6.6.2 GAN 基础 [选修]
本节定位
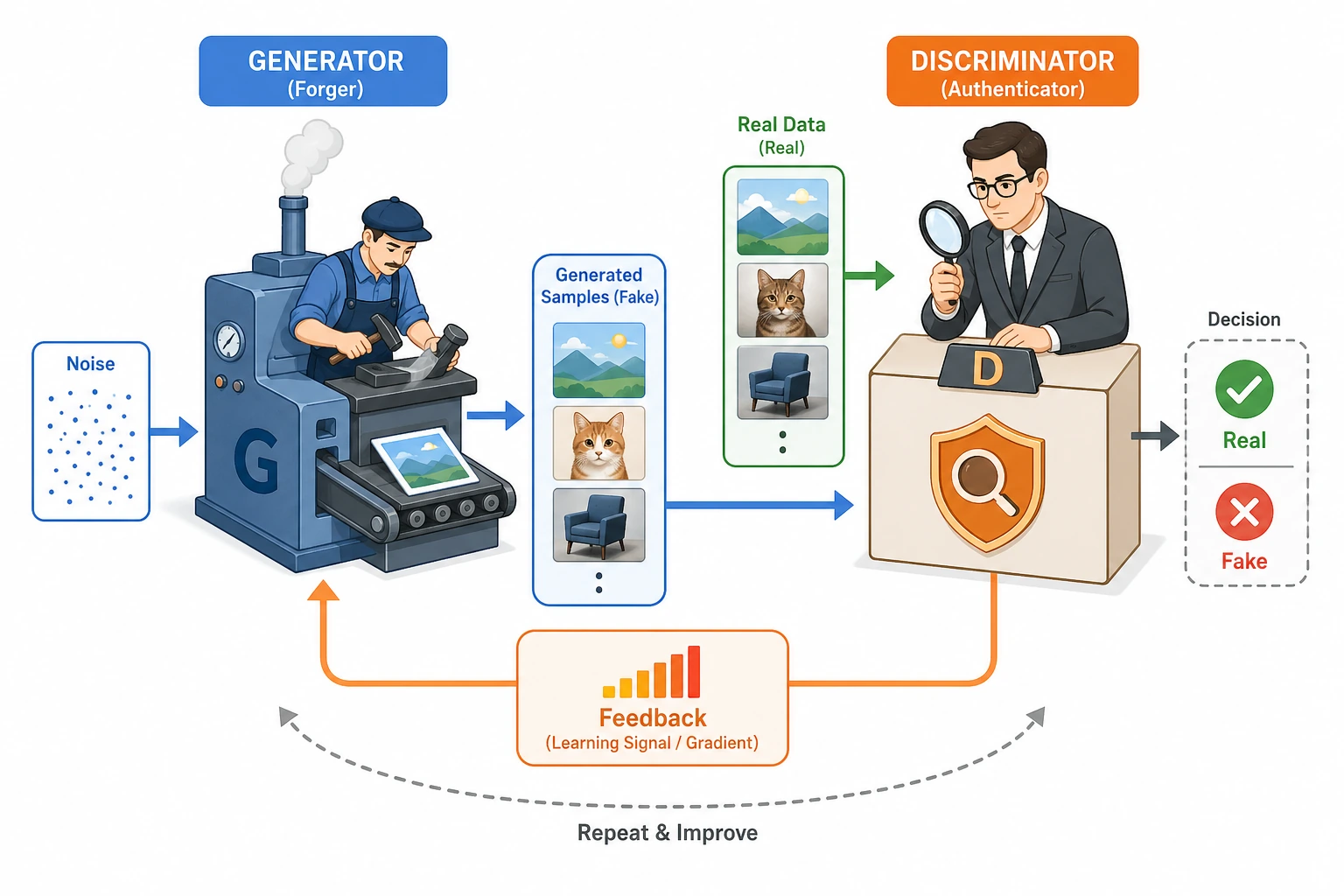
GAN 是一个双人训练循环:generator 试图造出看起来真实的假样本,discriminator 试图区分真假。它的能力和不稳定性来自同一个地方:两边都在变化。
学习目标
- 解释 generator 和 discriminator 的角色。
- 在 1D 数据上跑通一个最小 PyTorch GAN。
- 用
loss_d、loss_g、fake_mean、fake_std观察训练。 - 识别 mode collapse 和 D/G 失衡。
- 知道什么时候 GAN 值得用,什么时候 diffusion 或其他生成方法更适合作为默认选择。
先看这场游戏
| 部件 | 输入 | 输出 | 目标 |
|---|---|---|---|
Generator G | 随机噪声 z | 假样本 | 让假样本看起来像真的 |
Discriminator D | 真样本或假样本 | 真/假分数 | 区分真假 |
| 训练循环 | G 和 D 的更新 | 不断变化的游戏 | 让两边都继续学习 |
GAN 不是像普通分类那样只对一个固定标签目标训练。discriminator 会改变“什么样的假样本难以识别”,generator 也会改变假样本长什么样。

实操循环
一个 GAN step 可以读成两次更新:
1. 训练 D:real -> real,G(z).detach() -> fake
2. 训练 G:G(z) 要让 D 说 real
discriminator 这一步里的 .detach() 很重要。它防止更新 D 时误把 generator 也改掉。
实验:训练一个极小 1D GAN
这个例子不生成图片,而是用中心在 2.0 附近的 1D 分布演示训练机制。
创建 tiny_gan_1d.py:
import torch
from torch import nn
torch.manual_seed(7)
def real_batch(n):
return torch.randn(n, 1) * 0.2 + 2.0
G = nn.Sequential(nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1))
D = nn.Sequential(nn.Linear(1, 16), nn.ReLU(), nn.Linear(16, 1))
loss_fn = nn.BCEWithLogitsLoss()
opt_g = torch.optim.Adam(G.parameters(), lr=0.01)
opt_d = torch.optim.Adam(D.parameters(), lr=0.01)
for step in range(1, 301):
real = real_batch(64)
z = torch.randn(64, 2)
fake = G(z).detach()
d_real = D(real)
d_fake = D(fake)
loss_d = loss_fn(d_real, torch.ones_like(d_real)) + loss_fn(
d_fake, torch.zeros_like(d_fake)
)
opt_d.zero_grad()
loss_d.backward()
opt_d.step()
z = torch.randn(64, 2)
fake = G(z)
d_fake = D(fake)
loss_g = loss_fn(d_fake, torch.ones_like(d_fake))
opt_g.zero_grad()
loss_g.backward()
opt_g.step()
if step in [1, 100, 200, 300]:
with torch.no_grad():
sample = G(torch.randn(256, 2))
print(
f"step={step:03d} "
f"loss_d={loss_d.item():.3f} "
f"loss_g={loss_g.item():.3f} "
f"fake_mean={sample.mean().item():.3f} "
f"fake_std={sample.std().item():.3f}"
)
运行:
python tiny_gan_1d.py
预期输出:
step=001 loss_d=1.579 loss_g=0.844 fake_mean=0.025 fake_std=0.117
step=100 loss_d=1.287 loss_g=0.654 fake_mean=1.093 fake_std=0.204
step=200 loss_d=1.460 loss_g=0.835 fake_mean=2.988 fake_std=0.291
step=300 loss_d=1.307 loss_g=0.630 fake_mean=1.384 fake_std=0.056
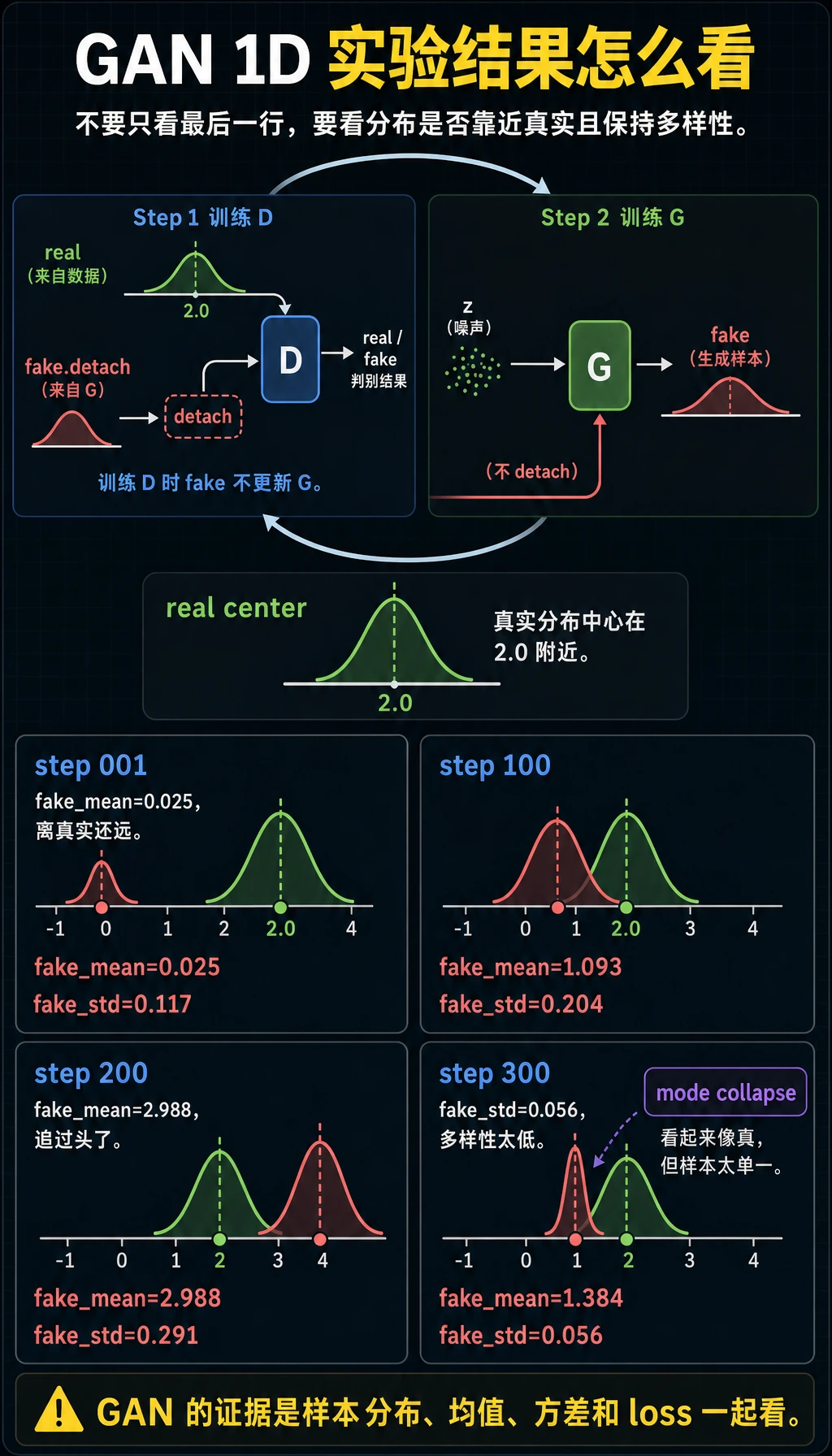
不要把最后一行当成“最好”。这更像一个诊断实验:
- 真实样本中心在
2.0附近; fake_mean会来回移动,因为G和D在互相追逐;fake_std很小时,要警惕多样性不足;- GAN 的 loss 曲线通常不能脱离样本观察来解释。
什么是 Mode Collapse
Mode collapse 指 generator 找到一种狭窄技巧骗过 discriminator,然后反复生成非常相似的样本。
在图片中,你可能会看到很多几乎同姿态的人脸。在 1D 实验里,特别小的 fake_std 可以作为简单的 collapse 信号。
看起来像真的,但缺少多样性 -> 怀疑 mode collapse
为什么 GAN 难训练
| 问题 | 表现 | 第一反应 |
|---|---|---|
| Discriminator 太强 | G 收不到有用反馈 | 降低 D 更新次数或容量 |
| Generator 太弱 | 假样本不变好 | 调学习率、架构、归一化 |
| Mode collapse | 样本变得重复 | 监控多样性,使用更强 loss 或正则 |
| Loss 有误导性 | loss 变化但样本变差 | 保存样本网格并比较版本 |
| 评估模糊 | “看起来不错”太主观 | 结合视觉检查、多样性和任务指标 |
什么时候值得学 GAN
GAN 仍然值得学,因为它能非常清楚地展示对抗学习、分布匹配和失败诊断。
对现代图像生成项目来说,diffusion 往往更稳定、更容易控制。GAN 特别适合用来理解:
- 训练后快速采样;
- adversarial realism signal;
- 生成样本多样性;
- 不稳定多目标训练的具体例子。
常见错误
| 错误 | 修复 |
|---|---|
只看 loss_g 和 loss_d | 同时看生成样本和多样性 |
在训练 D 时也更新了 G | 使用 G(z).detach() |
让 D 太早接近完美 | 调容量、更新比例、学习率 |
| 忽略重复输出 | 跟踪多样性和 mode collapse |
| 把 GAN 当所有生成任务的默认方法 | 和 VAE、diffusion、自回归方法比较 |
练习
- 把真实数据中心从
2.0改成-1.0。fake_mean会移动吗? - 把
lr从0.01降到0.001。训练更平滑还是更慢? - 把 hidden size 从
16增加到64。训练游戏更稳定吗? - 每 25 step 打印一次
fake_std,标出可能 collapse 的位置。 - 解释为什么 GAN 不能只靠一个 loss 数字判断输出质量。
小结
- GAN 训练是一场不断移动的双人游戏。
G学生成样本,D学判断真假。- 不稳定性是训练设定的一部分,不只是代码 bug。
- Mode collapse 是“像真但不多样”。
- 即使生产中可能选别的生成模型,GAN 仍然非常值得理解。