4.3.1 微積分ロードマップ:モデルは損失を下げながら学ぶ
微積分は、モデルがパラメータをどう変えるかを説明します。最初の目標は直感です。変化を測り、より良い方向へ動かし、繰り返します。
まずマップを見る
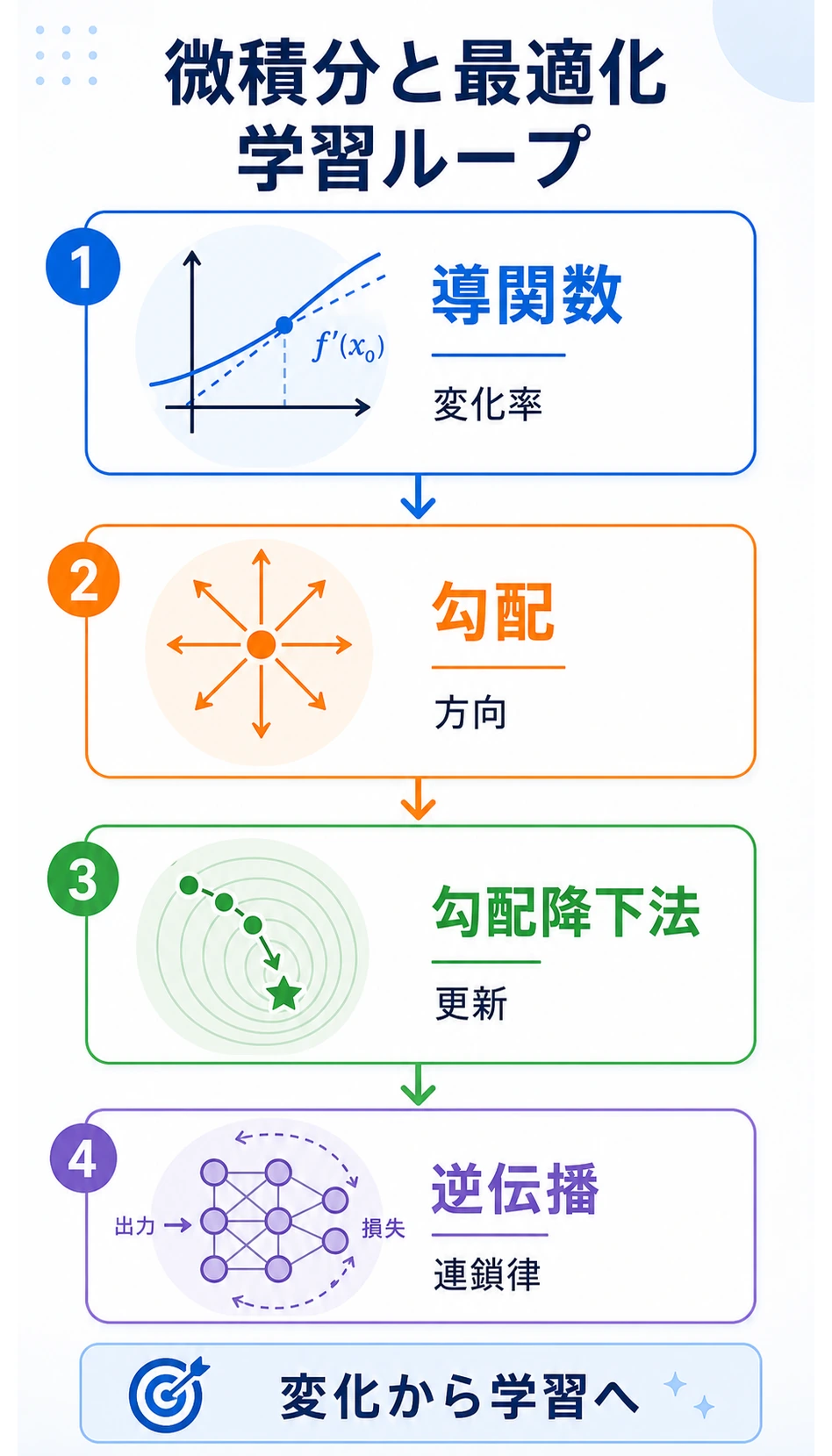
学習の流れです。
| 概念 | AI での最初の意味 |
|---|---|
| 導関数 | 1つの値がどれくらい速く変わるか |
| 勾配 | 多くのパラメータをどの向きに変えるか |
| 勾配降下 | より小さい loss へ向けてパラメータを更新する |
| 連鎖律 | 複数ステップの変化をつなぐ |
| バックプロパゲーション | 多くの勾配を効率よく計算する |
後で loss.backward() と optimizer.step() を見たとき、この章が背景になります。
最小ループを動かす
gradient_descent_first_loop.py を作ります。(w - 3)^2 を小さくしながら、数値を 3 に近づけます。
w = 0.0
learning_rate = 0.2
for step in range(1, 7):
gradient = 2 * (w - 3)
w = w - learning_rate * gradient
loss = (w - 3) ** 2
print(step, "w=", round(w, 3), "loss=", round(loss, 3))
出力:
1 w= 1.2 loss= 3.24
2 w= 1.92 loss= 1.166
3 w= 2.352 loss= 0.42
4 w= 2.611 loss= 0.151
5 w= 2.767 loss= 0.054
6 w= 2.86 loss= 0.02
数値は 3 に近づき、loss は小さくなります。ニューラルネットワークが大きくなる前の学習イメージはこれです。
この順番で学ぶ
| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 4.3.2 導関数 | 変化率 |
| 2 | 4.3.3 偏導関数と勾配 | 複数のパラメータが一緒に変わる |
| 3 | 4.3.4 勾配降下 | 更新ループ、学習率、loss 曲線 |
| 4 | 4.3.5 バックプロパゲーション | 連鎖律、loss.backward() の直感 |
合格ライン
勾配降下がなぜ「loss を計算 -> 勾配を計算 -> パラメータを更新」を繰り返すのか、そして学習率が大きすぎるとなぜ不安定になるのかを説明できれば合格です。