概率统计历史主线:Bayes、MLE、EM 与信息论
这一节不是额外背历史,而是帮你把概率统计里最容易散掉的概念串起来。
你只需要先记住一句话:
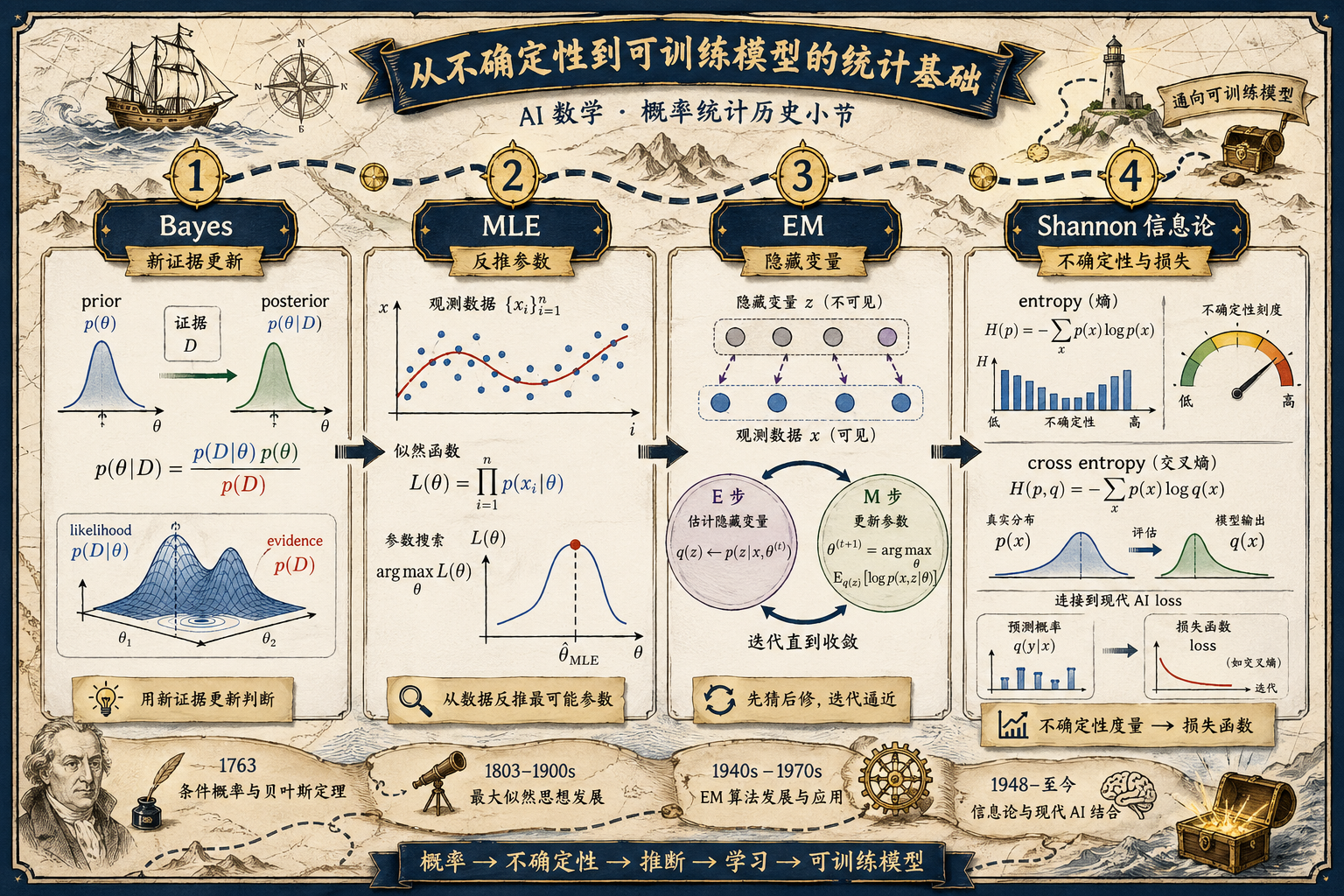
Bayes 让判断可以随证据更新,MLE 让参数可以从数据里反推,EM 让有隐藏信息的问题也能迭代逼近,Shannon 让不确定性可以被度量。
一、为什么这些老概念今天还在 AI 里反复出现?
AI 模型看起来很现代,但底层一直在处理三个老问题:
| 老问题 | 对应思想 | 今天在哪里出现 |
|---|---|---|
| 新证据来了,判断要不要变? | 贝叶斯法则 | 分类概率、诊断系统、推荐系统、RAG 置信度 |
| 参数��没人告诉我,怎样从数据里猜? | 最大似然估计 MLE | 损失函数、逻辑回归、语言模型训练 |
| 有些变量看不见,还能不能估计参数? | EM 算法 | 聚类、主题模型、隐变量模型 |
| 预测到底有多不确定? | 信息论 | 熵、交叉熵、KL 散度、分类 loss |
所以这几个节点不是“数学课的古董”,而是很多现代算法仍在使用的底层语言。
二、Bayes:新证据来了,判断要更新
贝叶斯法则最适合用“侦探更新判断”来理解。
一开始你有一个初始判断,叫先验。后来看到新证据,就要把判断更新成后验。
先验判断 + 新证据 -> 更新后的判断
在 AI 项目里,这个直觉特别常见:
- 垃圾邮件检测:看到关键词后,邮件是垃圾邮件的概率变了吗?
- 医疗辅助判断:看到新的检测结果后,某种疾病的可能性变了吗?
- RAG 问答:检索证据足够强吗,还是应该回答“不确定”?
贝叶斯法则最重要的不是公式长什么样,而是这个习惯:
不要把第一眼判断当成终局,证据会改变概率。
三、MLE:从数据倒推最可能的参数
最大似然估计回答的是另一个问题:
如果数据已经发生了,哪一组参数最像能生成这些数据?
可以把 MLE 想成“反推案情”:
| 侦探故事 | 统计推断 |
|---|---|
| 现场留下了痕迹 | 我们观察到了数据 |
| 不知道真正发生了什么 | 不知道真实参数 |
| 找最能解释痕迹的故事 | 找最能解释数据的参数 |
一个最小例子是抛硬币。你抛了 10 次,8 次正面。
那正面概率 p 最可能是多少?
直觉上是 p = 0.8。
MLE 做的就是把这件事数学化:
import numpy as np
heads = 8
tails = 2
p_values = np.linspace(0.01, 0.99, 99)
likelihood = p_values**heads * (1 - p_values)**tails
p_mle = p_values[np.argmax(likelihood)]
print(round(p_mle, 2))
这个思想会在第 5 章逻辑回归、第 6 章交叉熵、第 7 章语言模型训练中反复出现。
四、EM:看不见的变量,也可以先猜再修
EM 算法解决的是更麻烦的情况:
如果影响数据的某些原因是隐藏的,参数还能不能估计?
比如你看到一堆用户行为数据,但不知道用户背后属于哪类人群;或者看到一堆文本,但不知道每篇文章潜在主题是什么。
EM 的直觉像两步循环:
| 步骤 | 在做什么 | 类比 |
|---|---|---|
| E-step | 先根据当前参数,猜隐藏变量可能是什么 | 先猜“这条线索属于哪个嫌疑人” |
| M-step | 再根据猜出来的隐藏变量,更新参数 | 根据新分组重算每个嫌疑人的特征 |
先猜隐藏信息 -> 更新参数 -> 再猜隐藏信息 -> 再更新参数
它告诉新人一件很重要的事:
不是所有训练都能一步算出答案,很多模型是在不完整信息里迭代逼近。
五、Shannon:不确定性也能被计算
1948 年,Shannon 的信息论把“信�息量”和“熵”变成了可以计算的东西。
这对 AI 很关键,因为模型训练经常在问:
- 预测分布有多乱?
- 模型预测和真实标签差多远?
- 哪个 token 更意外?
例如分类任务里的交叉熵,就可以理解为:
模型用自己的概率分布去解释真实答案时,付出了多少信息代价。
这也是为什么你会在深度学习里不断看到:
loss = cross_entropy(prediction, label)
它表面是一个 loss,背后连着信息论。
六、把历史节点分配到课程章节
| 历史节点 | 新人先懂哪句话 | 对应课程章节 |
|---|---|---|
| 贝叶斯法则 | 新证据会更新判断 | 2.2 概率基础、5.1 机器学习基础 |
| 最大似然估计 | 找最能解释数据的参数 | 2.4 统计推断、5.2 监督学习 |
| EM 算法 | 有隐藏变量时先猜再修 | 2.4 统计推断、5.3 无监督学习 |
| Shannon 信息论 | 不确定性可以被度量 | 2.5 信息论、6.2 PyTorch loss |
| MCMC / 贝叶斯推断 | 复杂后验可以用采样近似 | 选修扩展、概率推断背景 |
| Pearl 因果 | 相关不等于因果 | 第 3 章数据分析、第 9 章决策系统背景 |
七、学完这一节应该形成的直觉
这几条历史线其实在帮你建立 AI 的“判断语言”:
- Bayes 让你知道:判断会随证据变化
- MLE 让你知道:训练可以看成从数据反推参数
- EM 让你知道:隐藏信息可以通过迭代逼近
- Shannon 让你知道:不确定性、错误和信息差可以量化
当你以后看到 probability、likelihood、entropy、cross entropy、KL divergence 时,不要只把它们看成公式。
它们背后都在回答同一个问题:
在不确定的世界里,模型怎样做出可计算、可更新、可优化的判断?