4.1.5 向量空间与线性变换【选修】
本节内容帮助你加深理解。如果你只想快速上手 AI 项目,可以先跳过,后续遇到相关概念再回来看。
学习目标
- 理解线性无关、基、维度的含义
- 理解线性变换的矩阵表示
- 直觉理解奇异值分解(SVD)
先说一个很重要的学习预期
这一节是选修,名字也更抽象,所以新人特别容易一上来就掉速。 你这节最重要的目标,不是把线性代数高级理论全部吃透,而是先建立一个更高层的视角:
- 前面那些向量、矩阵、特征值,到底在更大框架里分别是什么
- 为什么“维度、基、线性无关”这些词会在后面的 AI 里反复出现
- 为什么 SVD 会成为很多方法的底层工具
也就是说,这一节更像:
把前面三节的直觉整理成一个更高层的理解框架。
这节和前面三节是什么关系?
如果你前面三节学的是“向量怎么表示、矩阵怎么变换、特征值怎么找特殊方向”,那这一节就是把这些内容抬高一个视角来重新看。

所以这节课更像“加深理解的整理课”,不是必须第一时间全部吃透,但学懂之后,你会更知道前面那些概念为什么成立。
先把这些缩写和记号看懂
| 术语 | 英文全称 | 新人理解 |
|---|---|---|
SVD | Singular Value Decomposition | 奇异值分解,把矩阵拆成方向、强弱和重构步骤 |
PCA | Principal Component Analysis | 主成分分析,找出数据中最重要的方向,并用更少维度表示 |
NLP | Natural Language Processing | 自然语言处理,处理文本和语言的 AI 方法 |
LSA | Latent Semantic Analysis | 潜在语义分析,用 SVD 寻找文本中的隐藏主题结构 |
V^T / Vt | V transpose | V 的转置,把 V 的行和列互换;NumPy 里常写作 Vt |
rank | Matrix rank | 矩阵真正包含多少个相互独立的方向 |
basis | Basis vectors | 一组最小、不冗余、足够描述空间的坐标方向 |
span | Span of vectors | 用给定向量不断组合,所有能够到达的位置 |
orthogonal | Perpendicular / independent directions | 方向互不重叠;在 AI 里常表示信息分得更干净 |
full_matrices=False | Compact SVD mode | 让 NumPy 只返回有用的紧凑部分,后续矩阵形状更容易相乘 |
np.linalg | NumPy linear algebra module | NumPy 里的线性代数工具区,包含秩、解方程、特征值和 SVD 等函数 |
| 低秩近似 | Low-rank approximation | 只保留最重要的奇异值,丢掉较弱细节,用更少信息近似原矩阵 |
本节代码运行前提:下面的代码按 Notebook 风格编写。如果你按顺序运行,后面的代码块可以复用前面定义过的 np、plt 和变量。如果你把某一段单独复制到新的 .py 文件里,请先加上:
import numpy as np
import matplotlib.pyplot as plt
np 是 NumPy 的常用缩写,NumPy 是 Python 里处理数组和线性代数的基础库。plt 是 Matplotlib pyplot 的常用缩写,用来画图和做可视化。
一、线性无关——"不冗余"的向量
什么是线性无关?
直觉:一组向量是"线性无关"的,意味着每个向量都提供了独特的信息,没有谁是多余的。
一个更适合新人的类比
可以先把“线性无关”想成团队分工:
- 如果团队里每个人都带来不同能力,那就是不冗余
- 如果两个人做的是同一件事,其中一个其实就有点重复了
所以线性无关最值得先记的,不是严谨定义,而是这句:
这组向量里,有没有谁其实是在重复别人已经表达过的信息。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 线性无关的例子:向右 和 向上,方向完全不同
v1 = np.array([1, 0])
v2 = np.array([0, 1])
# 线性相关的例子:v2 只是 v1 的 2 倍,方向完全一样
u1 = np.array([1, 2])
u2 = np.array([2, 4]) # u2 = 2 * u1,冗余!
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 线性无关
ax = axes[0]
ax.quiver(0, 0, v1[0], v1[1], angles='xy', scale_units='xy', scale=1,
color='steelblue', width=0.01, label='v1 = [1, 0]')
ax.quiver(0, 0, v2[0], v2[1], angles='xy', scale_units='xy', scale=1,
color='coral', width=0.01, label='v2 = [0, 1]')
ax.set_xlim(-0.5, 2)
ax.set_ylim(-0.5, 2)
ax.set_aspect('equal')
ax.grid(True, alpha=0.3)
ax.legend()
ax.set_title('线性无关\n两个方向不同,无冗余')
# 线性相关
ax = axes[1]
ax.quiver(0, 0, u1[0], u1[1], angles='xy', scale_units='xy', scale=1,
color='steelblue', width=0.01, label='u1 = [1, 2]')
ax.quiver(0, 0, u2[0], u2[1], angles='xy', scale_units='xy', scale=1,
color='coral', width=0.01, label='u2 = [2, 4]')
ax.set_xlim(-0.5, 3)
ax.set_ylim(-0.5, 5)
ax.set_aspect('equal')
ax.grid(True, alpha=0.3)
ax.legend()
ax.set_title('线性相关\nu2 = 2×u1,完全冗余')
plt.tight_layout()
plt.show()
在 AI 中的意义
| 场景 | 线性无关的意义 |
|---|---|
| 特征工程 | 如果两个特征线性相关(如"温度(℃)"和"温度(℉)"),其中一个是冗余的 |
| PCA 降维 | 主成分之间互相正交(线性无关),每个主成分都提供独特信息 |
| 神经网络 | 如果权重矩阵的列线性相关,说明有些神经元是冗余的 |
用矩阵的秩判断
矩阵的秩(rank) = 矩阵中线性无关的行(或列)的最大数量。
# 3 列线性无关
A = np.array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]])
print(f"A 的秩: {np.linalg.matrix_rank(A)}") # 3(满秩)
# 第 3 列 = 第 1 列 + 第 2 列,冗余!
B = np.array([[1, 0, 1],
[0, 1, 1],
[0, 0, 0]])
print(f"B 的秩: {np.linalg.matrix_rank(B)}") # 2(不是满秩)
预期输出:
A 的秩: 3
B 的秩: 2
这里的“满秩”可以先理解为:没有哪一列是浪费的。矩阵 B 虽然有 3 列,但真正独立的方向只有 2 个,所以有效信息维度是 2。
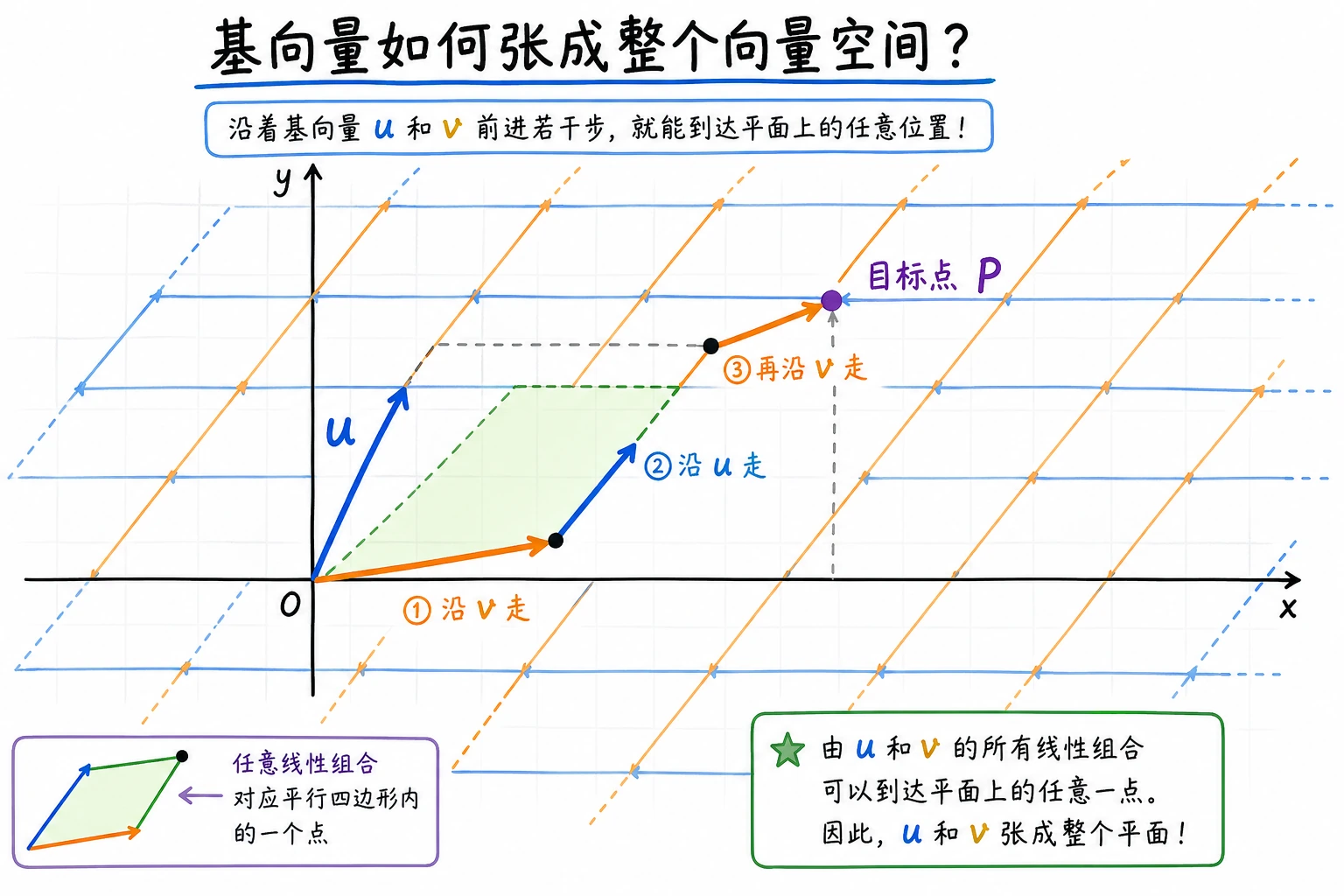
二、基与维度——描述空间的"坐标系"
基(Basis)
基 = 一组线性无关的向量,它们能"张成"整个空间(即任何向量都能用它们的组合表示)。
基最值得先记住的,不是术语,而是作用
你可以先把基理解成:
- 一套最小、够用、又不冗余的坐标系统
也就是说:
- 能表达所有目标
- 又没有多余方向
这正是后面很多 AI 方法为什么总在找“更好的表示基”的原因。
最常见的基是标准基:
# 二维空间的标准基
e1 = np.array([1, 0]) # x 方向
e2 = np.array([0, 1]) # y 方向
# 任何二维向量都可以用标准基表示
v = np.array([3, 5])
# v = 3 * e1 + 5 * e2
print(f"v = {v[0]} × e1 + {v[1]} × e2 = {v[0]*e1 + v[1]*e2}")
预期输出:
v = 3 × e1 + 5 × e2 = [3 5]
非标准基也可以:
# 换一组基
b1 = np.array([1, 1])
b2 = np.array([1, -1])
# v = [3, 5] 在新基下的坐标是?
# v = c1 * b1 + c2 * b2
# 解方程组
B = np.column_stack([b1, b2])
coords = np.linalg.solve(B, v)
print(f"在新基下的坐标: {coords}") # [4, -1]
# 验证: 4*[1,1] + (-1)*[1,-1] = [4,4]+[-1,1] = [3,5] ✓
预期输出:
在新基下的坐标: [ 4. -1.]
这就是最关键的直觉:向量本身没有移动,只是我们换了一套坐标系统来描述它。也正因为这样,“表示”才会成为 AI 里特别重要的词。
维度(Dimension)
维度 = 基向量的个数 = 描述空间需要的最少坐标数。
为什么“维度”在 AI 里会变成高频词?
因为 AI 里你经常会关心两件事:
- 当前表示到底有多少信息自由度
- 有没有可能把维度压低,但尽量少丢信息
所以维度在 AI 里,不只是个几何词, 它常常意味着:
- 计算成本
- 信息容量
- 模型复杂度
| 空间 | 维度 | 例子 |
|---|---|---|
| 直线 | 1 | 温度刻度 |
| 平面 | 2 | 地图上的位置 |
| 三维空间 | 3 | 现实世界的位置 |
| 词向量空间 | 100~300 | 每个词的"语义坐标" |
| 图片像素空间 | 几万~几百万 | 每个像素是一个维度 |
AI 中经常说"高维空间"——一张 28×28 的手写数字图片就是 784 维空间中的一个点。PCA 的本质就是找到一组新的"基"(主成分),让我们能用更少的维度(比如 2 维)来近似表示这些数据。
三、线性变换的矩阵表示
线性变换 = 矩阵
一个很深刻的结论:任何线性变换都可以用一个矩阵表示。
这一点为什么对 AI 特别重要?
因为它把很多看起来不同的事情,统一到了同一种表达里:
- 旋转
- 缩放
- 投影
- 一层神经网络
也就是说,很多 AI 里的“层”本质上都可以先看成:
- 某种线性变换 + 后续非线性处理
什么是线性变换?满足两个条件的变换 T:
- T(a + b) = T(a) + T(b)(加法可以"搬进搬出")
- T(ka) = k·T(a)(数乘可以"搬进搬出")
# 旋转、缩放、投影、剪切... 都是线性变换
# 看看标准基向量变换后去了哪里,就知道矩阵是什么
# 旋转 90° 的变换:
# e1 = [1, 0] → [0, 1]
# e2 = [0, 1] → [-1, 0]
# 把变换后的基向量排成列,就是变换矩阵!
R90 = np.array([[0, -1],
[1, 0]])
# 验证
print(R90 @ np.array([1, 0])) # [0, 1] ✓
print(R90 @ np.array([0, 1])) # [-1, 0] ✓
预期输出:
[0 1]
[-1 0]
一个矩阵由“它把基向量送到哪里”完全决定。所以矩阵不只是数字表,它是一个变换的紧凑说明书。
变换的组合 = 矩阵的乘法
先旋转 45°,再缩放 2 倍?只需要把两个矩阵相乘。
# 旋转 45°
theta = np.radians(45)
R45 = np.array([
[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]
])
# 缩放 2 倍
S2 = np.array([
[2, 0],
[0, 2]
])
# 先旋转再缩放 = S2 @ R45(注意:从右往左读!)
combined = S2 @ R45
print(f"组合变换矩阵:\n{combined.round(3)}")
# 对一个向量应用
v = np.array([1, 0])
result = combined @ v
print(f"[1, 0] → {result.round(3)}") # ≈ [1.414, 1.414]
预期输出:
组合变换矩阵:
[[ 1.414 -1.414]
[ 1.414 1.414]]
[1, 0] → [1.414 1.414]
读 S2 @ R45 @ v 时要从右往左理解:向量先旋转,再缩放。这个“最右边先执行”的规则,在后面神经网络连续矩阵运算里也会反复出现。
四、SVD——矩阵分解的"瑞士军刀"
什么是 SVD?
奇异值分解(SVD) 是特征值分解的推广——它对任意形状的矩阵都适用(不限于方阵)。
一个更适合新人的类比
你可以先把 SVD 想成:
- 把一个复杂变换拆成几个更容易理解的小动作
很像你把一个复杂机器拆开看:
- 先怎么摆正
- 再怎么拉伸
- 最后怎么放回目标方向
这也是为什么它会成为那么多 AI 方法里的底层工具:
- 因为它不只是“能算”
- 还很适合拿来解释结构
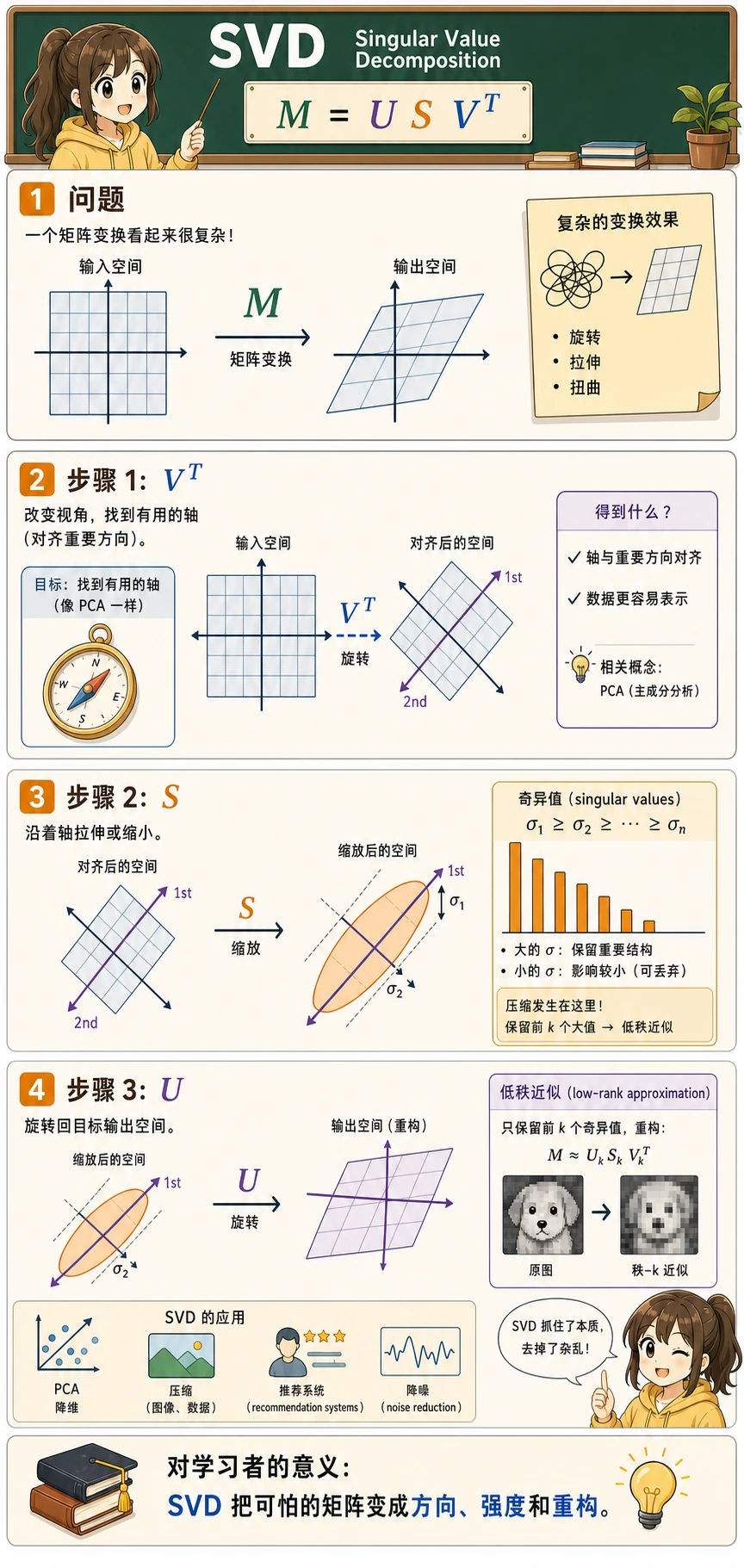
SVD 把一个矩阵 M 分解为三个矩阵的乘积:
M = U × S × V^T
其中:
- U:左奇异向量(正交矩阵)
- S:奇异值(对角矩阵,从大到小排列)
- V^T:V 的转置,也就是右奇异向量矩阵的转置
在 NumPy 里,np.linalg.svd() 返回的是 U, S, Vt。注意 S 返回的是一维奇异值列表,所以重构矩阵时通常要写 np.diag(S),先把它变成对角矩阵。
full_matrices=False 会让 NumPy 返回紧凑形式。对初学者来说,这通常最友好,因为矩阵形状可以直接对齐:
U:(行数, 奇异值个数)np.diag(S):(奇异值个数, 奇异值个数)Vt:(奇异值个数, 列数)
# 任意矩阵的 SVD
M = np.array([
[1, 2, 3],
[4, 5, 6],
]) # 2×3 矩阵
U, S, Vt = np.linalg.svd(M, full_matrices=False)
print(f"U 的形状: {U.shape}") # (2, 2)
print(f"奇异值 S: {S.round(3)}") # [9.508, 0.773]
print(f"Vt 的形状: {Vt.shape}") # (2, 3)
# 验证:M ≈ U @ diag(S) @ Vt
reconstructed = U @ np.diag(S) @ Vt
print(f"\n重构误差: {np.linalg.norm(M - reconstructed):.10f}") # ≈ 0
预期输出:
U 的形状: (2, 2)
奇异值 S: [9.508 0.773]
Vt 的形状: (2, 3)
重构误差: 0.0000000000
第一个奇异值明显大于第二个,说明这个矩阵有一个很强的主方向,以及一个较弱的修正方向。“先保留强结构,再补细节”正是 SVD 能做压缩和降维的核心原因。
SVD 的直觉
SVD 把任何变换分解为三步:
SVD 的应用:图像压缩
SVD 最直观的应用——用更少的数据近似一张图片:
# 用一张灰度图做示例
# 这里用随机数模拟一张灰度图
rng = np.random.default_rng(seed=42)
image = rng.integers(0, 256, (100, 150)).astype(float)
# 加入一些结构(不是纯随机)
for i in range(100):
for j in range(150):
image[i, j] = 128 + 50 * np.sin(i/10) * np.cos(j/15) + rng.normal() * 20
print(f"原始图片: {image.shape} = {image.size} 个值")
# SVD 分解
U, S, Vt = np.linalg.svd(image, full_matrices=False)
print(f"奇异值个数: {len(S)}")
for k in [1, 5, 20, 100]:
compressed_size = k * (U.shape[0] + 1 + Vt.shape[1])
ratio = compressed_size / image.size * 100
print(f"k={k:3d}, 存储量约为原图的 {ratio:5.1f}%")
# 用不同数量的奇异值重构
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
for ax, k in zip(axes, [1, 5, 20, 100]):
# 只保留前 k 个奇异值
reconstructed = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
# 压缩比 = 需要存储的数字数 / 原始数字数
original_size = image.size
compressed_size = k * (U.shape[0] + 1 + Vt.shape[1])
ratio = compressed_size / original_size * 100
ax.imshow(reconstructed, cmap='gray')
ax.set_title(f'k = {k}\n存储量: {ratio:.0f}%')
ax.axis('off')
plt.suptitle('SVD 图像压缩:用更少的奇异值近似', fontsize=13)
plt.tight_layout()
plt.show()
预期文本输出:
原始图片: (100, 150) = 15000 个值
奇异值个数: 100
k= 1, 存储量约为原图的 1.7%
k= 5, 存储量约为原图的 8.4%
k= 20, 存储量约为原图的 33.5%
k=100, 存储量约为原图的 167.3%
解读:只保留前 20 个奇异值,就已经可以还原图片的主要结构,同时存储数字明显变少。当 k=100 时,你保留了全部奇异值,重构效果最好,但单独存储 U、S、Vt 反而可能比直接存原图更大。所以“压缩”只有在 k 明显小于原始秩时才有意义。
SVD 在 AI 中的应用
| 应用 | 说明 |
|---|---|
| 图像压缩 | 用少量奇异值近似原始图片 |
| 推荐系统 | 矩阵分解(如 Netflix 推荐) |
| NLP | 潜在语义分析(LSA)用 SVD 对词-文档矩阵降维 |
| 数据降维 | SVD 是 PCA 的底层实现 |
| 伪逆矩阵 | 解决超定/欠定方程组 |
在真实项目里,最常问的问题通常不是“能不能完美重构”,而是:
在画面变得太糊、信息损失太大之前,我应该保留多少个重要方向?
这个问题会在模型压缩、Embedding 压缩、推荐系统和搜索系统里不断出现。
一个很适合初学者先记的判断表
| 当你看到这个词 | 先把它想成什么 |
|---|---|
| 线性无关 | 有没有信息冗余 |
| 基 | 一套最小够用的坐标系统 |
| 维度 | 这个表示到底有多少自由度 |
| 秩 | 这组数据真正有效的信息维度 |
| SVD | 把复杂矩阵拆成更容易理解的几个动作 |
这个表特别适合新人,因为它能把一串容易发虚的术语,先压缩成几句可用的直觉。
再看一个最小“低秩近似”示例
M = np.array([
[5.0, 4.8, 0.1],
[4.9, 5.1, 0.2],
[0.2, 0.1, 4.9],
])
U, S, Vt = np.linalg.svd(M, full_matrices=False)
# 只保留最大的 1 个奇异值
k = 1
Mk = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
print("原矩阵:\n", np.round(M, 3))
print("\n低秩近似:\n", np.round(Mk, 3))
print("\n重构误差:", round(np.linalg.norm(M - Mk), 4))
预期输出:
原矩阵:
[[5. 4.8 0.1]
[4.9 5.1 0.2]
[0.2 0.1 4.9]]
低秩近似:
[[4.895 4.894 0.294]
[4.997 4.997 0.3 ]
[0.297 0.297 0.018]]
重构误差: 4.8961
这个例子很适合初学者,因为它会帮助你先看到:
- SVD 不是只为了分解一个矩阵
- 它还能告诉你:如果我只保留最重要的一部分结构,会丢掉多少信息
- 如果
k太小,近似会保留最强模式,但也可能抹掉一个重要的小模式
这正是很多 AI 场景里:
- 压缩
- 降维
- 近似表示
背后的共通思想。
学到这里,下一步最值得带去哪里?
如果你已经把第 4 站读到这里,最值得带去后面的不是更多数学推导,而是这些问题:
- 这些数学对象在机器学习里到底会怎样真的用起来?
- 什么时候向量会变成特征,矩阵会变成权重?
- 为什么概率、梯度和这些线代对象会在同一个模型里一起出现?
最适合接着看的通常是:
如果你现在觉得这节还是偏抽象,最值的抓手是什么?
最值得先抓的不是所有定义细节,而是这四句:
- 线性无关 = 不冗余
- 基 = 最小够用的表示方式
- 维度 = 需要多少个坐标才能描述
- SVD = 拆开一个复杂矩阵变换
线性代数四节课,你学到了:
- 向量:AI 中的基本数据单元,余弦相似度衡量方向相似性
- 矩阵:批量变换数据,神经网络每层的核心操作
- 特征值:找到数据最重要的方向,PCA 降维
- 向量空间(本节):理解维度、基、SVD
这些概念会在后续学习机器学习、深度学习、NLP 时反复出现。不用急着记住所有细节,随着后续的实践,理解会越来越深。
小结
| 概念 | 直觉 | NumPy |
|---|---|---|
| 线性无关 | 没有冗余的向量组 | np.linalg.matrix_rank(A) |
| 基 | 描述空间的坐标系 | — |
| 维度 | 需要多少个坐标 | A.shape |
| 线性变换 | 矩阵乘法 | A @ v |
| SVD | 任意矩阵 = 旋转 × 缩放 × 旋转 | np.linalg.svd(A) |
| 矩阵的秩 | 有效维度数 | np.linalg.matrix_rank(A) |
这节最该带走什么
- 线性无关最重要的直觉是“有没有信息冗余”
- 基最重要的直觉是“最小够用的坐标系统”
- 维度最重要的直觉是“这个表示到底要多少自由度”
- SVD 最重要的直觉是“把复杂变换拆成更容易理解的几个动作”
动手练习
练习 1:判断线性无关
以下三组向量,哪组是线性无关的?用 np.linalg.matrix_rank() 验证。
# 第 1 组
g1 = np.array([[1, 2], [3, 6]])
# 第 2 组
g2 = np.array([[1, 0], [0, 1]])
# 第 3 组
g3 = np.array([[1, 2, 3], [4, 5, 6], [5, 7, 9]])
for name, matrix in {"g1": g1, "g2": g2, "g3": g3}.items():
rank = np.linalg.matrix_rank(matrix)
dimension = matrix.shape[0]
print(f"{name}: rank={rank}, dimension={dimension}, independent={rank == dimension}")
预期输出:
g1: rank=1, dimension=2, independent=False
g2: rank=2, dimension=2, independent=True
g3: rank=2, dimension=3, independent=False
练习 2:SVD 压缩
用 SVD 对一个 50×80 随机矩阵做低秩近似,画出不同 k 值下的重构误差曲线。
rng = np.random.default_rng(seed=42)
M = rng.normal(size=(50, 80))
U, S, Vt = np.linalg.svd(M, full_matrices=False)
errors = []
for k in range(1, 51):
reconstructed = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
error = np.linalg.norm(M - reconstructed)
errors.append(error)
plt.plot(range(1, 51), errors, marker="o")
plt.xlabel("k:保留的奇异值个数")
plt.ylabel("重构误差")
plt.title("SVD 重构误差会随 k 增大而下降")
plt.grid(alpha=0.3)
plt.show()
预期结果:曲线整体向下。保留的奇异值越多,保留的信息越多,重构误差越小。
练习 3:变换组合
构造两个 2×2 变换矩阵——先缩放 (x 放大 2 倍, y 不变),再旋转 30°。把它们相乘得到组合矩阵,对一组三角形顶点做变换并画图。
theta = np.radians(30)
scale = np.array([[2, 0], [0, 1]])
rotate = np.array([
[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)],
])
# 先缩放,再旋转:最右边的操作先发生。
combined = rotate @ scale
triangle = np.array([
[0, 0],
[1, 0],
[0.5, 1],
[0, 0],
])
transformed = triangle @ combined.T
print("组合矩阵:\n", np.round(combined, 3))
print("变换后的顶点:\n", np.round(transformed, 3))
plt.plot(triangle[:, 0], triangle[:, 1], "o-", label="原始三角形")
plt.plot(transformed[:, 0], transformed[:, 1], "o-", label="变换后三角形")
plt.axis("equal")
plt.grid(alpha=0.3)
plt.legend()
plt.show()
预期文本输出:
组合矩阵:
[[ 1.732 -0.5 ]
[ 1. 0.866]]
变换后的顶点:
[[0. 0. ]
[1.732 1. ]
[0.366 1.366]
[0. 0. ]]