7.4.4 预训练工程【选修】
如果说前两节在回答:
- 用什么数据
- 训练什么目标
这一节回答的就是:
当数据和模型都大到单机单卡不现实的时候,预训练到底怎样才能持续、稳定地跑下去。
这里的重点不是让你现在就去搭一个百卡集群, 而是先建立最重要的工程直觉:
- 为什么要分片
- 为什么要流式读取
- 为什么 checkpoint 和恢复不是附属功能
- 为什么吞吐稳定性本身就是训练质量的一部分
学习目标
- 理解预训练工程和普通小实验最大的差别在哪里
- 理解数据分片、流式读取、checkpoint 恢复的必要性
- 通过一个可运行示例看懂“中断后如何恢复训练状态”
- 建立对吞吐、故障恢复和数据版本管理的基本认识
一、为什么预训练很快会从“写模型”变成“做系统”?
因为数据大、时间长、失败成本高
小实验时,你可能只训练:
- 几千步
- 一个本地数据集
- 几分钟或几小时
但预训练通常意味着:
- 很长的训练周期
- 很大的数据量
- 很多分片
- 很高的中断代价
这时真正难的地方不再只是模型 forward 正不正确, 而是:
- 数据能不能稳定供给
- 训练中断后能不能恢复
- 每一步吞吐是否平稳
一个类比:不是跑一次程序,而是运营一条生产线
预训练更像一条工厂产线:
- 数据分片像原材料仓库
- dataloader 像传送带
- checkpoint 像生产进度存档
- 故障恢复像停电后复工
只要任一环节不稳, 整体成本就会迅速放大。
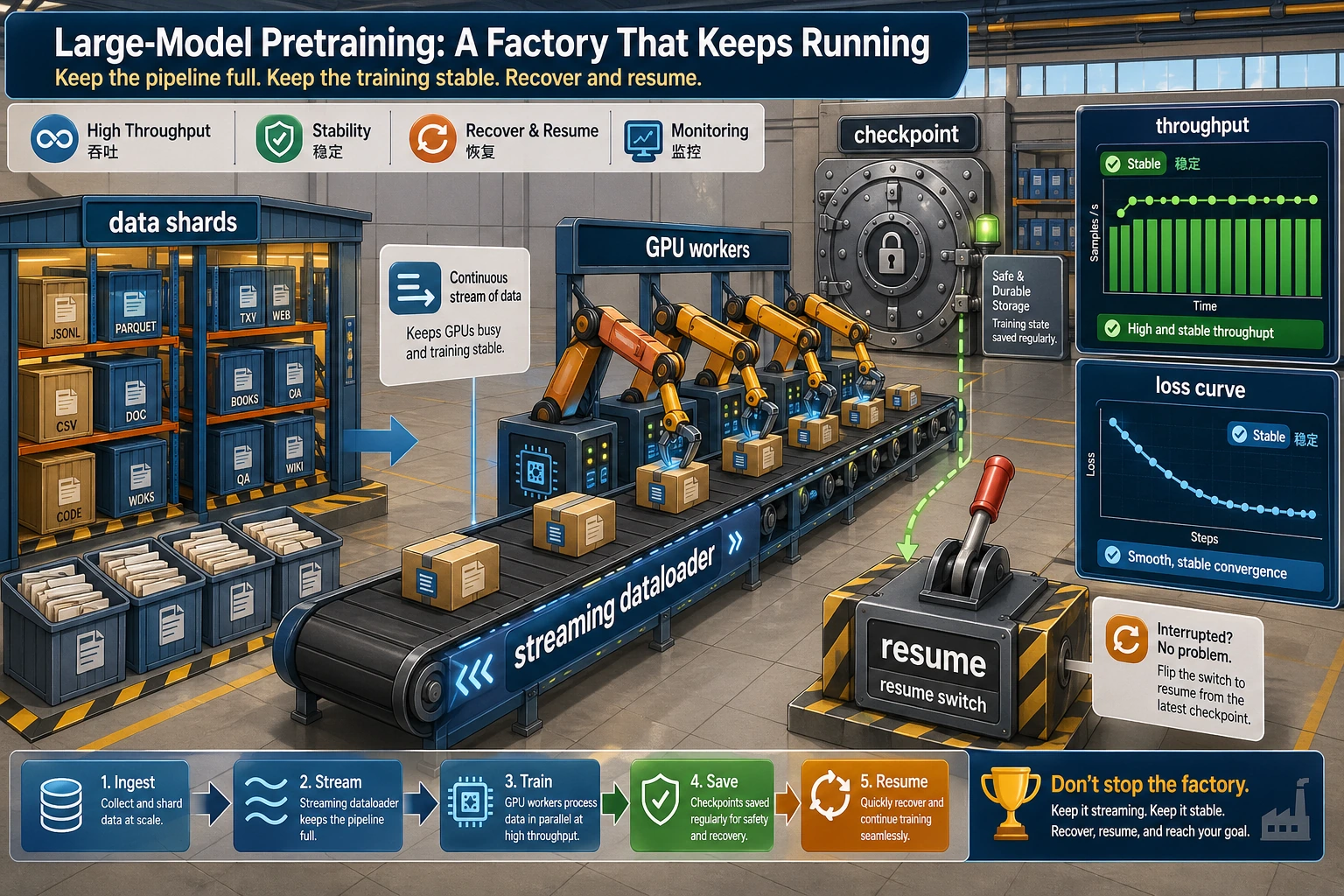
这张图把预训练看成一条生产线:shards 是原材料仓库,streaming dataloader 是传送带,checkpoint 是进度存档,resume 是停电后复工。预训练工程的关键不是“能跑一次”,而是能长期稳定地跑下去。
二、预训练工程里最关键的三个问题
数据怎么喂进去?
当数据量非常大时, 通常不会一次性全部读入内存,而会采用:
- 分片存储
- 流式读取
- 边读边打包成 token block
训练中断怎么办?
长时间训练几乎不可能保证永不出故障。 因此 checkpoint 不只是“顺手保存一下”, 而是必须具备:
- 模型参数
- 优化器状态
- 全局步数
- 数据读取位置
只有这样,中断后才不会乱套。
吞吐为什么重要?
因为预训练非常吃时间。 如果每秒 token 吞吐不稳定, 你训练计划和成本估算都会漂。
工程上常常会持续盯:
- tokens/s
- step time
- data wait time
- GPU 利用率
三、先跑一个“分片 + 恢复”的最小示例
下面这个示例会模拟一条非常小的预训练数据流:
- 数据按 shard 分片
- 每次取一个 batch
- 训练到一半“中断”
- 记录状态后恢复
虽然只是玩具版,但它抓住了预训练工程最关键的恢复逻辑。
shards = {
"shard_00": ["doc_0", "doc_1", "doc_2"],
"shard_01": ["doc_3", "doc_4", "doc_5"],
"shard_02": ["doc_6", "doc_7", "doc_8"],
}
def stream_batches(shard_map, batch_size, state=None):
shard_names = sorted(shard_map)
shard_index = 0 if state is None else state["shard_index"]
sample_index = 0 if state is None else state["sample_index"]
global_step = 0 if state is None else state["global_step"]
while shard_index < len(shard_names):
shard_name = shard_names[shard_index]
shard_data = shard_map[shard_name]
while sample_index < len(shard_data):
batch = shard_data[sample_index: sample_index + batch_size]
next_sample_index = sample_index + batch_size
next_state = {
"shard_index": shard_index,
"sample_index": next_sample_index,
"global_step": global_step + 1,
}
if next_sample_index >= len(shard_data):
next_state["shard_index"] = shard_index + 1
next_state["sample_index"] = 0
yield shard_name, batch, next_state
sample_index = next_sample_index
global_step += 1
shard_index += 1
sample_index = 0
saved_state = None
print("first run:")
for shard_name, batch, state in stream_batches(shards, batch_size=2):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
if state["global_step"] == 3:
saved_state = state
print("simulate crash, save state =", saved_state)
break
print("\nresume:")
for shard_name, batch, state in stream_batches(shards, batch_size=2, state=saved_state):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
预期输出:
first run:
step=01 shard=shard_00 batch=['doc_0', 'doc_1']
step=02 shard=shard_00 batch=['doc_2']
step=03 shard=shard_01 batch=['doc_3', 'doc_4']
simulate crash, save state = {'shard_index': 1, 'sample_index': 2, 'global_step': 3}
resume:
step=04 shard=shard_01 batch=['doc_5']
step=05 shard=shard_02 batch=['doc_6', 'doc_7']
step=06 shard=shard_02 batch=['doc_8']

这段代码为什么比“列几个 shard 名字”有教学价值?
因为它对应了预训练里最真实的一个问题:
- 如果训练跑到一半挂了,恢复后该从哪里接着读?
如果你只保存模型参数,不保存数据位置, 恢复后就可能:
- 重复吃同一批数据
- 或直接跳过一段数据
这两种都会影响训练稳定性。
为什么 state 里要同时记录三个东西?
这里保存了:
shard_indexsample_indexglobal_step
它们分别回答:
- 读到哪个分片了
- 分片里读到哪里了
- 训练进度走到哪一步了
这就是最小可恢复状态。
真实工程里还会多保存什么?
通常还包括:
- 模型参数
- 优化器状态
- 学习率调度状态
- 随机种子
- 混合精度 scaler
四、为什么数据分片几乎是默认做法?
因为数据不可能一次性全装进内存
当语料达到 TB 级别时, “全部读进来再训练”是根本不现实的。
所以会把数据拆成很多 shard:
- 更方便并行读取
- 更方便故障恢复
- 更方便版本管理
分片还能帮助多 worker 并行
多卡或多 worker 训练时, 可以让不同 worker:
- 读取不同 shard
- 或读取同一 shard 的不同区段
这会让数据供给更稳定。
一个很常见的坑:分片太不均匀
如果某些 shard 特别大、某些特别小, 就容易出现:
- 某些 worker 很快读完
- 某些 worker 一直拖后腿
最终表现成:
- 吞吐抖动
- GPU 等数据
五、为什么流式读取比“先全 tokenize 完再读”更现实?
因为预处理本身也可能很贵
大规模语料里,tokenization 也不是零成本。 如果你想一次性把全部数据处理完, 往往会遇到:
- 存储压力
- 数据版本切换困难
- 重跑成本高
于是很多系统会采用:
- 预先分片 + 流式读取
- 或部分预处理、部分在线处理
但流式读取也会带来新问题
例如:
- 数据顺序是否打乱充分
- 多 worker 是否重复读
- 断点恢复是否一致
这也是为什么数据管道本身要设计得很严谨。
六、吞吐为什么会直接影响训练效果?
吞吐不稳意味着很多资源被浪费
如果每一步训练时间忽快忽慢, 常见原因可能是:
- dataloader 太慢
- shard 切换成本高
- I/O 抖动
- worker 负载不均
这会直接拖慢总训练时间。
更隐蔽的问题:训练计划会失真
预训练常按:
- 训练 token 总量
- 预计 wall time
- 预计 checkpoint 节点
来规划。
如果吞吐不稳定, 你的:
- 学习率计划
- checkpoint 周期
- 预算估算
都可能跟着漂。
一个极简吞吐日志示例
step_logs = [
{"step": 1, "tokens": 8192, "seconds": 0.40},
{"step": 2, "tokens": 8192, "seconds": 0.39},
{"step": 3, "tokens": 8192, "seconds": 0.78},
]
for log in step_logs:
tps = log["tokens"] / log["seconds"]
print(f"step={log['step']} tokens/s={tps:.0f}")
预期输出:
step=1 tokens/s=20480
step=2 tokens/s=21005
step=3 tokens/s=10503

如果你看到第 3 步明显掉下去, 工程上就要继续追:
- 是 I/O 问题
- 还是计算问题
七、预训练工程最容易被忽视的两件事
数据版本管理
如果你说不清:
- 当前训练到底用了哪一版数据
- 清洗规则是什么
- 混合比例怎么配的
那后面效果变化几乎无法归因。
可恢复性测试
很多团队会认真测:
- 模型能不能训
却不认真测:
- 中断后能不能稳稳恢复
但对长时间训练来说, 恢复能力往往是必需项,不是附加项。
八、常见误区
误区一:先把模型写对,工程以后再补
对预训练来说,工程不是后期装饰, 而是能不能把实验真正跑起来的前提。
误区二:checkpoint 只保存模型参数就够了
不够。 缺少数据位置和优化器状态,恢复后很可能不一致。
误区三:吞吐只是成本问题,不影响训练质量
吞吐本身不直接决定 loss, 但它会影响训练计划、稳定性和资源利用, 间接影响整体效果和实验节奏。
小结
这节最重要的不是记住多少分布式术语, 而是先建立一个现实判断:
预训练不是一段长一点的脚本,而是一条必须能持续供数、能断点恢复、能稳定吞吐的系统工程链。
只要这层意识建立起来, 你以后再看:
- 数据分片
- streaming
- checkpoint
- 吞吐监控
这些环节时,就不会把它们当成“外围杂务”了。
练习
- 把示例里的
batch_size改成1或3,观察恢复状态会怎样变化。 - 为什么说只保存模型参数,不保存数据读取位置,会让恢复训练变得不可靠?
- 想一想:如果某些 shard 特别大、某些特别小,会对吞吐造成什么影响?
- 用自己的话解释:为什么预训练工程最终会变成“做系统”而不只是“写模型”?