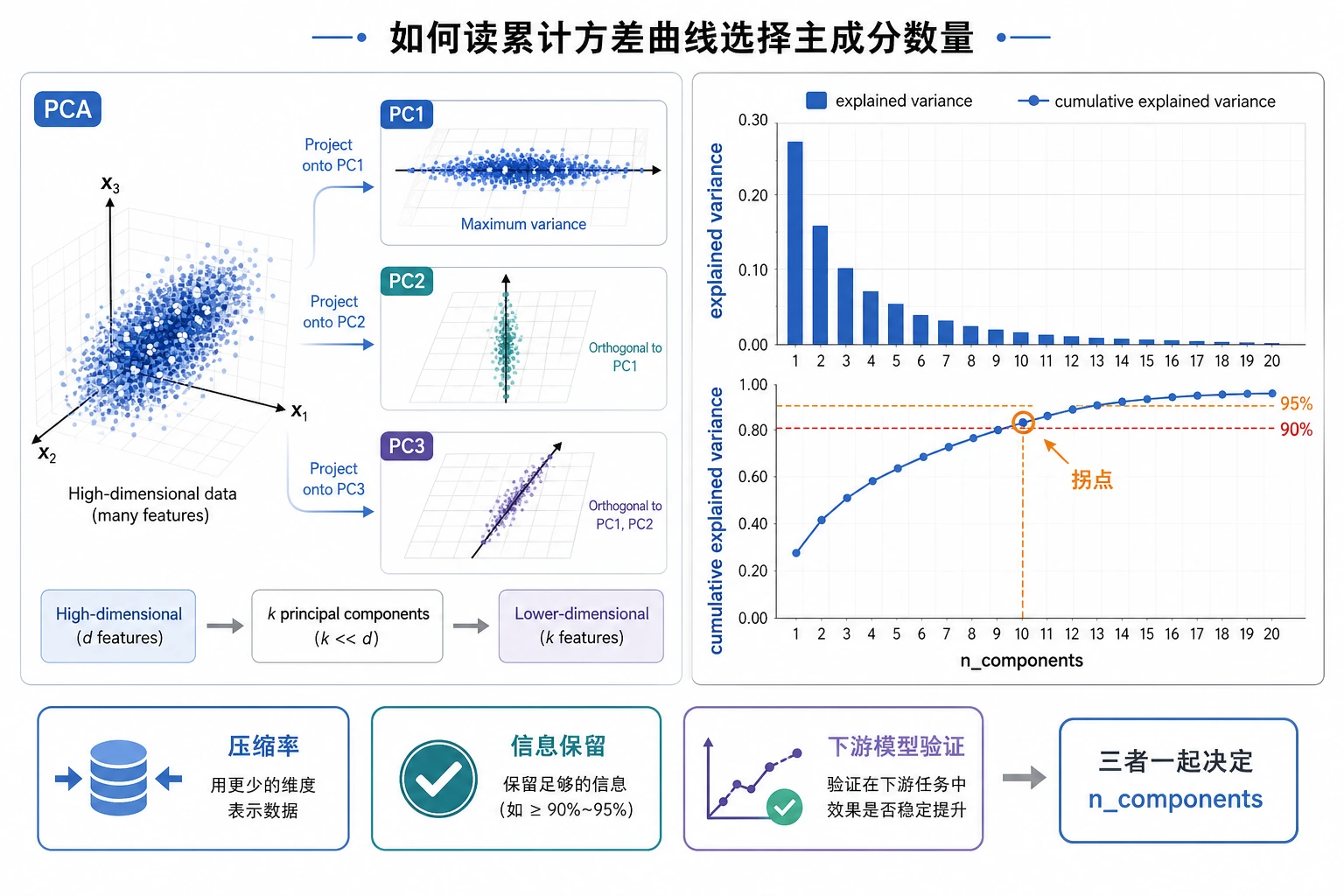
解释方差帮助你判断保留多少信息:
components=10 variance=0.591 accuracy=0.858
components=20 variance=0.791 accuracy=0.942
components=40 variance=0.953 accuracy=0.960
重点不是“永远保留 95%”。更实用的判断是:
- 如果目标是可视化,
2或3个成分可能足够; - 如果目标是建模,要比较 accuracy 或项目真正使用的指标;
- 如果目标是压缩,要比较重建误差和存储成本。
重建误差
重建是在问:压缩以后,还能多大程度还原原始数据?
components=10 reconstruction_mse=0.390
components=40 reconstruction_mse=0.045
成分越多,重建越好,但维度也越多。合适数量取决于紧凑程度和有用信息之间的取舍。
模型流水线中的 PCA
建模部分使用:
Pipeline([
("scale", StandardScaler()),
("pca", PCA(n_components=n, random_state=42)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
顺序很重要:
- 先切分 train/test;
- 只在训练数据上 fit 缩放器;
- 只在训练数据上 fit PCA;
- 用压缩后的训练特征训练模型;
- 在转换后的测试特征上评估。
把缩放和 PCA 放进 pipeline,可以防止交叉验证中的数据泄漏。
PCA、t-SNE 与 UMAP
| 方法 | 最适合用途 | 重要提醒 |
|---|---|---|
| PCA | 压缩、预处理、快速 2D 概览 | 线性方法,可能错过弯曲结构 |
| t-SNE | 局部邻域可视化 | 远距离簇之间的相对位置容易被误读 |
| UMAP | embedding 可视化和邻域探索 | 需要额外包,要调参数并检查稳定性 |
新手最安全的顺序:
- 先用 PCA,因为快且可解释。
- 用 t-SNE 或 UMAP 做可视化,不要一开始就当生产特征管道。
- 如果降维改变模型结果,必须用交叉验证确认。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| PCA 结果被某个特征主导 | 特征没有缩放 | PCA 前使用 StandardScaler |
| 2D 图很好看但模型很弱 | 2D 保留方差太少 | 建模时保留更多成分 |
| PCA 后准确率大幅下降 | 丢掉了太多有用特征 | 增加 n_components,和无 PCA 基线对比 |
| 交叉验证分数好得不正常 | 切分前就 fit 了 PCA | 把 PCA 放进 Pipeline |
| 过度解读 t-SNE/UMAP 图 | 可视化布局不是证明 | 检查稳定性和下游用途 |
练习
- 把 PCA 成分改成
[5, 15, 30, 50]。accuracy 从哪里开始提升变慢? - 不使用 PCA 直接训练分类器。PCA 帮的是速度、准确率,还是压缩?
- 去掉
StandardScaler。解释方差有什么变化? - 使用
PCA(n_components=0.95),打印自动选择了多少个成分。 - 用 2D PCA 输出画散点图,并按数字标签上色。
过关检查
你能解释下面几点,就完成本节:
- PCA 会生成新的压缩特征,叫 components;
- 2D PCA 适合可视化,但可能丢掉太多建模信息;
- 解释方差是参考,不是自动目标;
- PCA 必须在训练 pipeline 中 fit;
- t-SNE 和 UMAP 主要用于可视化,除非你做了严格验证。