6.6.3 VAE 基础 [选修]
本节定位
VAE 是一种生成式 autoencoder。它不是把每个输入压缩成一个固定点,而是在 latent space 中学习一个小分布,从中采样,再把采样结果解码回数据。
学习目标
- 解释 encoder、
mu、logvar、latent samplez和 decoder。 - 理解 VAE 为什么需要 reparameterization。
- 在 2D 点数据上跑通一个极小 PyTorch VAE。
- 读懂 reconstruction loss 和 KL regularization。
- 比较 VAE、标准 autoencoder 和 GAN。
先看流程图
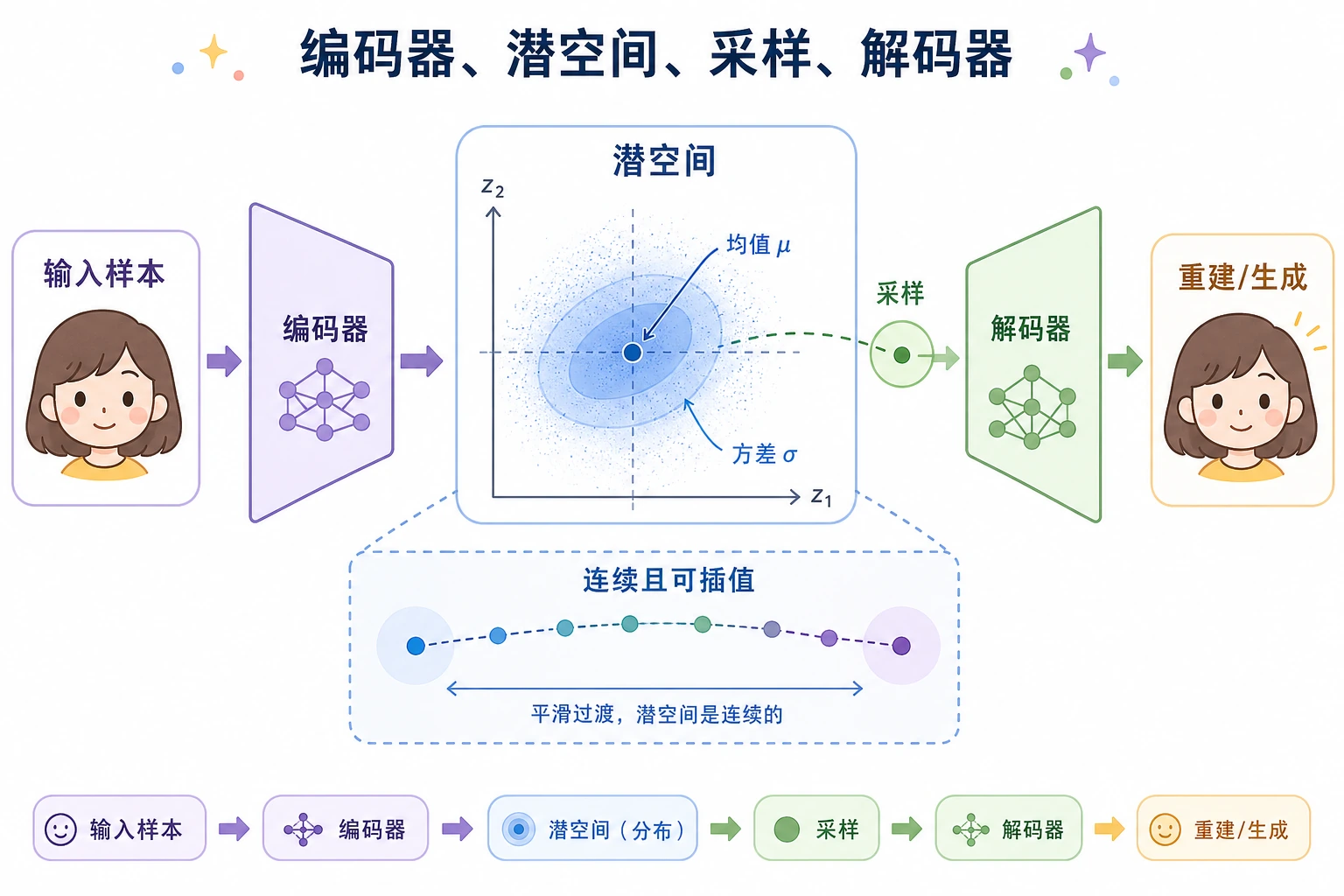
| 步骤 | 发生什么 | 实践含义 |
|---|---|---|
| Encode | x -> mu, logvar | 描述一个 latent 区域 |
| Sample | z = mu + eps * std | 让采样可微 |
| Decode | z -> reconstructed x | 把 latent code 还原成数据 |
| Regularize | KL 项 | 让 latent space 平滑、可采样 |
它和普通 autoencoder 的关键区别:
Autoencoder: x -> 一个 latent 点 -> reconstruction
VAE: x -> latent 分布 -> sample z -> reconstruction 或 generation
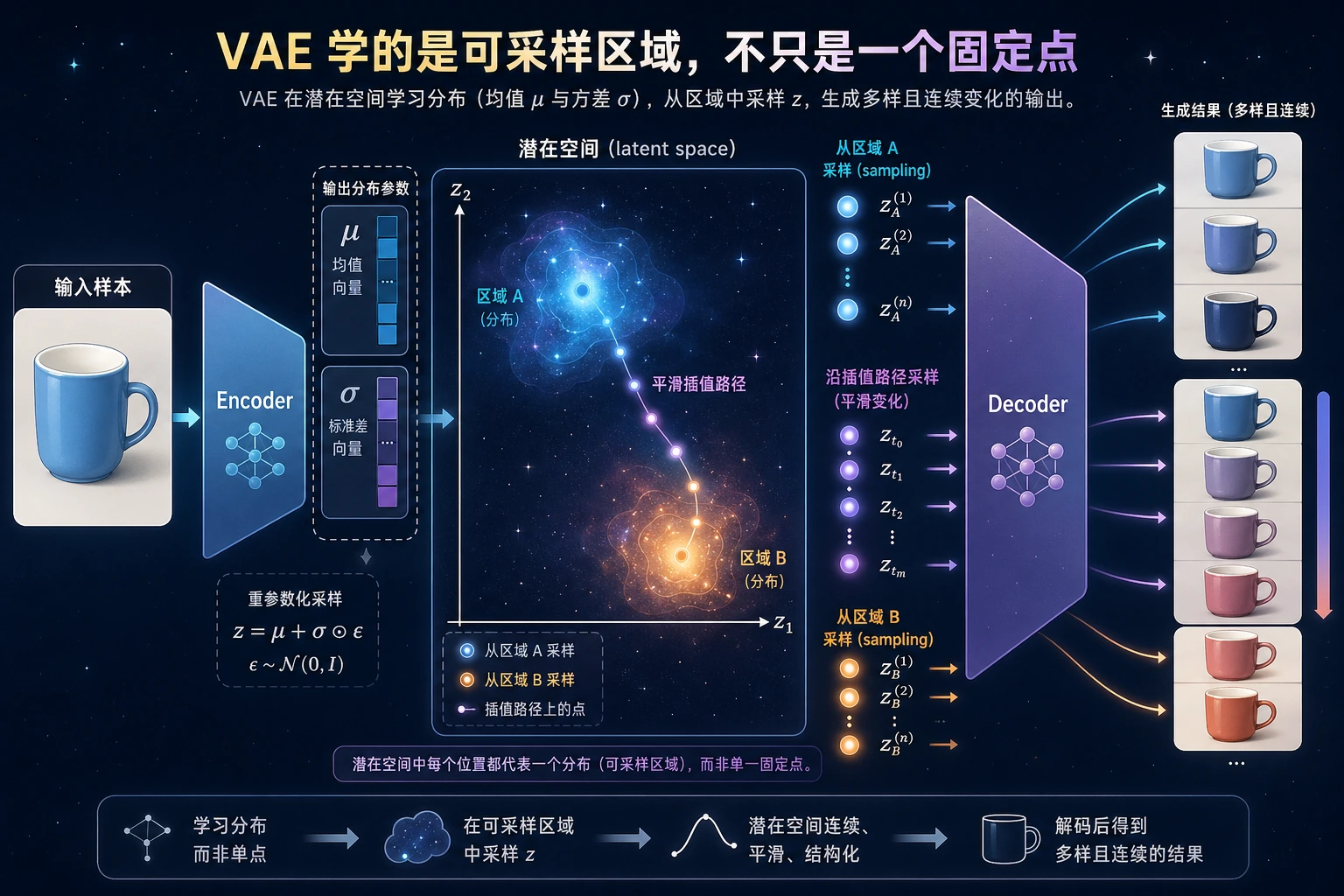
为什么需要 Reparameterization
采样有随机性。直接随机采样会挡住普通反向传播。VAE 把采样改写成:
std = exp(0.5 * logvar)
eps ~ N(0, 1)
z = mu + eps * std
这样梯度可以通过 mu 和 std 传回去,eps 只负责提供随机性。
VAE Loss
VAE 训练通常合并两个目标:
loss = reconstruction_loss + beta * KL(q(z|x) || p(z))
白话解释:
- reconstruction loss:decoder 能不能重建输入?
- KL 项:latent space 是否接近像 N(0, 1) 这样的平滑先验?
beta:你要多强地约束 latent space 变规整。
KL 压力太小,latent space 可能很乱。KL 压力太大,重建可能变差,甚至 latent 变量带的信息太少。
实验:在 2D 点上训练一个极小 VAE
这不是图像 VAE,而是一个能跑通完整机制的小实验。
创建 tiny_vae_2d.py:
import torch
from torch import nn
torch.manual_seed(4)
cluster_a = torch.randn(128, 2) * 0.15 + torch.tensor([1.0, 0.0])
cluster_b = torch.randn(128, 2) * 0.15 + torch.tensor([-1.0, 0.0])
x = torch.cat([cluster_a, cluster_b], dim=0)
class TinyVAE(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(nn.Linear(2, 16), nn.ReLU())
self.mu = nn.Linear(16, 2)
self.logvar = nn.Linear(16, 2)
self.decoder = nn.Sequential(nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 2))
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
h = self.encoder(x)
mu = self.mu(h)
logvar = self.logvar(h)
z = self.reparameterize(mu, logvar)
recon = self.decoder(z)
return recon, mu, logvar
model = TinyVAE()
opt = torch.optim.Adam(model.parameters(), lr=0.02)
for epoch in range(1, 201):
recon, mu, logvar = model(x)
recon_loss = ((recon - x) ** 2).mean()
kl = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
loss = recon_loss + 0.05 * kl
opt.zero_grad()
loss.backward()
opt.step()
if epoch in [1, 50, 100, 200]:
print(
f"epoch={epoch:03d} "
f"recon={recon_loss.item():.4f} "
f"kl={kl.item():.4f} "
f"loss={loss.item():.4f}"
)
with torch.no_grad():
z = torch.randn(5, 2)
samples = model.decoder(z)
rounded = [[round(v, 3) for v in row.tolist()] for row in samples]
print("generated_points")
print(rounded)
运行:
python tiny_vae_2d.py
预期输出:
epoch=001 recon=0.5903 kl=0.0293 loss=0.5917
epoch=050 recon=0.0335 kl=0.9007 loss=0.0785
epoch=100 recon=0.0261 kl=0.8229 loss=0.0673
epoch=200 recon=0.0244 kl=0.7138 loss=0.0601
generated_points
[[1.075, -0.014], [-0.997, -0.001], [-1.118, -0.054], [0.553, 0.041], [0.74, 0.021]]
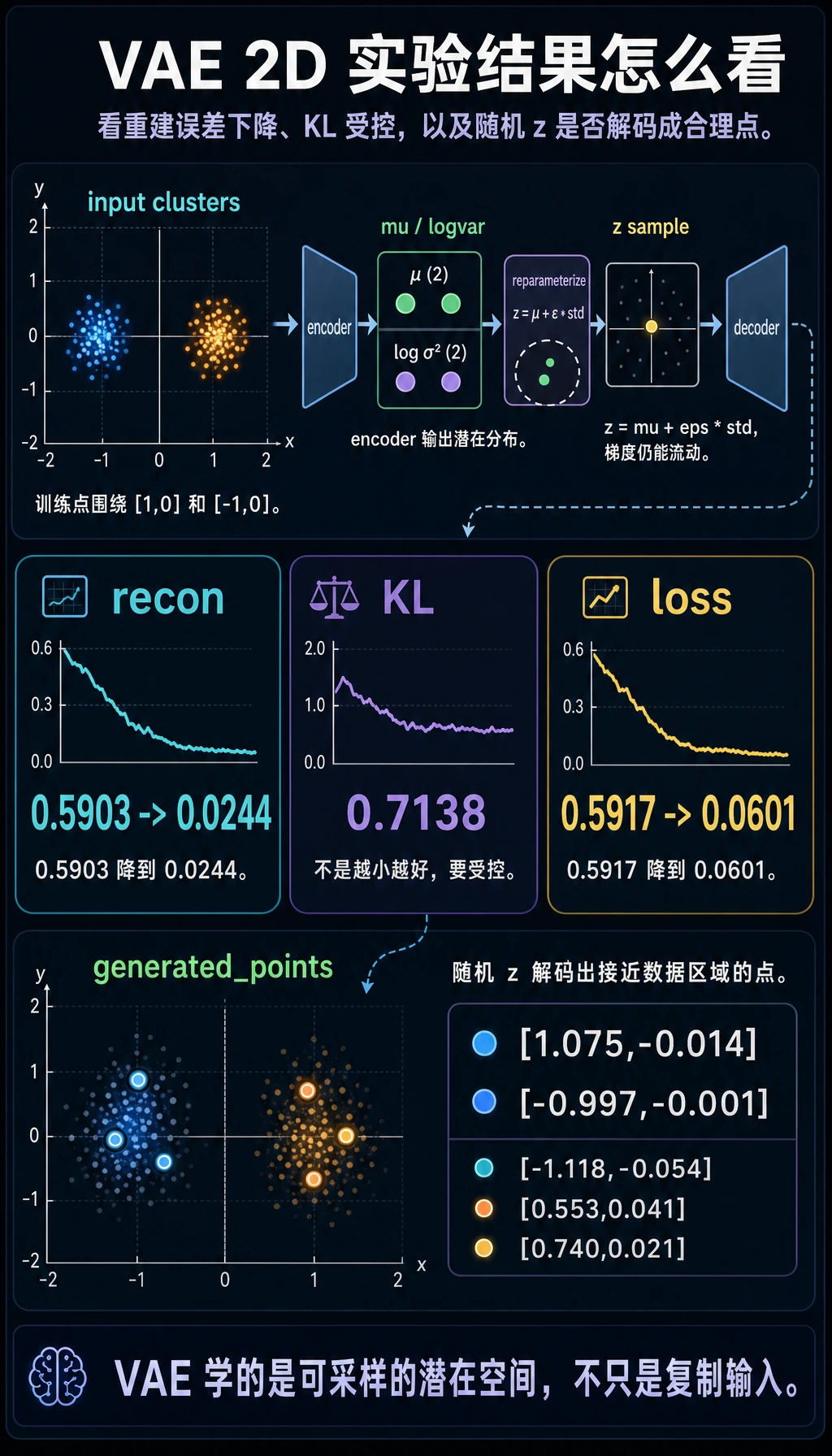
读输出:
recon下降,说明 decoder 学会了重建 2D 点。kl不需要变成 0。它是把 latent space 推向平滑先验的压力。generated_points是从随机z解码出来的,不是直接复制训练数据。
VAE、Autoencoder 与 GAN
| 模型 | 学什么 | 优点 | 常见弱点 |
|---|---|---|---|
| Autoencoder | 紧凑表示 | 重建 | latent space 不一定容易采样 |
| VAE | 有分布形状的 latent space | 平滑采样和插值 | 图像任务中可能偏模糊 |
| GAN | 对抗式真实感 | 样本可能更锐利 | 训练不稳定,容易 mode collapse |
实践诊断
| 信号 | 健康方向 | 警告信号 |
|---|---|---|
| reconstruction loss | 下降并稳定 | 一直很高 |
| KL 项 | 非零但可控 | 塌到 0 或主导 loss |
| 生成样本 | 合理且多样 | 全都相似或无意义 |
| 插值 | 平滑变化 | 跳变或离开数据区域 |
常见深度学习权衡:
更好重建 <-> 更规整的 latent space
你通常用 KL 权重调这个平衡,在 beta-VAE 中常叫 beta。
常见错误
| 错误 | 修复 |
|---|---|
| 以为 VAE 只是 autoencoder 加噪声 | 重点看 mu、logvar、KL 和可采样 latent space |
| 忽略 reparameterization | 记住 z = mu + eps * std 让梯度继续流动 |
| 太早把 KL 压得太强 | 可尝试更小 beta 或 KL warmup |
| 只看 reconstruction | 同时看生成样本和插值 |
| 只用图像清晰度比较 VAE 与 GAN | 同时比较稳定性、latent 结构和任务适配 |
练习
- 把 KL 权重从
0.05改成0.0。kl和生成样本会怎样? - 把 KL 权重改成
0.5。重建会变差吗? - 解码从
[-2, 0]到[2, 0]的一条线。输出是否平滑变化? - 把 decoder 里的
ReLU换成Tanh。训练还能收敛吗? - 解释为什么即使 GAN 或 diffusion 图像更锐利,VAE 仍然适合学习 latent-space 直觉。
小结
- VAE 学的是 latent 分布,而不只是固定 code。
- Reparameterization 让采样能配合反向传播。
- KL 项让 latent space 更平滑、更可采样。
- VAE 通常比 GAN 更容易训练,但可能用结构换掉一部分锐利度。
- 理解 VAE 会让后面的 diffusion 和表示学习更容易。