4.2.6 確率統計の歴史的な流れ:Bayes、MLE、EM と情報理論
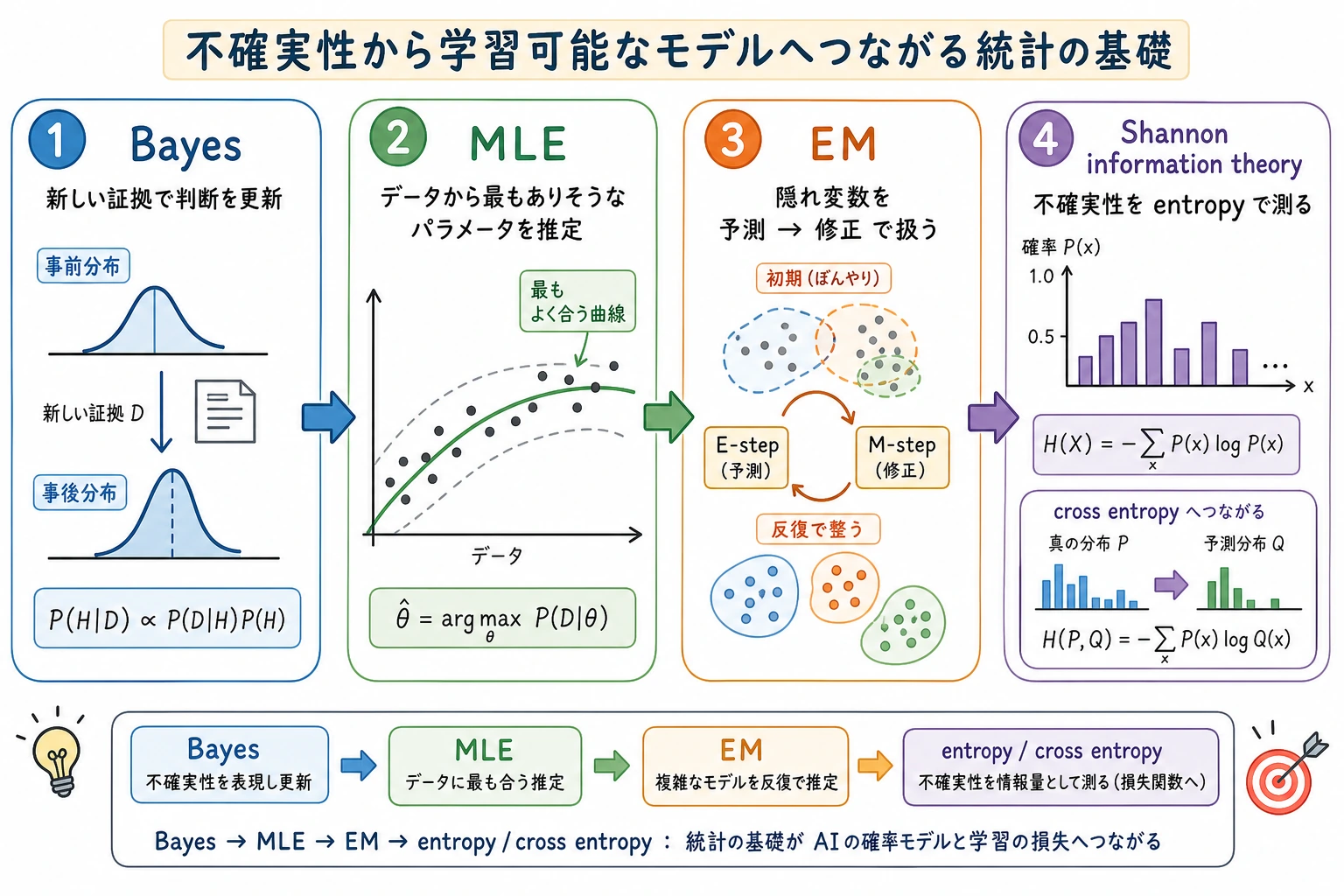
この節は、歴史を追加で暗記するためのものではなく、確率統計の中で最もバラバラになりやすい概念を1本につなぐためのものです。
まずは次の1文だけ覚えておけば十分です。
Bayes は判断を証拠で更新できるようにし、MLE はパラメータをデータから逆算できるようにし、EM は隠れた情報がある問題でも反復で近づけるようにし、Shannon は不確実性を測れるようにした。
一、なぜ、こうした古い概念が今でも AI で何度も出てくるのか?
AI モデルはとても現代的に見えますが、その土台ではずっと3つの古い問題を扱っています。
| 古い問題 | 対応する考え方 | 今どこに出てくるか |
|---|---|---|
| 新しい証拠が来たら、判断は変えるべき? | ベイズの法則 | 分類確率、診断システム、推薦システム、RAG の信頼度 |
| 誰もパラメータを教えてくれないとき、データからどう推測する? | 最尤推定 MLE | 損失関数、ロジスティック回帰、言語モデルの学習 |
| いくつかの変数が見えなくても、パラメータは推定できる? | EM アルゴリズム | クラスタリング、トピックモデル、潜在変数モデル |
| 予測はどれくらい不確実なのか? | 情報理論 | エントロピー、交差エントロピー、KL ダイバージェンス、分類 loss |
つまり、これらの節目は「数学の古い遺物」ではなく、多くの現代アルゴリズムで今も使われている土台の言葉なのです。
二、Bayes:新しい証拠が来たら、判断を更新する
ベイズの法則は、「探偵が判断を更新する」イメージで考えると分かりやすいです。
最初に持っている初期判断を先験的な確率(事前確率)と呼びます。そこに新しい証拠が入ったら、判断を更新して事後確率にします。
事前の判断 + 新しい証拠 -> 更新後の判断
AI のプロジェクトでは、この感覚はとてもよく出てきます。
- スパム判定: キーワードを見たあとで、メールがスパムである確率は変わるか?
- 医療の補助判断: 新しい検査結果を見たあとで、ある病気の可能性は変わるか?
- RAG の質問応答: 検索された証拠は十分強いか、それとも「不確実です」と答えるべきか?
ベイズの法則で一番大事なのは、数式がどう見えるかではなく、この習慣です。
最初の見た目の判断を最終結論だと思わないこと。証拠は確率を変える。
三、MLE:データから最もありそうなパラメータを逆算する
最尤推定が答えるのは、別の問いです。
データはすでに起きたとして、どのパラメータの組み合わせが、そのデータを生み出したように最も見えるか?
MLE は「事件を逆からたどる」ものだと思うと理解しやすいです。
| 探偵の話 | 統計的推論 |
|---|---|
| 現場に痕跡が残っている | データを観測している |
| 本当に何が起きたかは分からない | 真のパラメータは分からない |
| 痕跡を最もうまく説明する話を探す | データを最もうまく説明するパラメータを探す |
最小の例はコイン投げです。10回投げて、8回が表だったとします。
このとき、表の確率 p はどれくらいが最もありそうでしょうか?
直感的には p = 0.8 です。
MLE は、これを数学として扱います。
import numpy as np
heads = 8
tails = 2
p_values = np.linspace(0.01, 0.99, 99)
likelihood = p_values**heads * (1 - p_values)**tails
p_mle = p_values[np.argmax(likelihood)]
print(round(p_mle, 2))
この考え方は、第5章のロジスティック回帰、第6章の交差エントロピー、第7章の言語モデルの学習で何度も出てきます。
四、EM:見えない変数も、まず推測してから修正できる
EM アルゴリズムは、もっとやっかいな状況を扱います。
データに影響する一部の原因が隠れているときでも、パラメータは推定できるのか?
たとえば、たくさんのユーザー行動データがあっても、ユーザーが裏でどのタイプの集団に属しているのかは分からないことがあります。あるいは、たくさんのテキストがあっても、各文書の潜在トピックが何かは分かりません。
EM の直感は、2つのステップをくり返す流れです。
| ステップ | 何をするか | たとえ |
|---|---|---|
| E-step | まず現在のパラメータにもとづいて、隠れ変数が何かを推測する | 「この手がかりはどの容疑者に属するか」を先に考える |
| M-step | 次に、推測した隠れ変数を使ってパラメータを更新する | 新しいグループ分けから、各容疑者の特徴を再計算する |
隠れた情報を推測する -> パラメータを更新する -> もう一度推測する -> さらに更新する
これは、初心者にとってとても大事なことを教えてくれます。
すべての学習が一度で答えを出せるわけではない。多くのモデルは、不完全な情報の中で反復しながら近づいていく。
五、Shannon:不確実性も計算できる
1948年、Shannon の情報理論は、「情報量」と「エントロピー」を計算できるものにしました。
これは AI にとって非常に重要です。なぜなら、モデルの学習では次のようなことを常に考えるからです。
- 予測分布はどれくらい乱れているか?
- モデルの予測と正解ラベルはどれくらい違うか?
- どの token がより意外か?
たとえば分類タスクの交差エントロピーは、次のように理解できます。
モデルが自分の確率分布で正解を説明しようとするとき、どれくらいの情報コストがかかったか。
だから、深層学習では次のような式を何度も目にするのです。
loss = cross_entropy(prediction, label)
見た目は単なる loss ですが、その背景には情報理論がつながっています。
六、歴史の節目を各章に対応させる
| 歴史の節目 | 初心者がまず理解する一文 | 対応する章 |
|---|---|---|
| ベイズの法則 | 新しい証拠で判断は更新される | 2.2 確率の基礎、5.1 機械学習の基礎 |
| 最尤推定 | データを最もうまく説明するパラメータを探す | 2.4 統計的推論、5.2 教師あり学習 |
| EM アルゴリズム | 隠れ変数があるときは、まず推測してから修正する | 2.4 統計的推論、5.3 教師なし学習 |
| Shannon 情報理論 | 不確実性は測定できる | 2.5 情報理論、6.2 PyTorch loss |
| MCMC / ベイズ推論 | 複雑な事後分布はサンプリングで近似できる | 発展選択、確率的推論の背景 |
| Pearl の因果 | 相関は因果ではない | 第3章 データ分析、第9章 意思決定システムの背景 |
七、この節を学び終えたときに身につけたい直感
この歴史の流れは、AI における「判断の言葉」を身につける助けになります。
- Bayes は、判断は証拠によって変わると教えてくれる
- MLE は、学習はデータからパラメータを逆算する見方だと教えてくれる
- EM は、隠れた情報は反復で近づけられると教えてくれる
- Shannon は、不確実性、誤り、情報の差を数値化できると教えてくれる
今後 probability、likelihood、entropy、cross entropy、KL divergence を見たときは、ただの公式だと思わないでください。
その背景では、どれも同じ問いに答えています。
不確実な世界で、モデルはどうやって計算可能で、更新可能で、最適化可能な判断をするのか?