4.3.1 微积分路线图:模型如何通过降低损失来学习
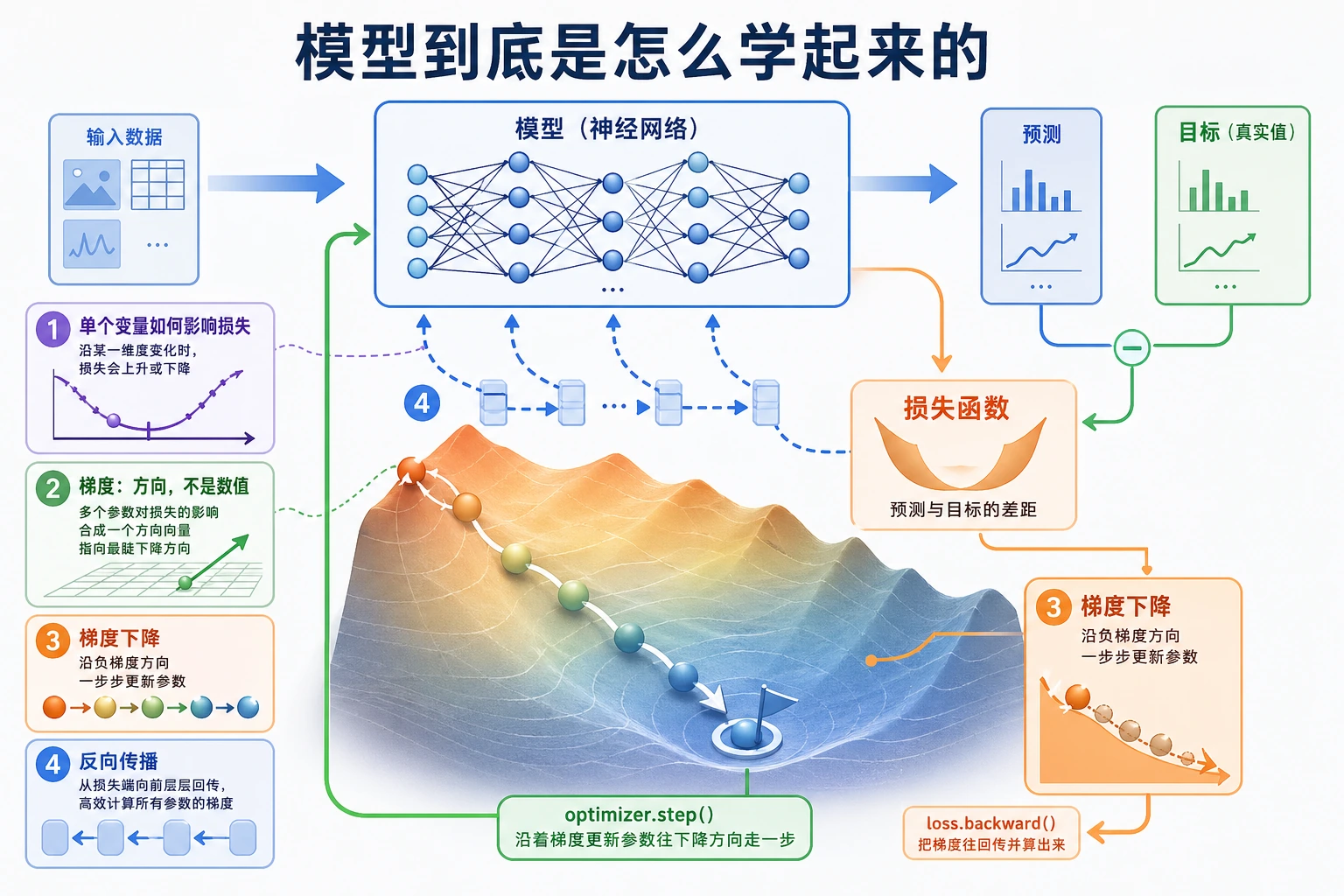
微积分解释模型怎样调整参数。第一目标是建立直觉:衡量变化,朝更好的方向移动,然后重复。
先看地图
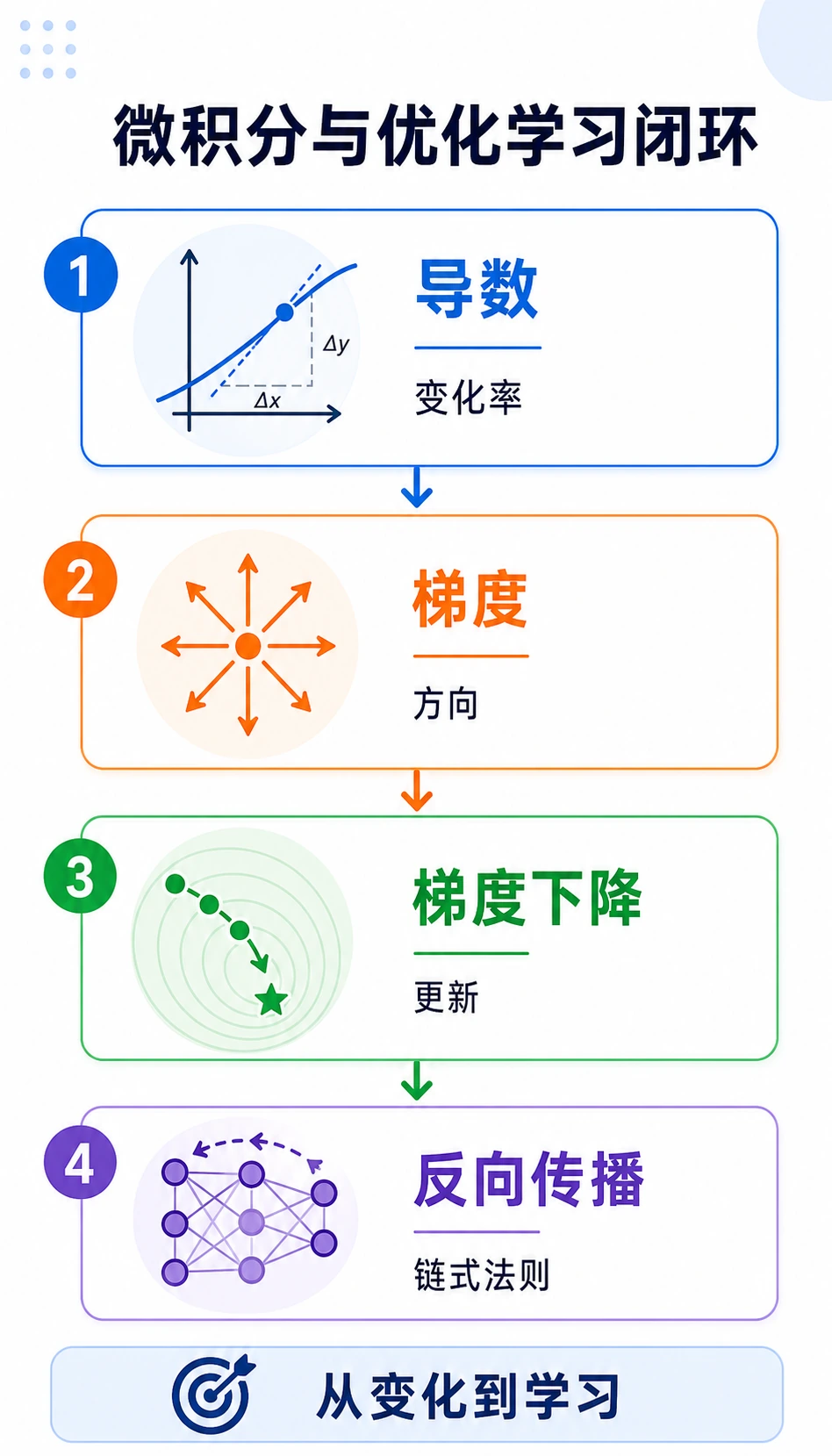
训练流向是:
| 概念 | 在 AI 里的第一层意思 |
|---|---|
| 导数 | 一个值变化有多快 |
| 梯度 | 多个参数应该怎样一起变 |
| 梯度下降 | 朝更小 loss 更新参数 |
| 链式法则 | 把多步变化连接起来 |
| 反向传播 | 高效计算大量梯度 |
以后看到 loss.backward() 和 optimizer.step(),背后就是这一章。
跑最小闭环
创建 gradient_descent_first_loop.py。它通过降低 (w - 3)^2,让数字靠近 3。
w = 0.0
learning_rate = 0.2
for step in range(1, 7):
gradient = 2 * (w - 3)
w = w - learning_rate * gradient
loss = (w - 3) ** 2
print(step, "w=", round(w, 3), "loss=", round(loss, 3))
预期输出:
1 w= 1.2 loss= 3.24
2 w= 1.92 loss= 1.166
3 w= 2.352 loss= 0.42
4 w= 2.611 loss= 0.151
5 w= 2.767 loss= 0.054
6 w= 2.86 loss= 0.02
数字会靠近 3,loss 会变小。神经网络变大之前,训练思想就是这个。
按这个顺序学
| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 4.3.2 导数 | 变化率 |
| 2 | 4.3.3 偏导数与梯度 | 多个参数一起变化 |
| 3 | 4.3.4 梯度下降 | 更新循环、学习率、loss 曲线 |
| 4 | 4.3.5 反向传播 | 链式法则、loss.backward() 直觉 |
通过标准
能解释梯度下降为什么反复执行“计算 loss -> 计算梯度 -> 更新参数”,并知道学习率太大会让训练不稳定,就算通过。